
github 獲取更多資源 https://github.com/ChenMingK/WebKnowledges Notes 線上閱讀:https://www.kancloud.cn/chenmk/web knowledges/1080520 垃圾回收機制 對垃圾回收演算法而言,其核心思想就是如何判斷 ...
github 獲取更多資源
https://github.com/ChenMingK/WebKnowledges-Notes
線上閱讀:https://www.kancloud.cn/chenmk/web-knowledges/1080520
垃圾回收機制
對垃圾回收演算法而言,其核心思想就是如何判斷記憶體不再使用了
比較古老的說法是 引用計數 和 標記清除
引用計數
引用計數演算法定義“記憶體不再使用”的標準很簡單,就是看一個對象是否有指向它的引用。如果沒有其他對象指向它了,說明該對象已經不再需了。
// 創建一個對象 person,他有兩個指向屬性 age 和 name 的引用
var person = {
age: 12,
name: 'aaaa'
};
person.name = null // 雖然設置為null,但因為 person 對象還有指向 name 的引用,因此name 不會回收
var p = person
person = 1 // 原來的 person 對象被賦值為 1,但因為有新引用 p 指向原 person 對象,因此它不會被回收
p = null // 原 person 對象已經沒有引用,很快會被回收由上面可以看出,引用計數演算法是個簡單有效的演算法。但它卻存在一個致命的問題:迴圈引用。如果兩個對象相互引用,儘管他們已不再使用,垃圾回收器不會進行回收,導致記憶體泄露。比如下麵這樣
function cycle () {
var o1 = {}
var o2 = {}
o1.a = o2
o2.a = o1
return "Cycle reference!"
}
cycle()標記清除
標記清除演算法將“不再使用的對象”定義為“無法達到的對象”。簡單來說,就是從根部(在JS中就是全局對象)出發定時掃描記憶體中的對象。凡是能從根部到達的對象,都是還需要使用的。那些無法由根部出發觸及到的對象被標記為不再使用,稍後進行回收。
從這個概念可以看出,無法觸及的對象包含了沒有引用的對象這個概念(沒有任何引用的對象也是無法觸及的對象)。但反之未必成立。
V8引擎垃圾回收機制
可以閱讀這篇文章,最近看 《深入淺出 Node.js》淘到些 V8 垃圾回收機制的介紹。
V8 的垃圾回收機制與記憶體限制
在一般的後端開發語言中,基本的記憶體使用上沒有什麼限制,然而在 Node 中通過 JavaScript 使用記憶體時會發現只能使用部分記憶體(64 位系統下約為 1.4 GB,32 位系統下約為 0.7 GB)。在這樣的限制下,將會導致 Node 無法直接操作大記憶體對象,比如無法將一個 2GB 的文件讀入記憶體中進行字元串分析處理。(stream 模塊解決了這個問題)
造成這個問題的主要原因在於 Node 基於 V8 構建,V8 的記憶體管理機制在瀏覽器的應用場景下綽綽有餘,但在 Node 中卻限制了開發者。所以我們有必要知曉 V8 的記憶體管理策略。
V8 的對象分配
在 V8 中,所有的 JavaScript 對象(object)都是通過堆來進行分配的,Node 提供了 V8 中記憶體使用量的查看方式,如下:
process.memoryUsage()
{ rss: 21434368,
heapTotal: 7159808,
heapUsed: 4455120,
external: 8224 }其中,heapTotal 和 heapUsed 是 V8 的堆記憶體使用情況,前者是已申請到的堆記憶體,後者是當前使用的量。如果已申請的堆空閑記憶體不夠分配新的對象,將繼續申請堆記憶體,直到堆的大小超過 V8 的限製為止。
至於 V8 為何要限制堆的大小,主要是記憶體過大會導致垃圾回收引起 JavaScript 線程暫停執行的時間增長,應用的性能和響應會直線下降,這樣的情況不僅僅是後端服務無法接受,前端瀏覽器也無法接受。因此,在當時的考慮下直接限制堆記憶體是一個好的選擇。
不過 V8 也提供了選項讓我們打開這個限制,Node 在啟動時可以傳遞如下的選項:
node --max-old-space-size=1700 test.js // 單位為 MB 設置老生代的記憶體空間
