
大家說起種子,應該都知道是用來下載資源的。那麼資源下載都有哪些方式?種子下載又有什麼優勢呢? 下載電影的兩種方式 第一種是通過 HTTP 進行下載。這種方式,有過經歷的人應該體會到,當下載文件稍大點,下載速度簡直能把人急死。 第二種方式就是是通過 FTP(文件傳輸協議)。FTP 採用兩個 TCP 連 ...
大家說起種子,應該都知道是用來下載資源的。那麼資源下載都有哪些方式?種子下載又有什麼優勢呢?
下載電影的兩種方式
第一種是通過 HTTP 進行下載。這種方式,有過經歷的人應該體會到,當下載文件稍大點,下載速度簡直能把人急死。
第二種方式就是是通過 FTP(文件傳輸協議)。FTP 採用兩個 TCP 連接來傳輸一個文件。
- 控制連接。伺服器以被動的方式,打開眾所周知用於 FTP 的埠 21,客戶端則主動發起連接。該連接將命令從客戶端傳給伺服器,並傳回伺服器的應答。常用的命令有:lsit - 獲取文件目錄,reter - 取一個文件,store - 存一個文件;
- 數據連接。每當一個文件在客戶端與伺服器之間傳輸時,就創建一個數據連接。
FTP 的工作模式
在 FTP 的兩個 TCP 連接中,每傳輸一個文件,都要新建立一個數據連接。基於這個數據連接,FTP 又有兩種工作模式:主動模式(PORT)和被動模式(PASV),要註意的是,這裡的主動和被動都是站在伺服器角度來說的。工作模式過程如下:
主動模式工作流程
- 客戶端隨機打開一個大於 1024 的埠 N,向伺服器的命令埠 21 發起連接,同時開放 N+1 埠監聽,並向伺服器發出“port N+1” 命令;
- 由伺服器從自己的數據埠 20,主動連接到客戶端指定的數據埠 N+1。
被動模式工作流程
- 客戶端在開啟一個 FTP 連接時,打開兩個任意的本地埠 N(大於1024)和 N+1。然後用 N 埠連接伺服器的 21 埠,提交 PASV 命令;
- 伺服器收到命令,開啟一個任意的埠 P(大於 1024),返回“227 entering passive mode”消息,消息里有伺服器開放的用來進行數據傳輸的埠號 P。
- 客戶端收到消息,取得埠號 P,通過 N+1 埠連接伺服器的 P 埠,進行數據傳輸。
上面說了 HTTP 下載和 FTP 下載,這兩種方式都有一個大缺點-難以解決單一伺服器的帶寬壓力。因為它們使用的都是傳統 C/S 結構,這種結構會隨著客戶端的增多,下載速度越來越慢。這在當今互聯網世界顯然是不合理的,我們期望能實現“下載人數越多,下載速度不變甚至更快”的願望。
後來,一種創新的,稱為 P2P 的方式實現了我們的願望。
P2P
P2P 就是 peer-to-peer。這種方式的特點是,資源一開始並不集中存儲在某些設備上,而是分散地存儲在多台設備上,這些設備我們稱為 peer。
在下載一個文件時,只要得到那些已經存在了文件的 peer 地址,並和這些 peer 建立點對點的連接,就可以就近下載文件,而不需要到中心伺服器上。一旦下載了文件,你的設備也就稱為這個網路的一個 peer,你旁邊的那些機器也可能會選擇從你這裡下載文件。
通過這種方式解決上面 C/S 結構單一伺服器帶寬壓力問題。如果使用過 P2P2 軟體,例如 BitTorrent,你就會看到自己網路不僅有下載流量,還有上傳流量,也就是說你加入了這個 P2P 網路,自己可以從這個網路里下載,同時別人也可以從你這裡下載。這樣就實現了,下載人數越多,下載速度越快的願望。
種子文件(.torent)
上面整個過程是不是很完美?是的,結果很美好,但為了實現這個美好,我們還是有很多準備工作要做的。比如,我們怎麼知道哪些 peer 有某個文件呢?
