
深入理解JVM垃圾回收機制 1、垃圾回收需要解決的問題及解決的辦法總覽 + 1、如何判定對象為垃圾對象 引用計數法 可達性分析法 + 2、如何回收 回收策略 標記 清除演算法 複製演算法 標記 整理演算法 分帶收集演算法 垃圾回收器 serial parnew Cms G1 + 3、何時回收 下麵就是如何判 ...
深入理解JVM垃圾回收機制
1、垃圾回收需要解決的問題及解決的辦法總覽
- 1、如何判定對象為垃圾對象
- 引用計數法
- 可達性分析法
- 2、如何回收
- 回收策略
- 標記-清除演算法
- 複製演算法
- 標記-整理演算法
- 分帶收集演算法
- 垃圾回收器
- serial
- parnew
- Cms
- G1
- 回收策略
- 3、何時回收
下麵就是如何判定對象為垃圾對象
***
2、引用計數法
在對象中添加一個引用計數器,當有地方引用這個對象的時候,引用技術器得值就+1,當引用失效的時候,計數器得值就-1
演算法缺點:當某個引用被收集時,下個引用並不會清0,因此不被回收造成記憶體泄露。
下麵我們運行實例代碼來看,JVM在迴圈引用時,是否能被收集(如果回收了就說明垃圾回收器用的不是引用計數法)。
如果想列印日誌信息,請填入如下參數。
-verbose:gc -XX:+PrintGCDetails 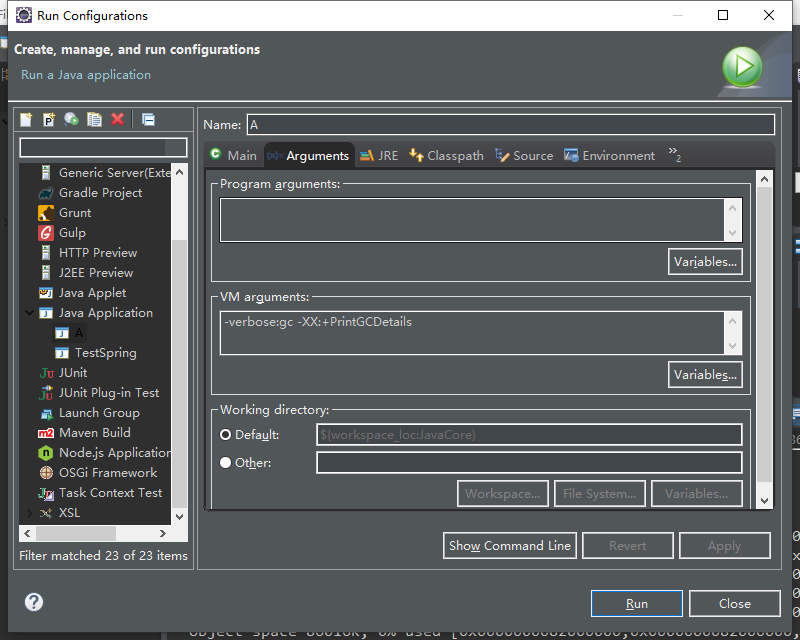
其中我們需要將每個對象的所占記憶體擴大,因此我們聲明一個大點的空間。
測試實驗代碼如下:
public class A {
private Object instance;
public A() {
byte[] m = new byte[20*1024*1024];
}
public static void main(String[] args) {
A a1 = new A();
A a2 = new A();
a1.instance=a2;
a2.instance=a1;
a1=null;
a2=null;
System.gc();
