
網路通信模塊是分散式系統中最底層的模塊,他直接支撐了上層分散式環境下複雜的進程間通信邏輯,是所有分散式系統的基礎。遠程過程調用(RPC)是一種常用的分散式網路通信協議,他允許運行於一臺電腦的程式調用另一臺電腦的子程式,同時將網路的通信細節隱藏起來,使得用戶無需額外地為這個交互作用編程,大大的簡化 ...
網路通信模塊是分散式系統中最底層的模塊,他直接支撐了上層分散式環境下複雜的進程間通信邏輯,是所有分散式系統的基礎。遠程過程調用(RPC)是一種常用的分散式網路通信協議,他允許運行於一臺電腦的程式調用另一臺電腦的子程式,同時將網路的通信細節隱藏起來,使得用戶無需額外地為這個交互作用編程,大大的簡化了分散式程式開發 作為一個分散式文件系統,Hadoop實現了自己的RPC通信協議,他是上層多個分散式子系統(MapReduce,Yarn,HDFS等)公用的網路通信模塊
目錄 一. RPC通信模型 二. Hadoop RPC的特點概述 三. RPC總體架構 四. Hadoop RPC使用方法 五. Hadoop RPC類詳解 六. Hadoop RPC參數調優
一. RPC通信模型 RPC是一種提供網路從遠程電腦上請求服務,但不需要瞭解底層網路技術的協議 RPC通常採用客戶機/伺服器模型。請求程式是一個客戶機,而服務提供程式則是一個伺服器。一個典型的RPC框架,主要包括以下幾個部分 :
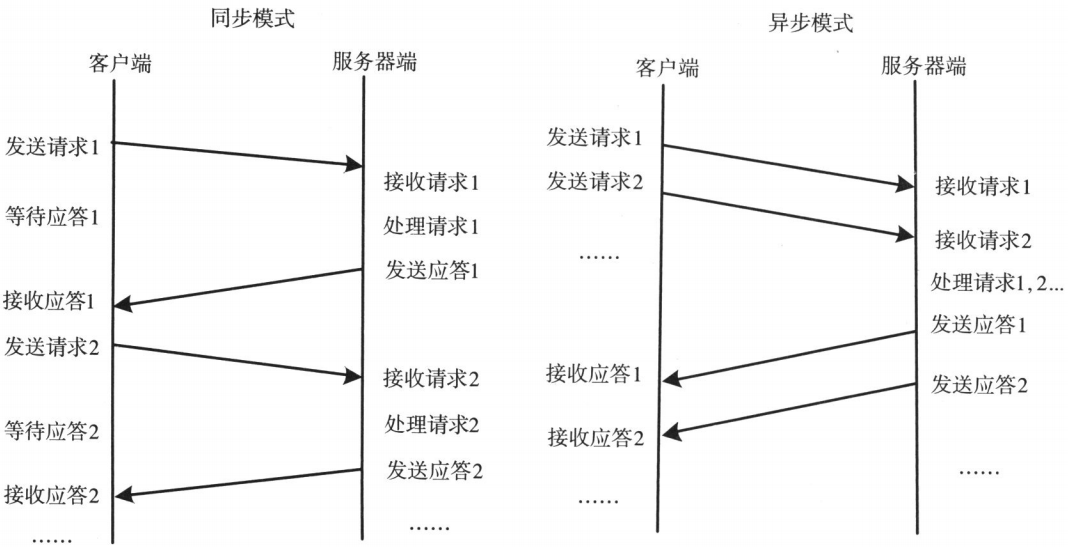
- 通信模塊。兩個相互協作的通信模塊實現請求 - 應答協議,它們在客戶和伺服器之間傳遞請求和應答消息,一般不會對數據包進行任何處理。請求 - 應答協議的實現一般有同步方式和非同步方式兩種
- 同步模式下客戶端程式一直阻塞到伺服器斷發送的應答請求到達本地
- 非同步模式下將請求發送到服務端後,不必等待應答返回,可以做其他事情
- Stub程式。客戶端和伺服器端均包含Stub程式,可以將之看作代理程式。它使得遠程函數調用表現的跟本地調用一樣,對用戶程式完全透明。在客戶端,Stub程式像一個本地程式,但不直接執行本地調用,而是將請求信息提供網路模塊發送給伺服器端,伺服器端給客戶端發送應答後,客戶端Stub程式會解碼對應結果。在伺服器端,Stub程式依次進行解碼請求消息中的參數、調用相應的服務過程和編碼應答結果的返回值等處理
- 調度程式。調度程式接收來自通信模塊的請求信息,並根據其中的標識選擇一個Stub程式進行處理。通常客戶端併發請求量比較大時,會採用線程池提高處理效率
- 客戶程式/服務過程。請求的發出者和請求的處理者
- 客戶程式以本地方式調用系統產生的Stub程式
- 該Stub程式將函數調用信息按照網路通信模塊的要求封裝成消息包,並交給通信模塊發送給遠程伺服器端
- 遠程伺服器端接收此消息後,將此消息發送給相應的Stub程式
- Stub程式拆封消息,形成被調過程要求的形式,並調用對應函數
- 被調用函數按照所獲參數執行,並將結果返回給Stub程式
- Stub程式將此結果封裝成消息,通過網路通信模塊逐級地傳送給客戶程式
- 透明性。這是所有RPC框架最根本的特點,即當用戶在一臺電腦的程式調用另外一臺電腦上的子程式時,用戶自身不應感覺到其間設計機器間的通信,而是感覺像是在執行一個本地調用
- 高性能。Hadoop各個系統(HDFS,YARN,MapReduce等)均採用了Master/Slave架構,其中,Master實際上是一個RPC Server,它負責處理集群中所有Slave發送的服務請求,為了保證Master的併發處理能力,RPC Server應是一個高性能伺服器,能夠高效地處理來自多個Client的併發RPC請求
- 可控性。RPC是Hadoop最底層最核心的模塊之一,保證其輕量級,高性能和可控性顯得尤為重要
- 序列化層。序列化主要作用是將結構化對象轉為位元組流以便於通過網路進行傳輸或寫入持久存儲,在RPC框架中,它主要是用於將用戶請求中的參數或者應答轉換成位元組流以便跨機器傳輸
- 函數調用層。函數調用層主要功能是定位要調用的而函數並執行該函數,Hadoop RPC採用了Java反射機制與動態代理實現了函數調用
- 網路傳輸層。網路傳輸層描述了Client與Server之間消息傳輸的方式,Hadoop RPC採用了基礎TCP/IP的Socket機制
- 伺服器端處理框架。伺服器端處理框架可被抽象為網路I/O模型,它描述了客戶端與伺服器間信息的交互方式,它的設計直接決定這伺服器端的併發處理能力,而Hadoop RPC採用了基於Reactor設計模式的事件驅動I/O模型
