
保留個原文鏈接,避免被爬蟲爬了過去,以便後續更正補充:https://www.cnblogs.com/wy123/p/11273023.html MySQL參數繁多,是一個需要根據具體業務、軟硬體環境、負載壓力、性能需求、數據異常的容忍程度等等信息綜合考量的結果,不是一成不變的(當然,某些參數保持默 ...
保留個原文鏈接,避免被爬蟲爬了過去,以便後續更正補充:https://www.cnblogs.com/wy123/p/11273023.html
MySQL參數繁多,是一個需要根據具體業務、軟硬體環境、負載壓力、性能需求、數據異常的容忍程度等等信息綜合考量的結果,不是一成不變的(當然,某些參數保持預設值就夠了)。
想管好資料庫,必須理解資料庫的一些配置選項,以及其背景因素。
陸陸續續收集整理了好多MySQL相關的參數,總是覺得串不起來,總結歸類之後,立馬就清晰了很多,提到一個參數,首先會往分門別類,類別是什麼,作用是什麼,有哪些相關的知識點,需要註意什麼。
這裡根據個人的思路,用xmind做了一個歸類總結以及說明,後續會修正,補充、增加。
對於這些參數的理解與說明,來自於網路、書籍以及自己的理解整理而成,不一定完全正確,隨時補充、更正、糾錯,這裡參考了許多博客,並有大段的引用解釋,詳細情況會一一註明
General參數 server_id = XXX In MySQL 5.7, the--server-id option must be specified if binary logging is enabled, otherwise the server is not allowed to start.
mysql同步的數據中是包含server_id的,用於標識該語句最初是從哪個server寫入的,因此server_id一定要有的,根據需求修改,不能重覆
user = mysql
Mysql使用的用戶
datadir = /usr/local/mysql57/data
數據文件路徑
tmpdir = /usr/local/mysql57/tmp臨時文件路徑 character-set-server = utf8mb4
預設server字元集 collation-server = utf8mb4_general_ci
字元序,某種字元集下,也即character-set-server已知的情況下,存在多種排序規則,指定其中一種排序規則,其實叫做排序規則更容易理解。
port = 3306
資料庫服務埠號 default_storage_engine =InnoDB
預設為InnoDB引擎 socket = /usr/local/mysql57/mysql.Sock
本機連接至MySQL服務可以使用sock方式連接,實際上是MySQL服務的進程Id pid-file = /usr/local/mysql57/data/mysql.pid Mysql的進程文存放位置 log_error = /usr/local/mysql57_data/mysql3306/log/mysql-error.log
啟動&錯誤日誌信息 slow_query_log = on
慢查詢日誌開關 long_query_time = n
界定慢查詢閾值,單位秒 log_output = file|table
慢查詢輸出位置,文件或者表,如果是文件的話,目標為slow_query_log_file ,如果是表的話,存儲在mysql.slowlog slow_query_log_file = /usr/local/mysql57_data/mysql3306/log/slow_query_log .log
慢查詢日誌文件 log_queries_not_using_indexes
捕獲沒有用到索引的查詢,同樣會記錄到慢查詢的目標中 log_bin_trust_function_creators = ON
存儲過程或者函數需要標記是否修改數據,參考https://www.cnblogs.com/kerrycode/p/7641835.html ###################################################################################### binlog相關參數 binlog_format = row|statment|mixed Row level 日誌中會記錄每一行數據被修改的情況,然後在slave端對相同的數據進行修改。 優點:能清楚的記錄每一行數據修改的細節 缺點:數據量太大 Statement level(預設) 每一條被修改數據的sql都會記錄到master的bin-log中,slave在複製的時候sql進程會解析成和原來master端執行過的相同的sql再次執行 優點:解決了 Row level下的缺點,不需要記錄每一行的數據變化,減少bin-log日誌量,節約磁碟IO,提高新能 缺點:容易出現主從複製不一致 Mixed(混合模式) 結合了Row level和Statement level的優點,不建議使用
bin_log_cache_size
對於事務性的操作,是要事物完成的時候寫入二進位日誌,事物提交之前,執行的寫入性操作會被緩存起來,直到整個事物完成,mysqld進程會將整個事物寫入二進位日誌。
當事物開始的時候,會按照binlog_cache_size系統變數指定的值分配內容空間,如果指定的binlog_cache_size緩存空間不夠,執行的事務性操作回滾並提示失敗
預設是32kb