node --max-new-space-size=1024 test.js // 單位為 KB 設置新生代的記憶體空間上述參數在 V8 初始化時生效,一旦生效就不能再改變。
V8 的垃圾回收機制
V8 的垃圾回收策略主要基於分代式垃圾回收機制,在實際應用中,人們發現沒有一種垃圾回收演算法能夠勝任所有的場景,因為對象的生存周期長短不一,不同的演算法只能針對特定情況具有最好的效果。因此,現代的垃圾回收演算法按對象的存活時間將記憶體的垃圾回收進行不同的分代,然後分別對不同分代的記憶體施以更高效的演算法。
在 V8 中,主要將記憶體分為新生代和老生代。新生代的對象為存活時間較短的對象,老生代的對象為存活時間較長或常駐記憶體的對象。

Scavenge 演算法
在分代的基礎上,新生代的對象主要通過 Scavenge 演算法進行垃圾回收,在 Scavenge 的具體實現中,主要採用了 Cheney 演算法。
Cheney 演算法是一種採用複製的方式實現的垃圾回收演算法,它將堆記憶體一分為二,每一部分空間稱為 semispace。在這兩個 semispace 空間中,只有一個處於使用中,另一個處於閑置狀態。處於使用狀態的 semispace 空間稱為 From 空間,處於閑置狀態的空間稱為 To 空間。

當我們分配對象時,先是在 From 空間中進行分配。當開始進行垃圾回收時,會檢查 From 空間的存活對象,這些存活對象將被覆制到 To 空間中,而非存活對象占用的空間將被釋放。
完成複製後,From 空間和 To 空間的角色發生對換。
- Scavenge 的缺點是只能使用堆記憶體中的一半
- Scavenge 是典型的犧牲空間換取時間的演算法,適合應用於新生代中,因為新生代中對象的生命周期較短
- 當一個對象經過多次複製仍然存活時,它將會被認為是生命周期較長的對象,其隨後會被移動到老生代中,這一過程稱為晉升
Mark-Sweep & Mark-Compact
老生代中的對象生命周期較長,存活對象占較大比重,V8 在老生代主要採用 Mark-Sweep 和 Mark-Compact 相結合的方式進行垃圾回收
Mark-Sweep:標記清除,其分為標記和清除兩個階段。在標記階段遍歷堆中的所有對象,並標記活著的對象,在清除階段只清除沒有被標記的對象。Mark-Sweep 最大的問題在於進行一次標記清除回收後,記憶體空間會出現不連續的狀態,記憶體碎片會對後續的記憶體分配造成問題,比如碎片空間不足以分配一個大對象導致提前觸發垃圾回收。
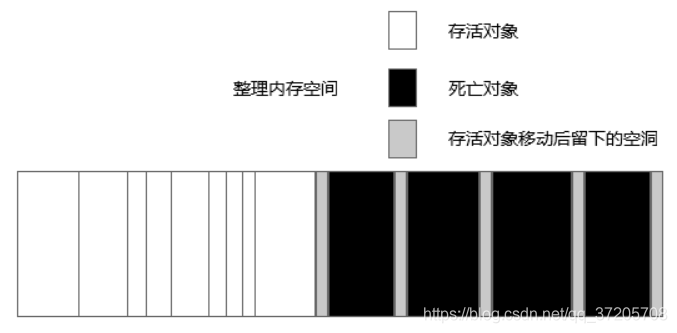
於是就有了 Mark-Compact:標記整理,簡單來說就是標記完成後加一個整理階段,存活對象往一端移動(合併),整理完成後直接清理掉邊界外的記憶體。
Incremental Marking
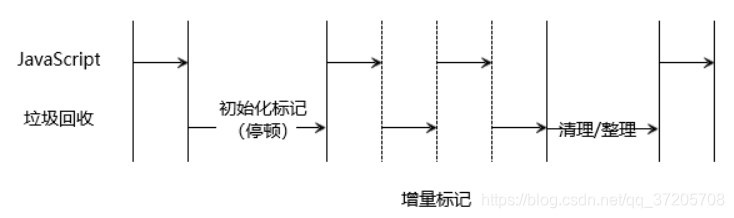
為了避免出現 JavaScript 應用邏輯與垃圾回收器看到的不一致的情況,垃圾回收的 3 種基本演算法需要將應用邏輯暫停下來,待執行完垃圾回收後再恢復執行應用邏輯,這種行為被稱為全停頓(stop-the-world)。
對於新生代來說,全停頓的影響不大,但是對於老生代就需要改善。
為了降低全堆垃圾回收帶來的停頓時間,V8 採用了增量標記(incremental marking)的技術,大概是將原本一口氣停頓完成的動作拆分為許多小“步進”,每做完一“步進”就讓 JavaScript 應用邏輯執行一小會兒,垃圾回收與應用邏輯交替執行直到標記階段完成。
V8 後續還引入了延遲清理(lazy sweeping)、增量式整理(incremental compaction)、併發標記 等技術,感興趣的可以自行瞭解。
查看垃圾回收日誌
啟動時添加 --trace_gc 參數,這樣在進行垃圾回收時,將會從標準輸出中列印垃圾回收的日誌信息。
下麵是一段示例,執行結束後,將會在 gc.log 文件中得到所有垃圾回收信息:
node --trace_gc -e "var a = []; for (var i = 0; i < 1000000; i++) a.push(new Array(100));" > gc.log通過在 Node 啟動時使用 --prof 參數,可以得到 V8 執行時的性能分析數據:
node --prof test.js
