
前面介紹了垃圾回收演算法,接下來我們介紹垃圾收集器和記憶體分配的策略。有沒有一種牛逼的收集器像銀彈一樣適配所有場景?很明顯,不可能有,不然我也沒必要單獨搞一篇文章來介紹垃圾收集器了。熟悉不同收集器的優缺點,在實際的場景中靈活運用,才是王道。 在開始介紹垃圾收集器前,我們可以劇透幾點: 根據不同分代的特點 ...
前面介紹了垃圾回收演算法,接下來我們介紹垃圾收集器和記憶體分配的策略。有沒有一種牛逼的收集器像銀彈一樣適配所有場景?很明顯,不可能有,不然我也沒必要單獨搞一篇文章來介紹垃圾收集器了。熟悉不同收集器的優缺點,在實際的場景中靈活運用,才是王道。
在開始介紹垃圾收集器前,我們可以劇透幾點:
- 根據不同分代的特點,收集器可能不同。有些收集器可以同時用於新生代和老年代,而有些時候,則需要分別為新生代或老年代選用合適的收集器。一般來說,新生代收集器的收集頻率較高,應選用性能高效的收集器;而老年代收集器收集次數相對較少,對空間較為敏感,應當避免選擇基於複製演算法的收集器。
- 在垃圾收集執行的時刻,應用程式需要暫停運行。
- 可以串列收集,也可以並行收集。
- 如果能做到併發收集(應用程式不必暫停),那絕對是很妙的事情。
- 如果收集行為可控,那也是很妙的事情。
希望大家帶著下麵的問題進行閱讀,有目標的閱讀,可能收穫更多。
- 為什麼沒有一種牛逼的收集器像銀彈一樣適配所有場景?
- CMS和G1的對比,你知道他兩的區別嗎?
- 為什麼CMS只能用作老年代收集器,而不能應用在新生代的收集?
- 為什麼JVM的分代年齡是15?而不是16,20之類的呢?
- “動態對象年齡判定”里有個“天坑”哦,是啥坑呢?
1 垃圾收集器
GC線程與應用線程保持相對獨立,當系統需要執行垃圾回收任務時,先停止工作線程,然後命令GC線程工作。以串列模式工作的收集器,稱為串列收集器(即Serial Collector)。與之相對的是以並行模式工作的收集器,稱為並行收集器(即Paraller Collector)。
1.1 串列收集器:Serial
串列收集器採用單線程方式進行收集,且在GC線程工作時,系統不允許應用線程打擾。此時,應用程式進入暫停狀態,即Stop-the-world。
Stop-the-world暫停時間的長短,是度量一款收集器性能高低的重要指標。
是針對新生代的垃圾回收器,基於標記-複製演算法。
1.2 並行收集器:ParNew
並行收集器充分利用了多處理器的優勢,採用多個GC線程並行收集。可想而知,多條GC線程執行顯然比只使用一條GC線程執行的效率更高。一般來說,與串列收集器相比,在多處理器環境下工作的並行收集器能夠極大地縮短Stop-the-world時間。
針對新生代的垃圾回收器,標記-複製演算法,可以看成是Serial的多線程版本
1.3 吞吐量優先收集器:Parallel Scavenge
針對新生代的垃圾回收器,標記-複製演算法,和ParNew類似,但更註重吞吐率。在ParNew的基礎上演化而來的Parallel Scanvenge收集器被譽為“吞吐量優先”收集器。吞吐量就是CPU用於運行用戶代碼的時間與CPU總消耗時間的比值,即吞吐量=運行用戶代碼時間 /(運行用戶代碼時間 + 垃圾收集時間)。如虛擬機總運行了100分鐘,其中垃圾收集花掉1分鐘,那吞吐量就是99%。