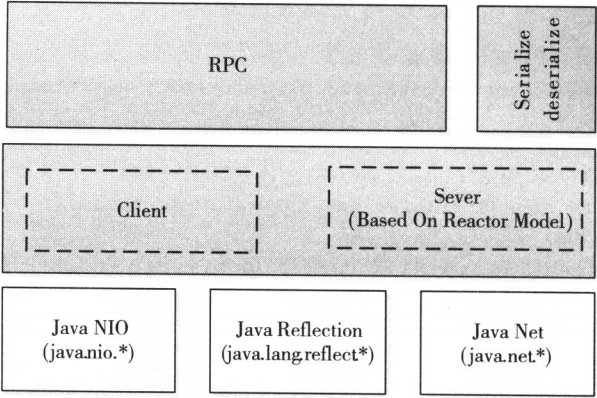
Hadoop RPC總體架構
Hadoop RPC總體架構自下而上可分為兩層,第一層是一個基於Java NIO實現的客戶機 - 伺服器通信模型。其中,客戶端將用戶的調用方法及其參數封裝成請求包後發送到伺服器端。伺服器端收到請求包後,經解包、調用參數、打包結果等一系列操作後,將結果返回給客戶端。為了增強Server端的擴展性和併發處理能力,Hadoop RPC採用了基於事件驅動的Reactor設計模式,在具體實現時,用到了JDK提供的各種功能包,主要包括java.nio、java.lang.reflect(反射機制和動態代理)、java.net(網路編程)等。第二層是供更上層程式直接調用的RPC介面,這些介面底層即為C/S通信模型 四. Hadoop RPC使用方法 Hadoop RPC對外主要提供了兩種介面(見類org.apache.hadoop.ipc.RPC),分別是 :- public static <T>ProtocolProxy <T> getProxy/waitForProxy() : 構造一個客戶端代理對象,用於向伺服器發送RPC請求
- public static Server RPC.Builder (Configuration).build() : 為某個協議實例構造一個伺服器對象,用於處理客戶端發送的請求
interface ClientProtocol extends org.apache.hadoop.ipc.VersionedProtocol { public static final long versionID = 1L; String echo(String value) throws IOException; int add(int v1 , int v2) throws IOException; }
(2) 實現RPC協議 Hadoop RPC協議通常是一個Java介面,用戶需要實現該介面
public static class ClientProtocolImpl implements ClientProtocol { //重載的方法,用於獲取自定義的協議版本號 public long getProtocolVersion(String protocol, long clientVersion) { return ClientProtocol.versionID; } //重載的方法,用於獲取協議簽名 public ProtocolSignature getProtocolSignature(String protocol, long clientVersion, inthashcode) { return new ProtocolSignature(ClientProtocol.versionID, null); } public String echo(String value) throws IOException { return value; } public int add(int v1, int v2) throws IOException { return v1 + v2; } }
(3) 構造並啟動RPC Server 直接使用靜態類Builder構造一個RPC Server,並調用函數start()啟動該Server
Server server = new RPC.Builder(conf).setProtocol(ClientProtocol.class) .setInstance(new ClientProtocolImpl()).setBindAddress(ADDRESS).setPort(0) .setNumHandlers(5).build(); server.start(); // BindAddress : 伺服器的HOST // Port : 監聽埠號,0代表系統隨機選擇一個埠號 // NumHandlers : 服務端處理請求的線程數目
(4) 構造RPC Client併發送RPC請求 使用靜態方法getProxy構造客戶端代理對象
