
一、前言 Hadoop原理架構本人就不在此贅述了,可以自行百度,本文僅介紹Hadoop-3.1.2完全分散式環境搭建(本人使用三個虛擬機搭建)。 首先,步驟: ① 準備安裝包和工具: hadoop-3.1.2.tar.gz jdk-8u221-linux-x64.tar.gz(Linux環境下的JD ...
一、前言
Hadoop原理架構本人就不在此贅述了,可以自行百度,本文僅介紹Hadoop-3.1.2完全分散式環境搭建(本人使用三個虛擬機搭建)。
首先,步驟:
① 準備安裝包和工具:
-
- hadoop-3.1.2.tar.gz
- jdk-8u221-linux-x64.tar.gz(Linux環境下的JDK)
- CertOS-7-x86_64-DVD-1810.iso(CentOS鏡像)
- 工具:WinSCP(用於上傳文件到虛擬機),SecureCRTP ortable(用於操作虛擬機,可複製粘貼Linux命令。不用該工具也可以,但是要純手打命令),VMware Workstation Pro
② 安裝虛擬機:本人使用的是VMware Workstation Pro,需要激活。(先最小化安裝一個虛擬機Master,配置完Hadoop之後再克隆兩個Slave)
③ 配置虛擬機:修改用戶名,設置靜態IP地址,修改host文件,關閉防火牆,安裝Hadoop,安裝JDK,配置系統環境,配置免密碼登錄(必要)。
④ 配置Hadoop:配置hadoop-env.sh,hdfs-site.xml,core-site.xml,mepred-site.xml,yarn-site.xml,workers文件(在Hadoop-2×中是slaves文件,用於存放從節點的主機名稱,或者IP地址)
⑤ 克隆虛擬機:克隆兩個Slave,主機名稱分別是Slave1,Slave2。然後修改Slave的Hadoop配置。
⑥ namenode格式化:分別對Master、Slave1,Slave2執行hadoop namenode -format命令。
⑦ 啟動hdfs和yarn:在Master上執行start-all.sh命令。待啟動完成之後,執行jps命令查看進程,應包含namenode,secondarynamenode,resourcemaneger三個進程。Slave上有datanode,nodemanager進程。
⑧ 檢查測試:先修改真實主機的host(IP地址與Master的映射)在瀏覽器中輸入Master:9870回車,進入hdfs,點擊上方datanode應該可以看到下麵有兩個節點;輸入Master:8088回車,進入資源調度管理(yarn)
好了,開始吧。
二、準備工具
hadoop-3.1.2.tar.tz下載地址:http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz
jdk-8u221-linux-x64.tar.gz下載地址:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
CentOS下載地址:http://isoredirect.centos.org/centos/7/isos/x86_64/CentOS-7-x86_64-DVD-1810.iso