由參數sync_binlog= n來控制,設置sync_binlog = 1的話,表示最高安全級別的寫入(但也不能保證不丟失任何事物日誌),相當於是一種安全寫入模式,不過對性能有一定的影響。 GTID相關參數 gtid_mode = on|off gtid模式的開關,預設是關閉的 enforce_gtid_consistency = 1 強事物一致性,開啟之後事物中不能創建臨時表 binlog_gtid_simple_recovery = 1 參考:https://keithlan.github.io/2018/05/03/gtid_binlog_gtid_simple_recovery/
5.7.6以後預設是開啟,開啟之後,以更優化的方式從binlog中讀取GTID
1. 這個變數用於在MySQL重啟或啟動的時候尋找GTIDs過程中,控制binlog 如何遍歷的演算法? 2. 當binlog_gtid_simple_recovery=FALSE 時: 為了初始化 gtid_executed,演算法是: 從newest_binlog -> oldest_binlog 方向遍歷讀取,如果發現有Previous_gtids_log_event , 那麼就停止遍歷 為了初始化 gtid_purged,演算法是: 從oldest_binlog -> newest_binlog 方向遍歷讀取, 如果發現有Previous_gtids_log_event(not empty)或者 至少有一個Gtid_log_event的文件,那麼就停止遍歷 3. 當binlog_gtid_simple_recovery=TRUE 時: 為了初始化 gtid_executed , 演算法是: 只需要讀取newest_binlog 為了初始化 gtid_purged, 演算法是: 只需要讀取oldest_binlog 4. 當設置binlog_gtid_simple_recovery=TRUE , 如果MySQL版本低於5.7.7 , 可能會有gitd計算出錯的可能,具體參考官方文檔詳細描述- 線上GTID升級的時候,binlog_gtid_simple_recovery = TRUE 必須打開,否則在binlog 刪除的時候,會發生阻塞狀況
- 線上GTID升級的時候,儘量將非GTID的binlog備份好,然後刪除掉,以免出現莫名其妙的錯誤
MySQL最經典的參數之一 如果innodb_flush_log_at_trx_commit設置為0,log buffer將每秒一次地寫入log file中,並且log file的flush(刷到磁碟)操作同時進行.該模式下,在事務提交的時候,不會主動觸發寫入磁碟的操作。
如果innodb_flush_log_at_trx_commit設置為1,每次事務提交時MySQL都會把log buffer的數據寫入log file,並且flush(刷到磁碟)中去.
如果innodb_flush_log_at_trx_commit設置為2,每次事務提交時MySQL都會把log buffer的數據寫入log file.但是flush(刷到磁碟)操作並不會同時進行。該模式下,MySQL會每秒執行一次 flush(刷到磁碟)操作。 innodb_doublewrite = 0|1 物理級保護數據安全,在將記憶體中的臟頁寫入磁碟之前,先將記憶體中的臟頁複製到記憶體的doublewrite buffer中(2MB),然後將doublewrite buffer的數據寫入共用表空間的頁中(128個page,2MB大小),然後再寫磁碟。
innodb_flush_method = fdatasync|O_DSYNC|O_DIRECT
控制著innodb數據文件及redo log的打開、刷寫模式,參考:https://blog.csdn.net/smooth00/article/details/72725941
redo LOG BUFFER 和redo LOG 以及數據文件的不同刷新模式
O_DIRECT繞過操作系統緩存,直接從innodb BUFFER寫磁碟,減少磁碟IO和記憶體的使用,會最小化緩衝對io的影響
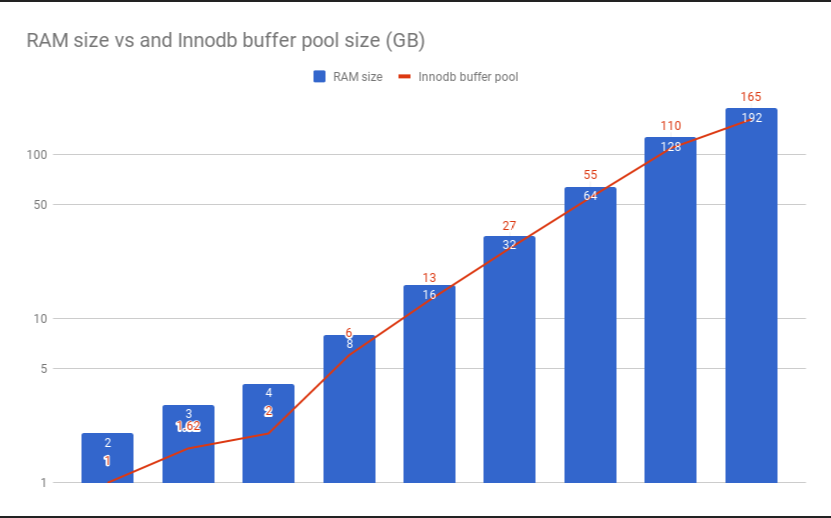
innodb_file_per_table = 1 共用表空間或者獨立表空間,1表示每個表對應一個(組)物理文件。預設值。 innodb_buffer相關參數 innodb_buffer_pool_size buffer pool 物理記憶體的70%~80%,其實這個說法是一個很粗的表述,如果是128GB的物理記憶體,純DB伺服器,配置為80%,則還剩下大概25GB左右,其實是一個很大的浪費。 參考這裡:https://scalegrid.io/blog/calculating-innodb-buffer-pool-size-for-your-mysql-server/,覺得這裡的計算方法更為合理。
 innodb_buffer_pool_instances
參考:https://www.cnblogs.com/wanbin/p/9530833.html
當innodb_buffer_pool_size不大於1GB的時候,預設是1,大於1GB的時候,預設是8,也就是有8個緩衝池實例。
MySQL允許有多個緩衝池實例,每個頁根據哈希值平均分配到不同的緩衝池實例,這樣做可以減少資料庫內部的資源競爭,增加資料庫的併發能力。
innodb_additional_mem_pool_size
該參數用來存儲數據字典和其他內部數據結構。表越多,需要在這裡分配的記憶體越多,