Parallel Scanvenge收集器在ParNew的基礎上提供了一組參數,用於配置期望的收集時間或吞吐量,然後以此為目標進行收集。
通過VM選項可以控制吞吐量的大致範圍:
- -XX:MaxGCPauseMills:期望收集時間上限。用來控制收集對應用程式停頓的影響。
- -XX:GCTimeRatio:期望的GC時間占總時間的比例,用來控制吞吐量。
- -XX:UseAdaptiveSizePolicy:自動分代大小調節策略。
但要註意停頓時間與吞吐量這兩個目標是相悖的,降低停頓時間的同時也會引起吞吐的降低。因此需要將目標控制在一個合理的範圍中。
1.4 Serial Old收集器
Serial Old是Serial收集器的老年代版本,單線程收集器,使用標記-整理演算法。這個收集器的主要意義也是在於給Client模式下的虛擬機使用。
1.5 Parallel Old收集器
Parallel Old是Parallel Scanvenge收集器的老年代版本,多線程收集器,使用標記-整理演算法。
1.6 CMS收集器
CMS(Concurrent Mark Sweep)收集器是一種以獲取最短回收停頓時間為目標的收集器。
CMS收集器僅作用於老年代的收集,是基於標記-清除演算法的,它的運作過程分為4個步驟:
- 初始標記(CMS initial mark)
- 併發標記(CMS concurrent mark)
- 重新標記(CMS remark)
- 併發清除(CMS concurrent sweep)
其中,初始標記、重新標記這兩個步驟仍然需要Stop-the-world。初始標記僅僅只是標記一下GC Roots能直接關聯到的對象,速度很快,併發標記階段就是進行GC Roots Tracing的過程,而重新標記階段則是為了修正併發標記期間因用戶程式繼續運作而導致標記產生變動的那一部分對象的標記記錄,這個階段的停頓時間一般會比初始階段稍長一些,但遠比併發標記的時間短。
CMS以流水線方式拆分了收集周期,將耗時長的操作單元保持與應用線程併發執行。只將那些必需STW才能執行的操作單元單獨拎出來,控制這些單元在恰當的時機運行,並能保證僅需短暫的時間就可以完成。這樣,在整個收集周期內,只有兩次短暫的暫停(初始標記和重新標記),達到了近似併發的目的。
CMS收集器優點:併發收集、低停頓。
CMS收集器缺點:
- CMS收集器對CPU資源非常敏感。
- CMS收集器無法處理浮動垃圾(Floating Garbage)。
- CMS收集器是基於標記-清除演算法,該演算法的缺點都有。
CMS收集器之所以能夠做到併發,根本原因在於採用基於“標記-清除”的演算法並對演算法過程進行了細粒度的分解。前面篇章介紹過標記-清除演算法將產生大量的記憶體碎片這對新生代來說是難以接受的,因此新生代的收集器並未提供CMS版本。
1.7 G1收集器
G1重新定義了堆空間,打破了原有的分代模型,將堆劃分為一個個區域。這麼做的目的是在進行收集時不必在全堆範圍內進行,這是它最顯著的特點。區域劃分的好處就是帶來了停頓時間可預測的收集模型:用戶可以指定收集操作在多長時間內完成。即G1提供了接近實時的收集特性。