WinSCP下載地址: https://winscp.net/eng/download.php
SecureCRTP ortable下載地址: http://fs2.download82.com/software/bbd8ff9dba17080c0c121804efbd61d5/securecrt-portable/scrt675_u3.exe
VMware Workstation Pro下載地址:http://download3.vmware.com/software/wkst/file/VMware-workstation-full-15.1.0-13591040.exe
附VMware Workstation Pro秘鑰:
YG5H2-ANZ0H-M8ERY-TXZZZ-YKRV8
UG5J2-0ME12-M89WY-NPWXX-WQH88
UA5DR-2ZD4H-089FY-6YQ5T-YPRX6
三、安裝虛擬機
此步略,詳情之後發佈
四、配置虛擬機
1.修改用戶名:
hostnamectl --static set-hostname Master
2.設置靜態IP地址
首先查看一下原本自動獲取到的網關和DNS,記下來
[root@Master ~]# cat /etc/resolv.conf # Generated by NetworkManager nameserver 192.168.28.2 //DNS
[root@Master ~]# IP routing table Destination Gateway Genmask Flags MSS Window irtt Iface default 192.168.28.2(網關) 0.0.0.0 UG 0 0 0 ens33 192.168.28.0 0.0.0.0 255.255.255.0 U 0 0 0 ens33
[root@Master ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33 //修改ifcfg-ens33文件,執行此命令後進入如下界面
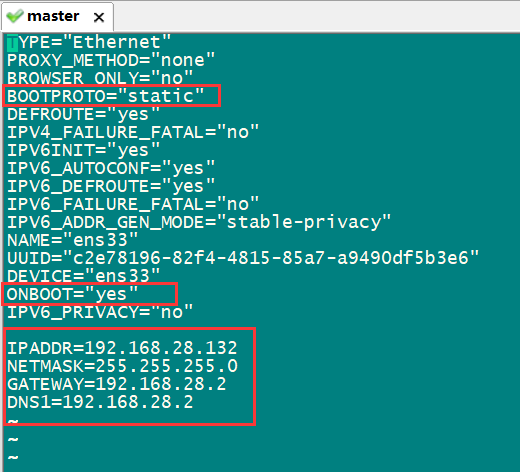
進入界面後按“I”鍵進入編輯模式,修改或添加圖中標紅部分。“static”表示靜態地址,“netmask”子網掩碼,gateways是網關,設置為上一步查看得到的即可。修改後按“esc”退出編輯模式。輸入":wq"保存退出。然後輸入以下代碼更新網路配置。
systemctl restart network
3.修改hosts文件
註明:本人設置Master的IP地址為192.168.28.132,Slave1和Slave2分別為192.168.28.133,192.168.28.134
輸入以下代碼修改hosts文件(在真實主機中也需要添加):
vi /etc/hosts
添加:
192.168.28.132 Master
192.168.28.133 Slave1
192.168.28.134 Slave2
4.關閉防火牆
關閉防火牆代碼:
systemctl stop firewalld.service //臨時關閉 systemctl disable firewalld.service //設置開機不自啟
5.安裝Hadoop和JDK
先創建兩個文件夾:
mkdir /tools //用來存放安裝包 mkdir /bigdata //存放解壓之後的文件夾
使用WinSCP上傳壓縮包:登錄後找到已下載好的壓縮包按如下步驟點擊上傳即可。
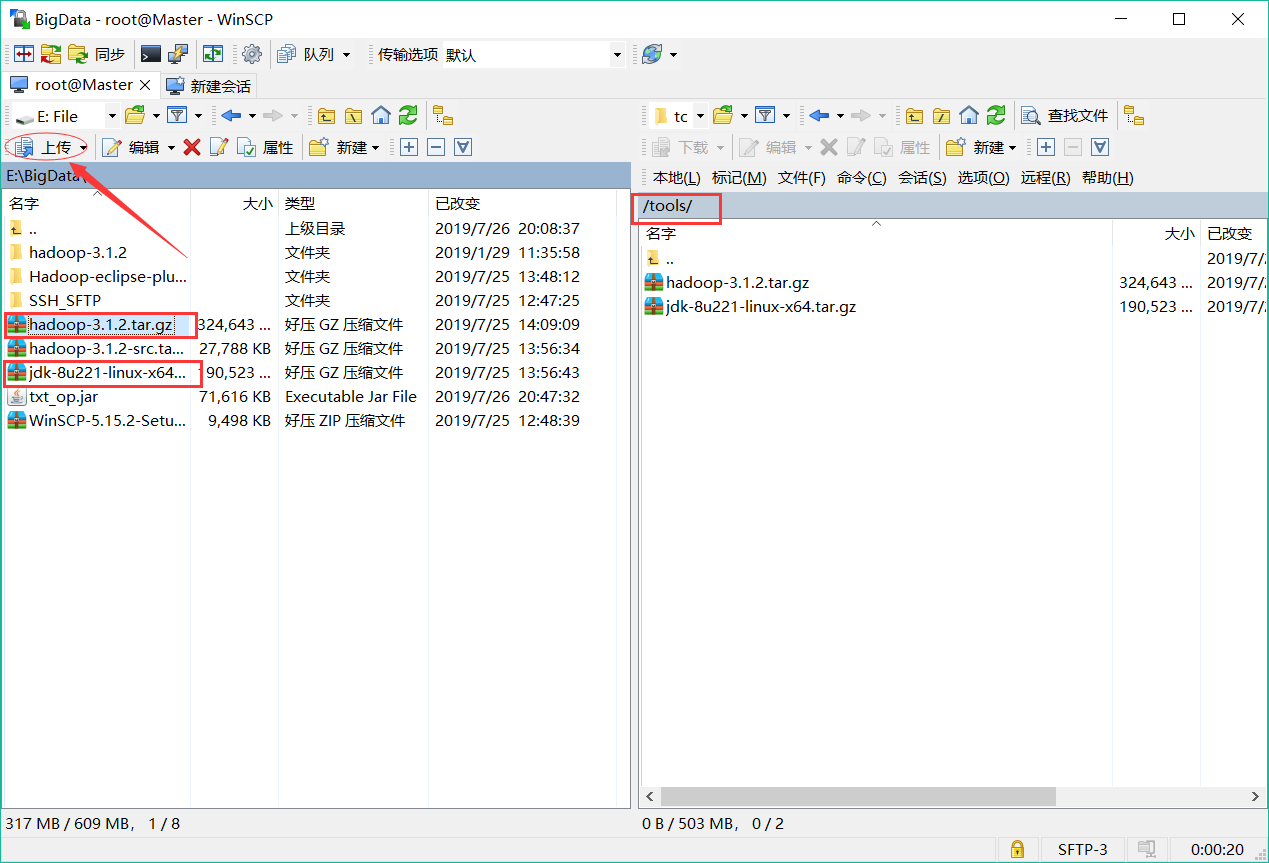
上傳文件後,虛擬機端進入tools文件夾並解壓文件:
cd /tools //進入tools文件夾 tar -zvxf jdk-8u221-linux-x64.tar.gz -C /bigdata/ //解壓文件到bigdata目錄下
tar -zvxf hadoop-3.1.2.tar.gz -C /bigdata/
6.配置系統環境
vi ~/.bash_profile 添加: export JAVA_HOME=/bigdata/jdk1.8.0_221 export JRE_HOME=$JAVA_HOME/jre export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin export HADOOP_HOME=/bigdata/hadoop-3.1.2 export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
保存退出,讓環境變數生效:
source ~/.bash_profile
7.配置免密登錄(重要)
ssh-keygen -t rsa (直接回車3次) cd ~/.ssh/ ssh-copy-id -i id_rsa.pub root@Master ssh-copy-id -i id_rsa.pub root@Slave1 ssh-copy-id -i id_rsa.pub root@Slave2
測試是否成功配置(在配置完Slave之後測試):
ssh Slave1
可以登錄到Slave1節點
五、配置Hadoop
Hadoop-3.1.2中有許多坑,在2X版本中有些預設的不需要特別配置,但在Hadoop-3.1.2中需要。
hadoop-env.sh配置:
cd /bigdata/hadoop-3.1.2/etc/hadoop/
vi hadoop-env.sh
添加:
export JAVA_HOME=/bigdata/jdk1.8.0_221
export HADOOP_HOME=/bigdata/hadoop-3.1.2
export PATH=$PATH:/bigdata/hadoop-3.1.2/bin
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"
export HADOOP_PID_DIR=/bigdata/hadoop-3.1.2/pids //PID存放目錄,若沒有此配置則預設存放在tmp臨時文件夾中,在啟動和關閉HDFS時可能會報錯
#export HADOOP_ROOT_LOGGER=DEBUG,console //先註釋掉,有問題可以打開,將調試信息列印在console上
hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name> //冗餘度,預設為3
<value>1</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/bigdata/hadoop-3.1.2/dfs/tmp/data</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/bigdata/hadoop-3.1.2/dfs/tmp/name</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
mapred.site.xml:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>Master:9001</value>
</property>
</configuration>
yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/bigdata/hadoop-3.1.2/tmp</value>
</property>
</configuration>
workers:把預設的localhost刪掉
Slave1 192.168.28.133 Slave2 192.168.28.134
yarn-env.sh 添加:
YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
進入/bigdata/hadoop-3.1.2/sbin,修改start-dfs.sh,stop-dfs.sh,都添加:
HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
六、克隆虛擬機

克隆兩個從節點虛擬機,主機名稱分別為Slave1,Slave2(需要進入虛擬機中修改),然後分別修改IP地址(具體方法上面有)重啟網路,重啟虛擬機。
重啟完成後進行namenode格式化:分別對Master、Slave1,Slave2執行:
hadoop namenode -format
對Master執行
start-all.sh //啟動hdfs和yarn
待完成後用jps查看進程:
[root@Master ~]# jps 7840 ResourceManager 8164 Jps 7323 NameNode 7564 SecondaryNameNode
兩Slave的進程:
包含以下兩個: DataNode NodeManager
七、檢查
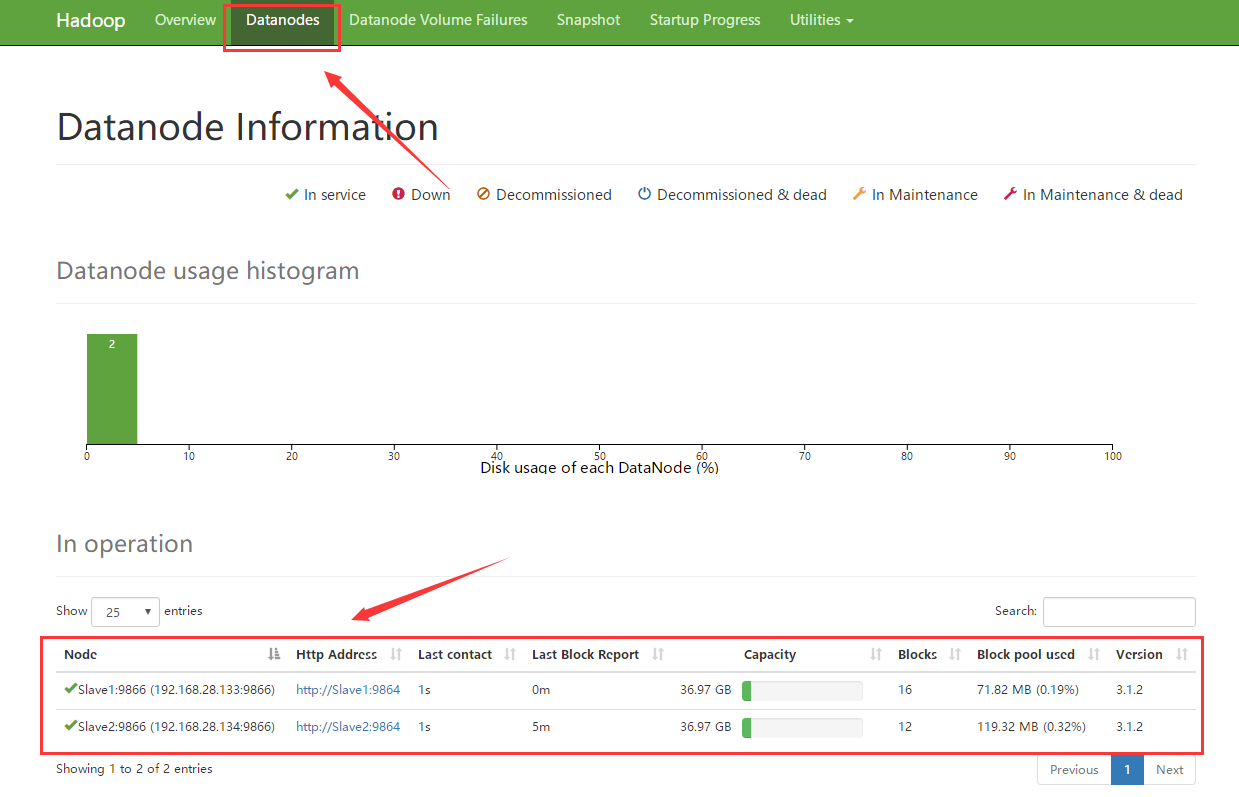
瀏覽器輸入:在瀏覽器中輸入Master:9870回車,進入hdfs管理頁面,點擊上方datanode應該可以看到下麵有兩個節點;
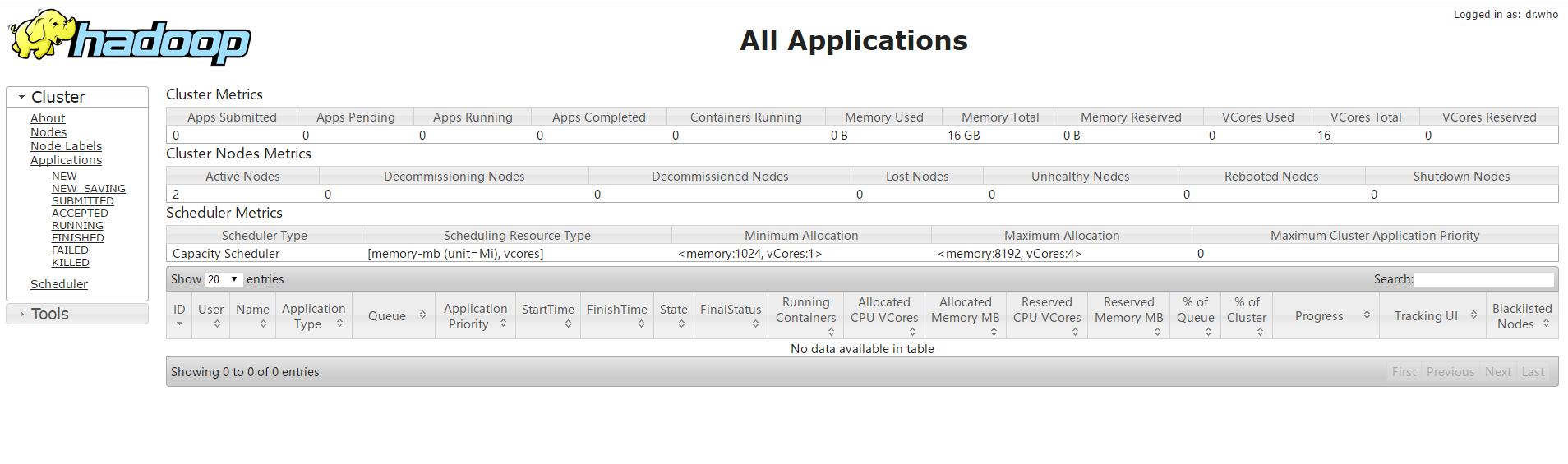
輸入Master:8088回車,進入資源調度管理(yarn)
配置到此結束。接下來學習編寫Job程式。有任何問題歡迎留言討論。