//parallel 預設採用的垃圾回收器
}
}
運行結果如下所示:
[GC (System.gc()) [PSYoungGen: 22446K->648K(37888K)] 42926K->21136K(123904K), 0.0011193 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (System.gc()) [PSYoungGen: 648K->0K(37888K)] [ParOldGen: 20488K->519K(86016K)] 21136K->519K(123904K), [Metaspace: 2632K->2632K(1056768K)], 0.0074751 secs] [Times: user=0.02 sys=0.00, real=0.01 secs]
Heap
PSYoungGen total 37888K, used 328K [0x00000000d6000000, 0x00000000d8a00000, 0x0000000100000000)
eden space 32768K, 1% used [0x00000000d6000000,0x00000000d6052030,0x00000000d8000000)
from space 5120K, 0% used [0x00000000d8000000,0x00000000d8000000,0x00000000d8500000)
to space 5120K, 0% used [0x00000000d8500000,0x00000000d8500000,0x00000000d8a00000)
ParOldGen total 86016K, used 519K [0x0000000082000000, 0x0000000087400000, 0x00000000d6000000)
object space 86016K, 0% used [0x0000000082000000,0x0000000082081fd8,0x0000000087400000)
Metaspace used 2638K, capacity 4486K, committed 4864K, reserved 1056768K
class space used 281K, capacity 386K, committed 512K, reserved 1048576K
這裡我們會看到 22446K->648J這裡,我們的對象被回收了,這就說明我們JVM採用的垃圾回收演算法並不是引用計數法。
3、可達性分析法
演算法如名,可達性分析法就是從GCroot結點開始,看能否找到對象。
GCroot結點開始向下搜索,路徑稱為引用鏈,當對象沒有任何一條引用鏈鏈接的時候,就認為這個對象是垃圾,併進行回收。
那麼什麼是GCroot呢(虛擬機在哪查找GCroot)。
- 虛擬機棧(局部變數表)
- 方法區的類屬性所引用的對象。
- 方法區中常量所引用的對象。
- 本地方法棧中引用的對象。
目前主流JVM採用的垃圾判定演算法就是可達性分析法。
至此垃圾判定演算法結束
垃圾回收演算法開始
4、標記-清除演算法
存在的問題:
- 效率問題。
- 記憶體小塊過多。
如圖所示:黃色的就是被標記清除的。清除後會發現有很多多餘的小塊。
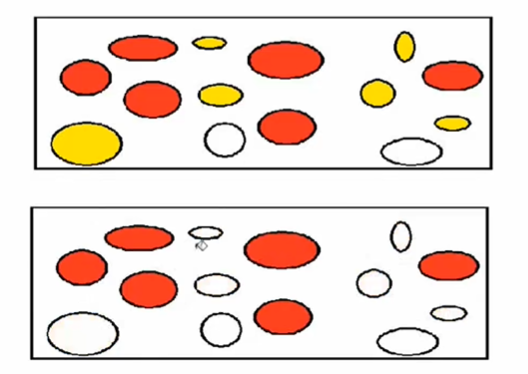
5、複製演算法
下麵是java記憶體常規劃分
- (線程共有)堆記憶體 方法區
- (棧記憶體 本地方法棧) 程式計數器
下麵是堆記憶體的劃分
- 新生代
- Eden 伊甸園
- Survivor 存活區
- Tenured Gen 養老區
- 老年代
下麵就是過程:
被標記的黑色就是需要回收的
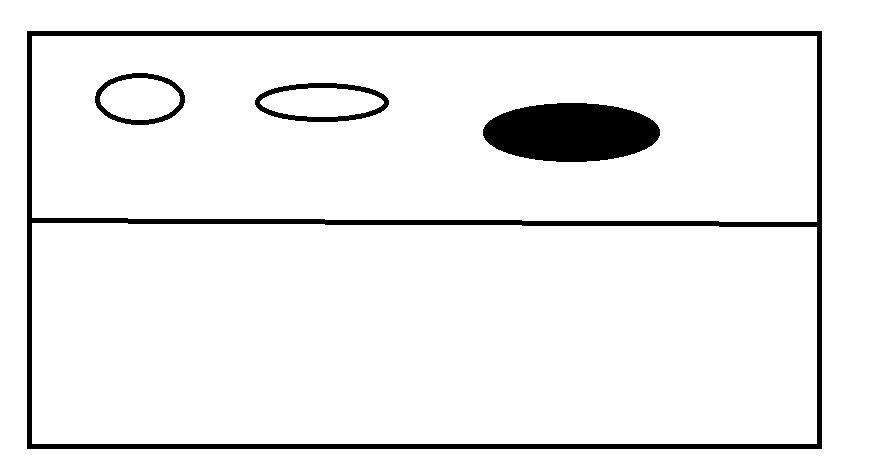
將白色區域複製下麵,然後清空上面的
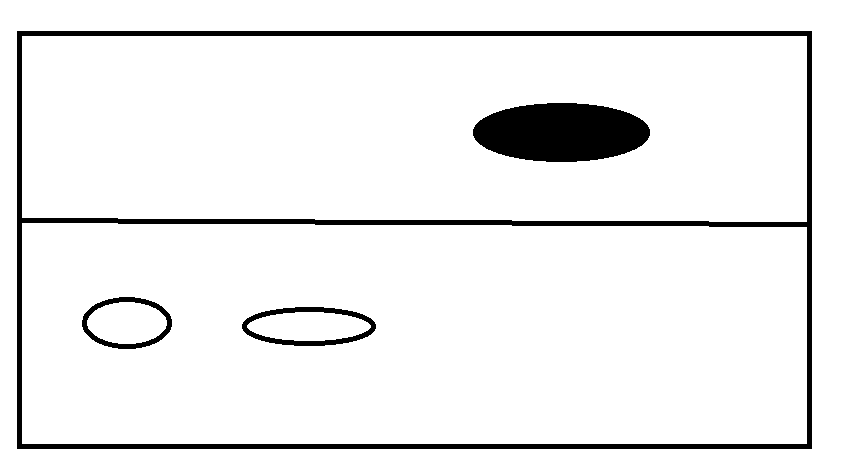
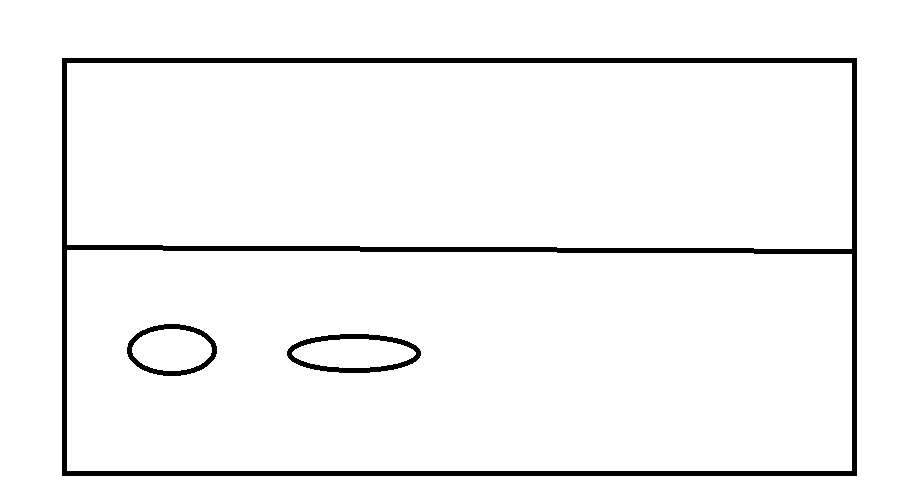