G1與CMS的特征對比如下:
| 特征 | CMS | G1 |
|---|---|---|
| 併發和分代 | 是 | 是 |
| 最大化釋放堆記憶體 | 是 | 否 |
| 低延時 | 是 | 是 |
| 吞吐量 | 高 | 低 |
| 壓實 | 是 | 否 |
| 可預測性 | 強 | 弱 |
| 新生代和老年代的物理隔離 | 否 | 是 |
G1具備如下特點:
- 並行與併發:G1能充分利用多CPU、多核環境下的硬體優勢,使用多個CPU來縮短Stop-the-world停頓的時間,部分其他收集器原來需要停頓Java線程執行的GC操作,G1收集器仍然可以通過併發的方式讓Java程式繼續運行。
- 分代收集
- 空間整合:與CMS的標記-清除演算法不同,G1從整體來看是基於標記-整理演算法實現的收集器,從局部(兩個Region之間)上來看是基於“複製”演算法實現的。但無論如何,這兩種演算法都意味著G1運作期間不會產生記憶體空間碎片,收集後能提供規整的可用記憶體。這種特性有利於程式長時間運行,分配大對象時不會因為無法找到連續記憶體空間而提前觸發下一次GC。
- 可預測的停頓:這是G1相對於CMS的一個優勢,降低停頓時間是G1和CMS共同的關註點。
在G1之前的其他收集器進行收集的範圍都是整個新生代或者老年代,而G1不再是這樣。在堆的結構設計時,G1打破了以往將收集範圍固定在新生代或老年代的模式,G1將堆分成許多相同大小的區域單元,每個單元稱為Region。Region是一塊地址連續的記憶體空間,G1模塊的組成如下圖所示:
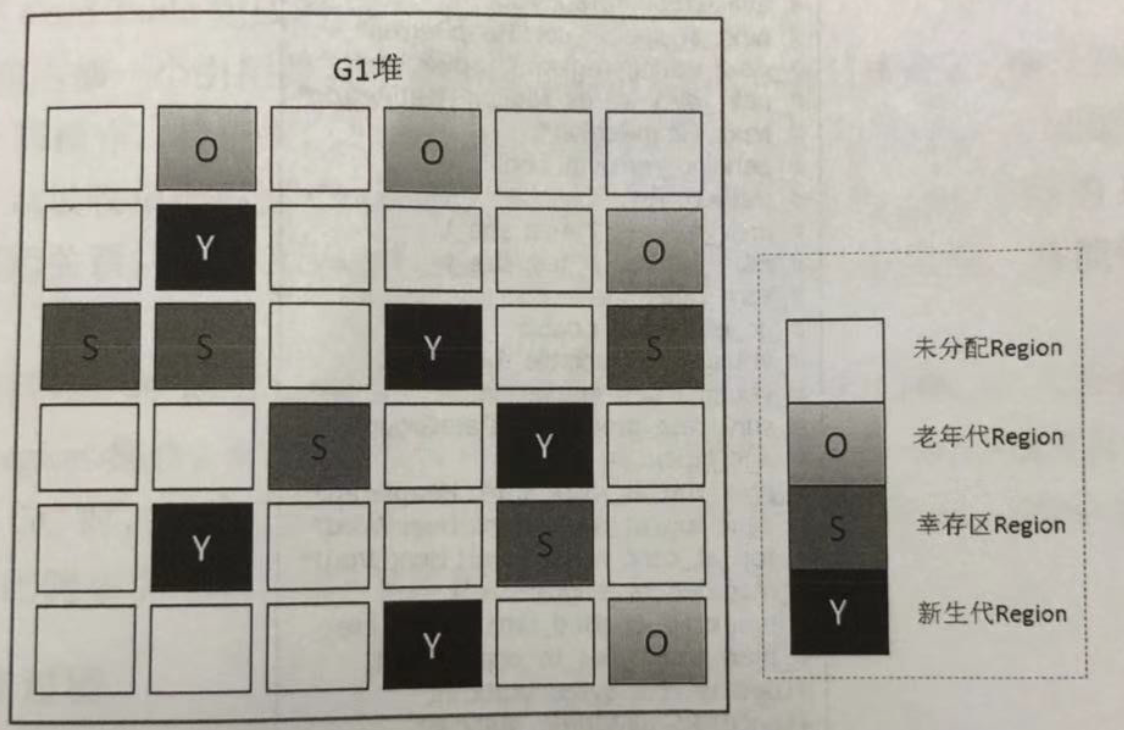
G1收集器將整個Java堆劃分為多個大小相等的獨立區域(Region),雖然還保留有新生代和老年代的概念,但新生代和老年代不再是物理隔離的了,它們都是一部分Region(不需要連續)的集合。G1收集器之所以能建立可預測的停頓時間模型,是因為它可以有計劃地避免在整個Java堆中進行全區域的垃圾收集。G1會通過一個合理的計算模型,計算出每個Region的收集成本並量化,這樣一來,收集器在給定了“停頓”時間限制的情況下,總是能選擇一組恰當的Regions作為收集目標,讓其收集開銷滿足這個限制條件,以此達到實時收集的目的。
對於打算從CMS或者ParallelOld收集器遷移過來的應用,按照官方 的建議,如果發現符合如下特征,可以考慮更換成G1收集器以追求更佳性能:
- 實時數據占用了超過半數的堆空間;
- 對象分配率或“晉升”的速度變化明顯;
- 期望消除耗時較長的GC或停頓(超過0.5——1秒)。
原文如下:
Applications running today with either the CMS or the ParallelOld garbage collector would benefit switching to G1 if the application has one or more of the following traits.
