
一、簡介 1、簡介 簡 介• Kafka是Linkedin於2010年12月份開源的消息系統• 一種分散式的、基於發佈/訂閱的消息系統 2、特點 – 消息持久化:通過O(1)的磁碟數據結構提供數據的持久化– 高吞吐量:每秒百萬級的消息讀寫– 分散式:擴展能力強– 多客戶端支持:java、php、py ...
一、簡介
1、簡介
簡 介
• Kafka是Linkedin於2010年12月份開源的消息系統
• 一種分散式的、基於發佈/訂閱的消息系統
2、特點
– 消息持久化:通過O(1)的磁碟數據結構提供數據的持久化
– 高吞吐量:每秒百萬級的消息讀寫
– 分散式:擴展能力強
– 多客戶端支持:java、php、python、c++ ……
– 實時性:生產者生產的message立即被消費者可見
3、基本組件
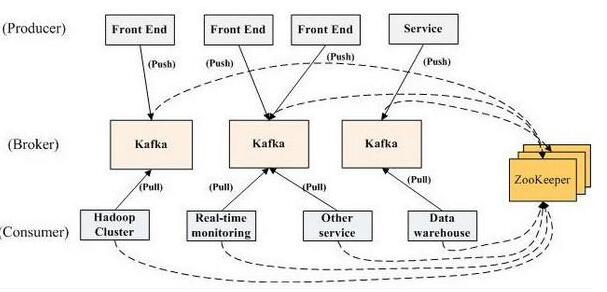
• Broker:每一臺機器叫一個Broker
• Producer:日誌消息生產者,用來寫數據
• Consumer:消息的消費者,用來讀數據
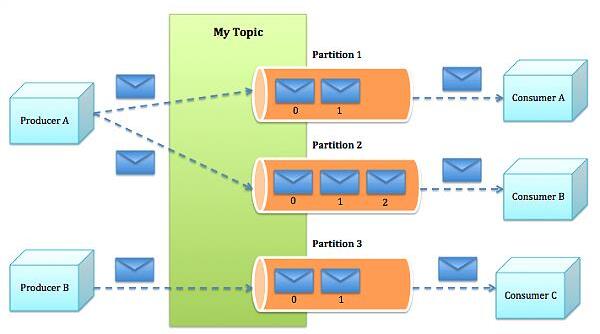
• Topic:不同消費者去指定的Topic中讀,不同的生產者往不同的Topic中寫
• Partition:新版本才支持Partition,在Topic基礎上做了進一步區分分層
好處二:動態導入模塊(基於反射當前模塊成員)
註意:
• Kafka內部是分散式的、一個Kafka集群通常包括多個Broker
• 負載均衡:將Topic分成多個分區,每個Broker存儲一個或多個Partition
• 多個Producer和Consumer同時生產和消費消息
4、Topic
• 一個Topic是一個用於發佈消息的分類或feed名,kafka集群使用分區的日誌,每個分區都是有順序且不變的消息序列。
• commit的log可以不斷追加。消息在每個分區中都分配了一個叫offset的id序列來唯一識別分區中的消息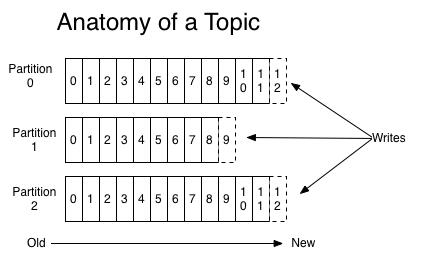
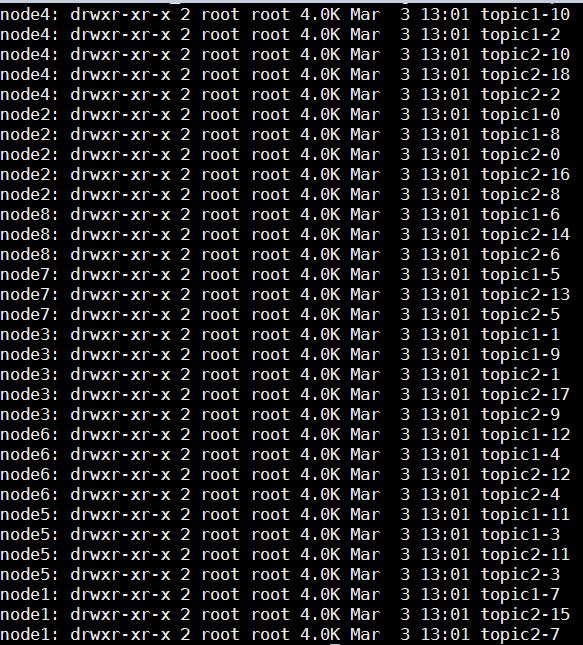
• 舉例:若創建topic1和topic2兩個topic,且分別有13個和19個分區,則整個集群上會相應會生成共32個文件夾
註意:
• 無論發佈的消息是否被消費,kafka都會持久化一定時間(可配置)。
• 在每個消費者都持久化這個offset在日誌中。通常消費者讀消息時會使offset值線性的增長,但實際上其位置是由消費者控制,它可以按任意順序來消費消息。
比如複位到老的offset來重新處理。
• 每個分區代表一個並行單元。
5、Message
• message(消息)是通信的基本單位,每個producer可以向一個topic(主題) 發佈一些消息。如果consumer訂閱了這個主題,那麼新發佈的消息就會廣播給 這些consumer。 • message format: – message length : 4 bytes (value: 1+4+n) – "magic" value : 1 byte – crc : 4 bytes – payload : n bytes
6、Producer
• 生產者可以發佈數據到它指定的topic中,並可以指定在topic里哪些消息分配到哪些分區(比如簡單的輪流分發各個分區或通過指定分區語義分配key到對應分
區)
• 生產者直接把消息發送給對應分區的broker,而不需要任何路由層。
• 批處理髮送,當message積累到一定數量或等待一定時間後進行發送。
7、Consumer
• 一種更抽象的消費方式:消費組(consumer group)
• 該方式包含了傳統的queue和發佈訂閱方式
– 首先消費者標記自己一個消費組名。消息將投遞到每個消費組中的某一個消費者實例上。
– 如果所有的消費者實例都有相同的消費組,這樣就像傳統的queue方式。
– 如果所有的消費者實例都有不同的消費組,這樣就像傳統的發佈訂閱方式。
– 消費組就好比是個邏輯的訂閱者,每個訂閱者由許多消費者實例構成(用於擴展或容錯)。
• 相對於傳統的消息系統,kafka擁有更強壯的順序保證。
• 由於topic採用了分區,可在多Consumer進程操作時保證順序性和負載均衡。