proxy = (ClientProtocol)RPC.getProxy( ClientProtocol.class, ClientProtocol.versionID, addr, conf); int result = proxy.add(5, 6); String echoResult = proxy.echo("result");五. Hadoop RPC類詳解 Hadoop RPC主要有三個大類組成,即RPC、Client、Server,分別對應對外編程介面、客戶端實現、伺服器實現 ipc.RPC實現 RPC類實際上是對底層客戶機 - 伺服器網路模型的封裝,以便為程式員提供一套更方便簡潔的編程介面 RPC類定義了一系列構建和銷毀RPC客戶端的方法,構建方法分為getProxy和waitForProxy兩類,銷毀方只有一個,即為stopProxy。RPC伺服器的構建則由靜態內部類RPC.Builder,該類提供了一些方法共用戶設置一些基本的參數,設置完成參數,可調用build()完成一個伺服器對象的構建,調用start()方法啟動該伺服器 ipc.Client Client主要完成的功能是發送遠程過程調用信息並接收執行結果。 Client內部有兩個重要的內部類,分別是 :
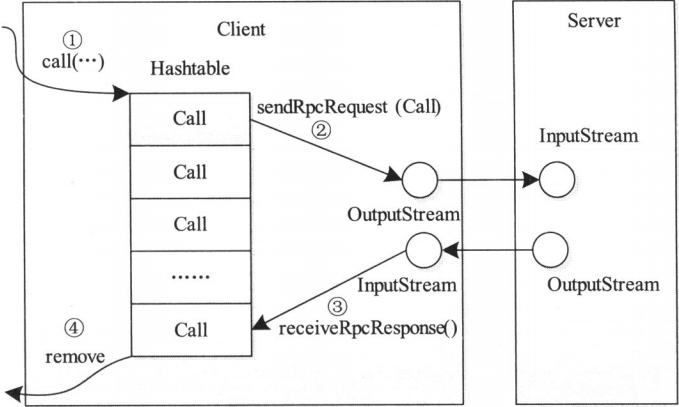
- Call類 : 封裝了一個RPC請求,它包含5個成員變數,分別是唯一標識ID、函數調用信息param、函數執行返回值value、出錯或者異常信息error和執行完成標識符done。由於Hadoop RPC Server採用非同步方式處理客戶端請求,這使遠程過程調用的發生順序與結果返回順序無直接關係,而Client端正式提供ID識別不同的函數調用的。當客戶端向伺服器端發送請求時,只需填充id和param兩個變數,而剩下的三個變數則由伺服器根據函數執行情況填充
- Connection類 : Client與每個Server之間維護一個通信連接,與該連接相關的基本信息及操作被封裝到Connection類中,基本信息主要包括通信連接唯一標識、與Server端通信的Socket、網路輸入數據流(in)、網路輸出數據流(out)、保存RPC請求的哈希表(calls)等。操作則包括 :
- addCall -- 將一個Call對象添加到哈希表中
- sendParam -- 向伺服器端發送RPC請求
- receiveResponse -- 從伺服器端接收已經處理完成的RPC請求
- run -- Connection是一個線程類,它的run方法調用了receiveResponse方法,會一直等待接收RPC返回結果
- 創建一個Connection對象,並將遠程方法調用信息封裝成Call對象,放到Connection對象中的哈希表中
- 調用Connection類中的sendRpcRequest()方法將當前Call對象發送給Server端
- Server端處理完RPC請求後,將結果通過網路返回給Client端,Client端通過receiveRpcResponse()函數獲取結果
- Client檢查結果處理狀態,並將對應Call對象從哈希表中刪除
- 通過派發/分離IO操作事件提高系統的併發性能
- 提供了粗粒度的併發控制,使用單線程實現,避免了複雜的同步處理
- Reactor : I/O事件的派發者
- Acceptor : 接受來自Client的連接,建立與Client對應的Handler,並向Reactor註冊此Handler
- Handler : 與一個Client通信的實體,並按一定的過程實現業務的處理
- Reader/Sender : 為了加速處理速度,Reactor模式往往構建一個存放數據處理線程的線程池,這樣數據讀出後,立即扔到線程吃中等待後續處理即可。為此,Reactor模式一般分離Handler中的讀和寫兩個過程,分別註冊成單獨的讀事件和寫事件,並由對應的Reader和Sender線程處理

- Reader線程數目。參數ipc.server.read.threadpool.size設置
- 每個Handler線程對應的最大Call數目。參數ipc.server.handler.queue.size設置
- Handler線程數目。參數yarn.resourcemanager.resource-tracker.client.thread-count和dfs.namenode.service.handler.count設置
- 客戶端最大重試次數。參數ipc.client.connect.max.size設置