這就用到我們常說的種子(.torrent)。 .torrent 文件由Announce(Tracker URL)和文件信息兩部分組成。
其中,文件信息里有以下內容:
- Info 區:指定該種子包含的文件數量、文件大小及目錄結構,包括目錄名和文件名;
- Name 欄位:指定頂層目錄名字;
- 每個段的大小:BitTorrent(BT)協議把一個文件分成很多個小段,然後分段下載;
- 段哈希值:將整個種子種,每個段的 SHA-1 哈希值拼在一起。
下載時,BT 客戶端首先解析 .torrent 文件,得到 Tracker 地址,然後連接 Tracker 伺服器。Tracker 伺服器回應下載者的請求,將其他下載者(包括發佈者)的 IP 提供給下載者。
下載者再連接其他下載者,根據 .torrent 文件,兩者分別對方自己已經有的塊,然後交換對方沒有的數據。
可以看到,下載的過程不需要其他伺服器參與,並分散了單個線路上的數據流量,減輕了伺服器的壓力。
下載者每得到一個塊,需要算出下載塊的 Hash 驗證碼,並與 .torrent 文件中的進行對比。如果一樣,說明塊正確,不一樣就需要重新下載這個塊。這種規定是為瞭解決下載內容的準確性問題。
從這個過程也可以看出,這種方式特別依賴 Tracker。Tracker 需要收集所有 peer 的信息,並將從信息提供給下載者,使下載者相互連接,傳輸數據。雖然下載的過程是非中心化的,但是加入這個 P2P 網路時,需要藉助 Tracker 中心伺服器,這個伺服器用來登記有哪些用戶在請求哪些資源。
所以,這種工作方式有一個弊端,一旦 Tracker 伺服器出現故障或者線路被屏蔽,BT 工具就無法正常工作了。那能不能徹底去中心化呢?答案是可以的。
去中心化網路(DHT)
DHT(Distributed Hash Table),這個網路中,每個加入 DHT 網路的人,都要負責存儲這個網路里的資源信息和其他成員的聯繫信息,相當於所有人一起構成了一個龐大的分散式存儲資料庫。
而 Kedemlia 協議 就是一種著名的 DHT 協議。我們來基於這個協議來認識下這個神奇的 DHT 網路。
當一個客戶端啟動 BitTorrent 準備下載資源時,這個客戶端就充當了兩個角色:
- peer 角色:監聽一個 TCP 埠,用來上傳和下載文件。對外表明我這裡有某個文件;
- DHT Node 角色:監聽一個 UDP 埠,通過這個角色,表明這個節點加入了一個 DHT 網路。
在 DHT 網路裡面,每一個 DHT Node 都有一個 ID。這個 ID 是一個長字元串。每個 DHT Node 都有責任掌握一些“知識”,也就是文件索引。也就是說,每個節點要知道哪些文件是保存哪些節點上的。註意,這裡它只需要有這些“知識”就可以了,而它本身不一定就是保存這個文件的節點。
當然,每個 DHT Node 不會有全局的“知識”,也就是說它不知道所有的文件保存位置,只需要知道一部分。這裡的一部分,就是通過哈希演算法計算出來的。
Node ID 和文件哈希值
每個文件可以計算出一個哈希值,而 DHT Node 的 ID 是和哈希值相同長度的串。
對於文件下載,DHT 演算法是這樣規定的:
如果一個文件計算出一個哈希值,則和這個哈希值一樣的那個 DHT Node,就有責任知道從哪裡下載這個文件,即便它自己沒保存這個文件。
當然不一定總這麼巧,都能找到和哈希值一模一樣的,有可能文件對應的 DHT Node 下線了,所以 DHT 演算法還規定:
除了一模一樣的那個 DHT Node 應該知道文件的保存位置,ID 和這個哈希值非常接近的 N 個 DHT Node 也應該知道。
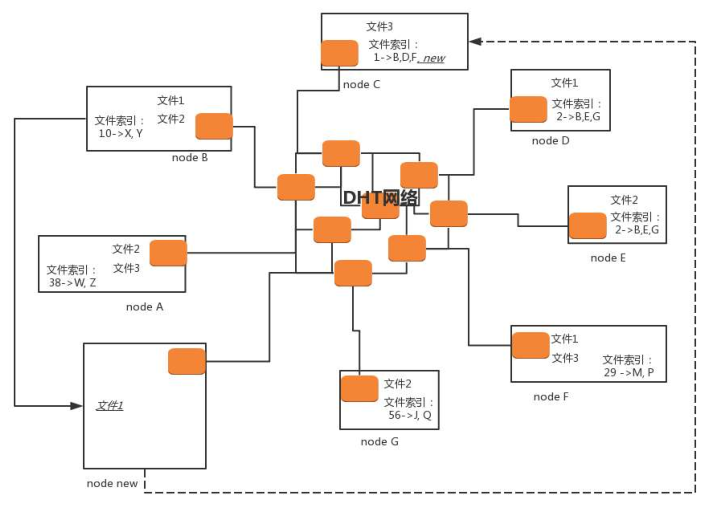
以上圖為例。文件 1 通過哈希運算,得到匹配 ID 的 DHT Node 為 Node C(當然還會有其他的,為了便於理解,咱們就先關註 Node C),所以,Node C 就有責任知道文件 1 的存放地址,雖然 Node C 本身沒有存放文件 1。
同理,文件 2 通過哈希計算,得到匹配 ID 的 DHT Node 為 Node E,但是 Node D 和 E 的值很近,所以 Node D 也知道。當然,文件 2 本身不一定在 Node D 和 E 這裡,但是我們假設 E 就有一份。
接下來,一個新節點 Node new 上線了,如果要下載文件 1,它首先要加入 DHT 網路。如何加入呢?