這樣就完成了記憶體的連續分配,但是引來一個問題。
每次只能使用一半的記憶體。是不是有點少。。
為瞭解決這個問題,我們對記憶體就進行了劃分。
我們對記憶體分為了三塊區域。

| 記憶體區域 | 所占百分比 |
|---|---|
| Eden | 80% |
| survivor | 10% |
| Tenured Gen | 一點點 |
複製演算法,我們需要將上面的思路,將Eden中需要回收的對象放到Survivor,然後清除。
也就是倆個Survivor中進行複製與清除。
這裡我們即提高了效率,又減少了記憶體分配。
如果Survivor不夠放,那就扔到老年代里,或者其他方法,反正有記憶體擔保。
6、標記-整理演算法
複製演算法主要針對新生代記憶體收集方法。
標記-整理演算法主要針對的是老年代記憶體收集方法。
主要步驟:標記-整理-清除
如下圖所示

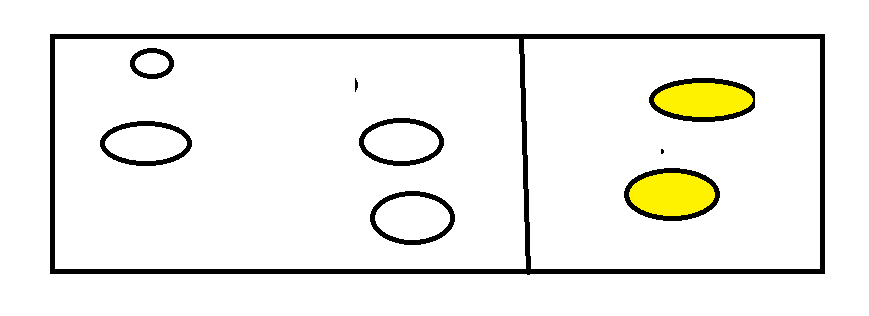
然後將右面的進行刪除計科達到回收效果。
7、分代收集演算法
分代收集演算法是根據記憶體的分代選擇不同的演算法。
對於新生代,一般選擇複製演算法。
對於老年代,一般選擇標記-整理-清除演算法。
顯而易見,這是上面倆種演算法的優點糅合在一起的應用。
至此我們總結了所有垃圾回收演算法。
下麵就是各種出名的垃圾收集器
8、Serial收集器
特點:
- 出現的最早的,發展最悠久的垃圾收集器。
- 單線程垃圾收集器。
- 主要針對新生代記憶體進行收集
運行機制如下所示
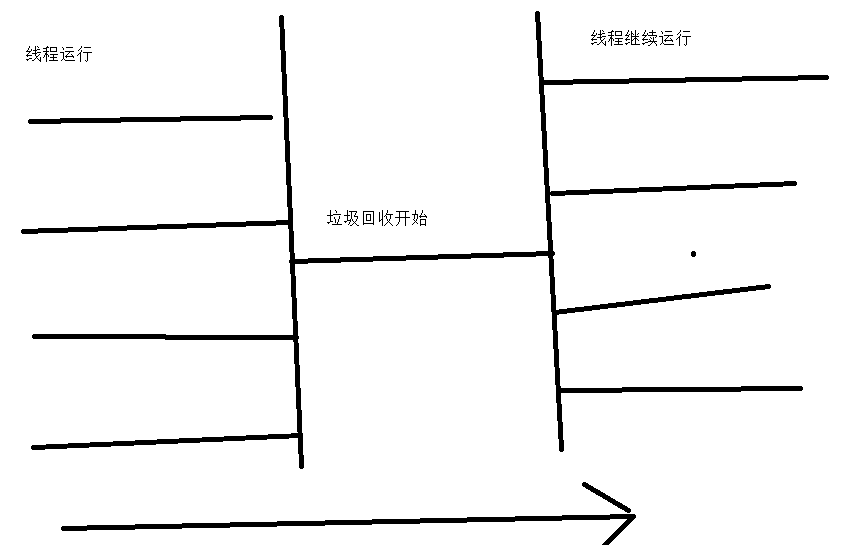
缺點:慢
用處:在客戶端上運行還是比較有效。沒有線程的開銷,所以在客戶端還是比較好用的。
9、ParNew收集器
特點:
- 由單線程變成了多線程垃圾收集器。
- 如果要用CMS進行收集的話,最好採用ParNew收集器。
實現原理都是複製演算法。
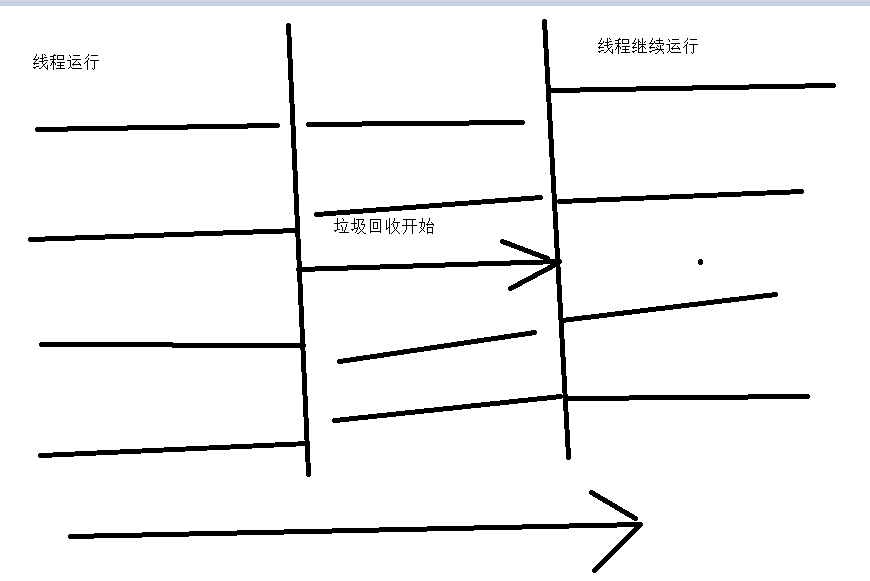
缺點:
- 性能較慢
10、Parallel Scavenge 收集器