- More than 50% of the Java heap is occupied with live data.
- The rate of object allocation rate or promotion varies significantly.
- Undesired long garbage collection or compaction pauses (longer than 0.5 to 1 second)
G1收集的運作過程大致如下:
- 初始標記(Initial Marking):僅僅只是標記一下GC Roots能直接關聯到的對象,並且修改TAMS(Next Top at Mark Start)的值,讓下一階段用戶程式併發運行時,能在正確可用的Region中創建新對象,這階段需要停頓線程,但耗時很短。
- 併發標記(Concurrent Marking):是從GC Roots開始堆中對象進行可達性分析,找出存活的對象,這階段耗時較長,但可與用戶程式併發執行。
- 最終標記(Final Marking):是為了修正併發標記期間因用戶程式繼續運作而導致標記產生變動的那一部分標記記錄,虛擬機將這段時間對象變化記錄線上程Remembered Set Logs裡面,最終標記階段需要把Remembered Set Logs的數據合併到Remembered Set中,這階段需要停頓線程,但是可並行執行。
- 篩選回收(Live Data Counting and Evacuation):首先對各個Region的回收價值和成本進行排序,根據用戶所期望的GC停頓時間來制定回收計劃。這個階段也可以做到與用戶程式一起併發執行,但是因為只回收一部分Region,時間是用戶可控制的,而且停頓用戶線程將大幅提高收集效率。
我們可以看下官方文檔對G1的展望(這段英文描述比較簡單,我就不翻譯了):
Future:
G1 is planned as the long term replacement for the Concurrent Mark-Sweep Collector (CMS). Comparing G1 with CMS, there are differences that make G1 a better solution. One difference is that G1 is a compacting collector. G1 compacts sufficiently to completely avoid the use of fine-grained free lists for allocation, and instead relies on regions. This considerably simplifies parts of the collector, and mostly eliminates potential fragmentation issues. Also, G1 offers more predictable garbage collection pauses than the CMS collector, and allows users to specify desired pause targets.
2 記憶體分配策略
對象的記憶體分配,往大方向上講,就是在堆上分配(但也可能經過JIT編譯後被拆散為標量類型並間接地棧上分配),對象主要分配在新生代的Eden區上,如果啟動了本地線程分配緩衝,將按線程優先在TLAB上分配。少數情況下可能會直接分配在老年代中。
2.1 對象優先在Eden分配
大多數情況下,對象在新生代Eden區中分配。當Eden區沒有足夠空間進行分配時,虛擬機將發起一次Minor GC(前面篇章中有介紹過Minor GC)。但也有一種情況,在記憶體擔保機制下,無法安置的對象會直接進到老年代。
2.2 大對象直接進入老年代
大對象時指需要大量連續記憶體空間的Java對象,最典型的大對象就是那種很長的字元串以及數組。
虛擬機提供了一個-XX:PretenureSizeThreshold參數,令大於這個設置值的對象直接在老年代分配。目的就是避免在Eden區及兩個Survivor區之間發生大量的記憶體複製。
2.3 長期存活的對象將進入老年代
虛擬機給每個對象定義了一個對象年齡(Age)計數器。如果對象在Eden出生並經過第一次Minor GC後仍然存活,並且能被Survivor容納的話,將被移動到Survivor空間中,並且對象年齡設為1 。對象在Survivor區中沒經過一次Minor GC,年齡就加1歲,當年齡達到15歲(預設值),就會被晉升到老年代中。
對象晉升老年代的年齡閾值,可以通過參數-XX:MaxTenuringThreshold設置。
接下來我們來回答為什麼JVM的分代年齡為什麼是15?而不是16,20之類的呢?