在這種模式下,種子 .torrent 文件裡面就不再是 Tracker 的地址了,而是一個 list 的 Node 地址,所有這些 Node 都是已經在 DHT 網路裡面的。當然,隨著時間的推移,很有可能有退出的,有下線的,這裡我們假設,不會所有的都聯繫不上,總有一個能聯繫上。
那麼,Node new 只要在種子裡面找到一個 DHT Node,就加入了網路。
Node new 不知道怎麼聯繫上 Node C,因為種子裡面的 Node 列表裡面很可能沒有 Node C,但是沒關係,它可以問。DHT 網路特別像一個社交網路,Node new 會去它能聯繫上的 Node 問,你們知道 Node C 的聯繫方式嗎?
在 DHT 網路中,每個 Node 都保存了一定的聯繫方式,但是肯定沒有所有 Node 的聯繫方式。節點之間通過相互通信,會交流聯繫方式,也會刪除聯繫方式。這和人們的溝通方式一樣,你有你的朋友圈,他有他的朋友圈,你們互相加微信,就互相認識了,但是過一段時間不聯繫,就可能會刪除朋友關係一樣。
在社交網路中,還有個著名的六度理論,就是說社交網路中的任何兩個人的直接距離不超過六度,也就是即使你想聯繫比爾蓋茨,最多通過六個人就能夠聯繫上。
所以,Node New 想聯繫 Node C,就去萬能的朋友圈去問,並且求轉發,朋友再問朋友,直到找到 C。如果最後找不到 C,但是能找到離 C 很近的節點,也可以通過 C 的相鄰節點下載文件 1。
在 Node C上,告訴 Node new,要下載文件 1,可以去 B、D、F,這裡我們假設 Node new 選擇了 Node B,那麼新節點就和 B 進行 peer 連接,開始下載。它一旦開始下載,自己本地也有文件 1 了,於是,Node new 就告訴 C 以及 C 的相鄰節點,我也有文件 1 了,可以將我加入文件 1 的擁有者列表了。
你可能會發現,上面的過程中漏掉了 Node new 的文件索引,但是根據哈希演算法,一定會有某些文件的哈希值是和 Node new 的 ID 匹配的。在 DHT 網路中,會有節點告訴它,你既然加入了咱們這個網路,也就有責任知道某些文件的下載地址了。
好了,完成分散式下載了。但是我們上面的過程中遺留了兩個細節性的問題。
1)DHT Node ID 以及文件哈希值是什麼?
其實,我們可以將節點 ID 理解為一個 160bits(20位元組)的字元串,文件的哈希也使用這樣的字元串。
2)所謂 ID 相似,具體到什麼程度算相似?
這裡就要說到兩個節點距離的定義和計算了。
在 Kademlia 網路中,兩個節點的距離採用的是邏輯上的距離,假設節點 A 和 節點 B 的距離為 d,則:
d = A XOR B
上面說過,每個節點都有一個哈希 ID,這個 ID 由 20 個字元,160 bits 位組成。這裡,我們就用一個 5 bits ID 來舉例。
我們假設,節點 A 的 ID 是 01010,節點 B 的 ID 是 01001,則:
距離 d = A XOR B = 01010 XOR 00011 = 01001 = 9
所以,我們說節點 A 和節點 B 的邏輯距離為 9。
回到我們上面的問題,哈希值接近,可以理解為距離接近,也即,和這個節點距離近的 N 個節點要知道文件的保存位置。
要註意的是,這個距離不是地理位置,因為在 Kademlia 網路中,位置近不算近,ID 近才算近。我們可以將這個距離理解為社交距離,也就是在朋友圈中的距離,或者社交網路中的距離。這個和你的空間位置沒有多少關係,和人的經歷關係比較大。
DHT 網路節點關係的維護
就像人一樣,雖然我們常聯繫的只有少數,但是朋友圈肯定是遠近都有。DHT 網路的朋友圈也一樣,遠近都有,並且按距離分層。
假設某個節點的 ID 為 01010,如果一個節點的 ID,前面所有位數都與它相同,只有最後 1 位不停,這樣的節點只有 1 個,為 01011。與基礎節點的異或值為 00001,也就是距離為 1。那麼對於 01010 而言,這樣的節點歸為第一層節點,也就是k-buket 1。