主用演算法:複製演算法(新生代收集器)
吞吐量 = (執行用戶代碼消耗的時間)/(執行用戶代碼的時間)+ 垃圾回收時所占用的時間
優點:吞吐量優化(CPU用於運行用戶代碼的時間與CPU消耗的總時間的比值)
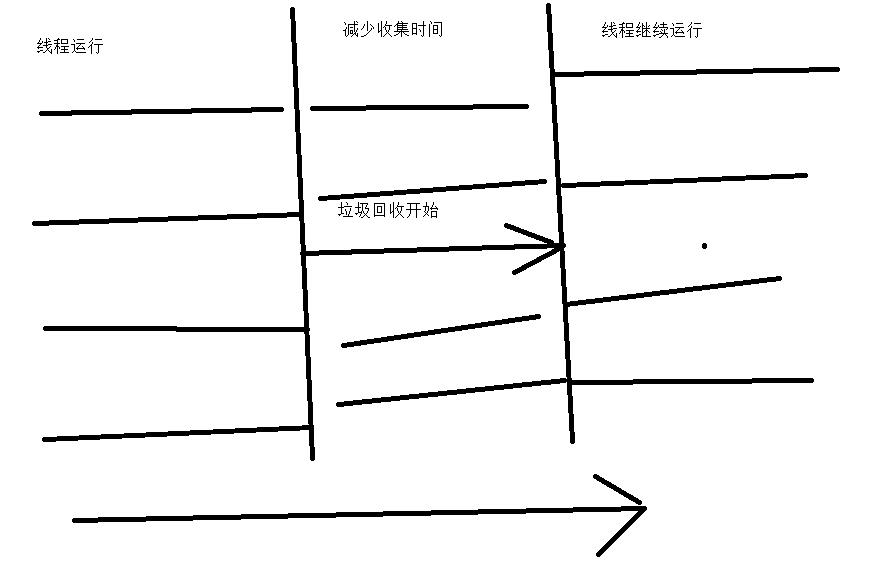
關於控制吞吐量的參數如下
-XX:MaxGCPauseMills #垃圾收集器的停頓時間
-XX:GCTimeRatio #吞吐量大小
當停頓時間過小時,記憶體對應變小,回收的頻率增大。因此第一個參數需要設置的合理才比較好。
第二個參數值越大,吞吐量越大,預設是99,(垃圾回收時間最多只能占到1%)
總的來說:客戶端可用,服務端最好不用。
11、CMS收集器(Concurrent Mark Sweep)
採用演算法:標記清除演算法。
- 工作過程:
- 初始標記
- 併發標記
- 重新標記
- 併發清理
- 優點:
- 併發收集
- 低停頓
- 缺點:
- 占用大量的CPU資源
- 無法處理浮動垃圾
- 出現ConcurrentMode Failure
- 空間碎片
CMS是一個併發的收集器。
目標是:減少延遲,增加響應速度
執行效果如下所示:
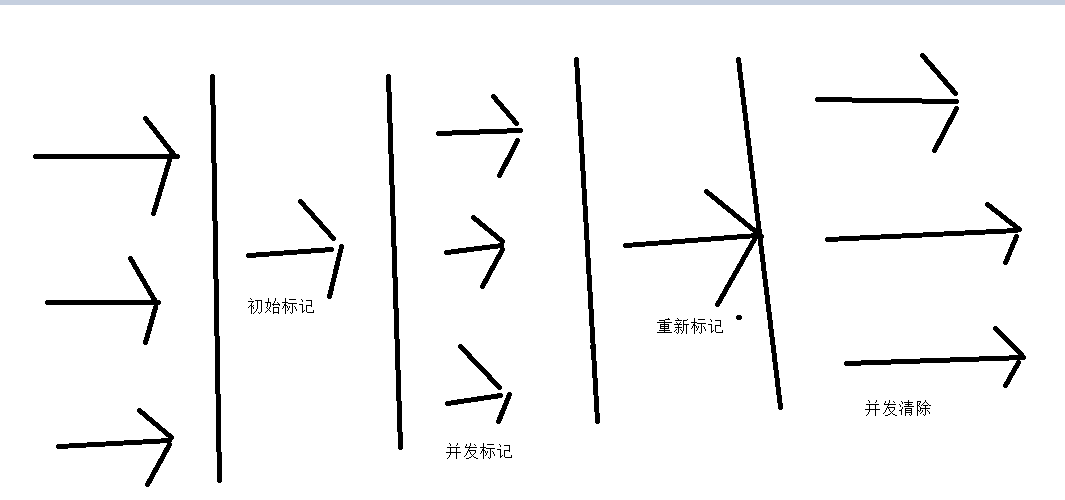
- 初始標記
- 可達性分析法
- 重新標記
- 為了修正併發期間,因對象重新運作而修正
- 併發清理
- 直接清除了
12、G1收集器(面向服務端)
最牛的垃圾收集器。
- 歷史
-2004年Sun發表了第一篇G1的論文,到2006年左右,在JDK6內集成進去了。JDK7才放出來。 - 優勢
- 集中了前面所有收集器的優點
- G1能充分利用了多核的並行特點,能縮短停頓時間。
- 分代收集(分成各種Region)
- 空間整合(類似於標記清理演算法)
- 可預測的停頓()。
- 步驟
- 初始標記
- 併發標記
- 最終標記
- 篩選回收
13、小結:
至此我們就已經掌握了大部分GC的知識。這可不是一個小工程,希望要好好吸收知識。。