真的不是為什麼不能是其它數(除了15),著實是臣妾做不到啊!
事情是這樣的,HotSpot虛擬機的對象頭其中一部分用於存儲對象自身的運行時數據,如哈希碼(HashCode)、GC分代年齡、鎖狀態標誌、線程持有的鎖、偏向線程ID、偏向時間戳等,這部分數據的長度在32位和64位的虛擬機(未開啟壓縮指針)中分別為32bit和64bit,官方稱它為“Mark word”。
例如,在32位的HotSpot虛擬機中,如果對象處於未被鎖定的狀態下,那麼Mark Word的32bit空間中25bit用於存儲對象哈希碼,4bit用於存儲對象分代年齡,2bit用於存儲鎖標誌位,1bit固定為0 。
明白是什麼原因了嗎?對象的分代年齡占4位,也就是0000,最大值為1111也就是最大為15,而不可能為16,20之類的了。
2.4 動態對象年齡判定
為了能更好的適應不同程式的記憶體狀況,虛擬機並不是永遠地要求兌現過的年齡必須達到了MaxTenuringThreshold才能晉升老年代。
滿足如下條件之一,對象能晉升老年代:
- 1.對象的年齡達到了MaxTenuringThreshold(預設15)能晉升老年代。
- 2.如果在Survivor空間中相同年齡所有對象大小的總和大於Survivor空間的一半,年齡大於或等於該年齡的對象就可以直接進入老年代,無須等到MaxTenuringThreshold中要求的年齡。
很多文章都只是註意到了上面描述的情況(包括阿裡中間件公眾號發的一篇文章里也只是這麼簡單的介紹,當時給它們後臺留過言說明情況),但如果只是這麼認識的話,會發現在實際的記憶體回收中有悖於此條規定。
舉個小慄子,如對象年齡5的占28%,年齡6的占20%,年齡7的占52%,按那兩個標準,對象是不能進入老年代的,但Survivor都已經100%了啊?
大家可以關註這個參數TargetSurvivorRatio,目標存活率,預設為50%。大致意思就是說年齡從小到大累加,如加入某個年齡段(如慄子中的年齡7)後,總占用超過**Survivor空間*TargetSurvivorRatio的時候,從該年齡段開始及大於的年齡對象就要進入老年代(即慄子中的年齡7對象)。動態對象年齡判斷,主要是被TargetSurvivorRatio這個參數來控制。而且算的是年齡從小到大的累加和,而不是某個年齡段對象的大小。**
2.5 空間分配擔保
在發生Minor GC之前,虛擬機會先檢查老年代最大可用的連續空間是否大於新生代所有對象總空間,如果這個條件成立,那麼Minor GC可以確保是安全的。如果不成立,則虛擬機會查看HandlePromotionFailure設置值是否允許擔保失敗。如果允許,那麼會繼續檢查老年代最大可用的連續空間是否大於歷次晉升到老年代對象的平均大小,如果大於,將嘗試著進行一次Minor GC,儘管這次Minor GC是有風險的;如果小於,或者HandlePromotionFailure設置不允許冒險,那這時也要改為進行一次Full GC 。
上面說的風險是什麼呢?我們知道,新生代使用複製收集演算法,但為了記憶體利用率,只使用其中一個Survivor空間來作為輪換備份,因此當出現大量對象在Minor GC後仍然存活的情況(最極端的情況就是記憶體回收後新生代中所有對象都存活),就需要老年代進行分配擔保,把Survivor無法容納的對象直接進入老年代。
3.總結腦圖
腦圖太大,如需高清完整大圖,請留言告知。