類似的,如果一個節點的 ID,前面所有位數和基礎節點都相同,從倒數第 2 位開始不同,這樣的節點只有 2 個,即 01000 和 01001,與基礎節點的亦或值為 00010 和 00011,也就是距離為 2 和 3。這樣的節點歸為第二層節點,也就是k-bucket 2。
所以,我們可以總結出以下規律:
如果一個節點的 ID,前面所有位數相同,從倒數第 i 位開始不同,這樣的節點只有 2^(i-1) 個,與基礎節點的距離範圍為 [2^(i-1), 2^i],對於原始節點而言,這樣的節點歸為k-bucket i。
你會發現,差距越大,陌生人就越多。但是朋友圈不能把所有的都放下,所以每一層都只放 K 個,這個 K 是可以通過參數配置的。
DHT 網路中查找好友
假設,Node A 的 ID 為 00110,要找 B(10000),異或距離為 10110,距離範圍在 [2^4, 2^5),這就說明 B 的 ID 和 A 的從第 5 位開始不同,所以 B 可能在 k-bucket 5 中。
然後,A 看看自己的 k-bucket 5 有沒有 B,如果有,結束查找。如果沒有,就在 k-bucket 5 里隨便找一個 C。因為是二進位,C、B 都和 A 的第 5 位不停,那麼 C 的 ID 第5 位肯定與 B 相同,即它與 B 的距離小於 2^4,相當於 A、B 之間的距離縮短了一半以上。
接著,再請求 C,在 C 的通訊裡裡,按同樣的查找方式找 B,如果 C 找到了 B,就告訴 A。如果 C 也沒有找到 B,就按同樣的搜索方法,在自己的通訊裡裡找到一個離 B 更近一步的 D(D、B 之間距離小於 2^3),把 D 推薦給 A,A 請求 D 進行下一步查找。
你可能已經發現了,Kademlia 這種查詢機制,是通過折半查找的方式來收縮範圍,對於總的節點數目為 N 的網路,最多只需要 log2(N) 次查詢,就能夠找到目標。
如下圖,A 節點找 B 節點,最壞查找情況:

圖中過程如下:
- A 和 B 的每一位都不一樣,所以相差 31,A 找到的朋友 C,不巧正好在中間,和 A 的距離是 16,和 B 的距離是 15;
- C 去自己朋友圈找,碰巧找到了 D,距離 C 為 8,距離 B 為 7;
- D 去自己朋友圈找,碰巧找到了 E,距離 D 為 4,距離 B 為 3;
- E 在自己朋友圈找,找到了 F,距離 E 為 2,距離 B 為 1;
- F 在距離為 1 的地方找到了 B。
節點的溝通
在 Kademlia 演算法中,每個節點下麵 4 個指令:
- PING:測試一個節點是否線上。相當於打個電話,看還能打通不;
- STORE:要錢一個節點存儲一份數據;
- FIND_NODE:根據節點 ID 查找一個節點;
- FIND_VALUE:根據 KEY 查找一個數據,實則上和 FIND_NODE 非常類似。KEY 就是文件對應的哈希值,找到保存文件的節點。
節點的更新
整個 DHT 網路,會通過相互通信,維護自己朋友圈好友的狀態。
- 每個 bucket 里的節點,都按最後一次接觸時間倒序排列。相當於,朋友圈裡最近聯繫的人往往是最熟的;
- 每次執行四個指令中的任意一個都會觸發更新;
- 當一個節點與自己接觸時,檢查它是否已經在 k-bucket 中。就是說是否已經在朋友圈。如果在,那麼就將它移到 k-bucket 列表的最底,也就是最新的位置(剛聯繫過,就置頂下,方便以後多聯繫)。如果不在,就要考慮新的聯繫人要不要加到通訊錄裡面。假設通訊錄已滿,就 PING 一下列表最上面的節點(最舊的),如果 PING 通了,將舊節點移動到列表最底,並丟棄新節點(老朋友還是要留點情面的)。如 PING 不同,就刪除舊節點,並將新節點加入列表(聯繫不上的老朋友還是刪掉吧)。
通過上面這個機制,保證了任意節點的加入和離開都不影響整體網路。
小結
- 下載一個文件可以通過 HTTP 或 FTP。這兩種都是集中下載的方式,而 P2P 則換了一種思路,採用非中心化下載的方式;
- P2P 有兩種。一種是依賴於 Tracker 的,也就是元數據集中,文件數據分散。另一種是基於分散式的哈希演算法,元數據和文件數據全部分散。
歡迎添加個人微信號:Like若所思。
歡迎關註我的公眾號,不僅為你推薦最新的博文,還有更多驚喜和資源在等著你!一起學習共同進步!