如果InnoDB用光了和這個池的記憶體,InnoDB開始從操作系統分配記憶體,並且往MySQL錯誤日誌中寫警告信息,預設值是8MB,當發現
錯誤日誌中有相關的警告信息時,就應該適當地增加該參數的大小,一般設置為16MB即可。
innodb_data相關參數
參考:https://blog.csdn.net/smooth00/article/details/72725941
innodb_data_home_dir
這是InnoDB表的目錄共用設置。如果沒有在 my.cnf 進行設置,InnoDB 將使用MySQL的 datadir 目錄為預設目錄
innodb_data_file_path
單獨指定數據文件的路徑與大小。數據文件的完整路徑由 innodb_data_home_dir 與這裡所設定值的組合。
innodb_log相關參數,更確切地說是redo log:
參考:https://blog.csdn.net/smooth00/article/details/72725941
innodb_log_group_home_dir
InnoDB 日誌文件的路徑。預設是當前實例的數據目錄
innodb_log_files_in_group
日誌組中的日誌文件數目,預設是的文件個數為2,也就是兩個文件(ib_logfile0和ib_logfile1)。InnoDB 以環型方式(circular fashion)寫入文件。
innodb_log_file_size
innodb_buffer_pool_instances
參考:https://www.cnblogs.com/wanbin/p/9530833.html
當innodb_buffer_pool_size不大於1GB的時候,預設是1,大於1GB的時候,預設是8,也就是有8個緩衝池實例。
MySQL允許有多個緩衝池實例,每個頁根據哈希值平均分配到不同的緩衝池實例,這樣做可以減少資料庫內部的資源競爭,增加資料庫的併發能力。
innodb_additional_mem_pool_size
該參數用來存儲數據字典和其他內部數據結構。表越多,需要在這裡分配的記憶體越多,
如果InnoDB用光了和這個池的記憶體,InnoDB開始從操作系統分配記憶體,並且往MySQL錯誤日誌中寫警告信息,預設值是8MB,當發現
錯誤日誌中有相關的警告信息時,就應該適當地增加該參數的大小,一般設置為16MB即可。
innodb_data相關參數
參考:https://blog.csdn.net/smooth00/article/details/72725941
innodb_data_home_dir
這是InnoDB表的目錄共用設置。如果沒有在 my.cnf 進行設置,InnoDB 將使用MySQL的 datadir 目錄為預設目錄
innodb_data_file_path
單獨指定數據文件的路徑與大小。數據文件的完整路徑由 innodb_data_home_dir 與這裡所設定值的組合。
innodb_log相關參數,更確切地說是redo log:
參考:https://blog.csdn.net/smooth00/article/details/72725941
innodb_log_group_home_dir
InnoDB 日誌文件的路徑。預設是當前實例的數據目錄
innodb_log_files_in_group
日誌組中的日誌文件數目,預設是的文件個數為2,也就是兩個文件(ib_logfile0和ib_logfile1)。InnoDB 以環型方式(circular fashion)寫入文件。
innodb_log_file_size
預設是48MB,在頻繁的數據寫入的實例中為了防止redolog頻繁在兩個文件中間切換,應該配置為一個較大的值,比如500MB
。 innodb_log_buffer_size 預設值是16MB,未提交事務的緩衝區大小,如果單個事物和事物併發量不大,可以保留預設值。 innodb_thread相關參數: 參考:https://www.cnblogs.com/xinysu/p/6439715.html Innodb_thread_concurrency InnoDB最大線程數 innodb_thread_sleep_delay 調整當 併發 thread 到達 innodb_thread_concurrency時需要sleep的時間 innodb_concurrency_tickets innodb_commit_concurrency backend Thread相關參數: 參考:https://www.cnblogs.com/henglxm/p/4284504.html innodb_max_dirty_pages_pct innodb_purge_threads innodb_flush_neighbors innodb_fast_shutdown innodb_file: 參考:https://www.cnblogs.com/chenpingzhao/p/5079325.html innodb_file_format = Antelope|Barracuda innodb_file_format_check innodb_file_format_max InnoDB IO相關參數 參考:https://www.cnblogs.com/henglxm/p/4284504.html,https://www.cnblogs.com/mydriverc/p/8301689.html innodb_read_io_threads 在Linux平臺上就可以根據CPU核數來更改相應的參數值了,預設是4。 innodb_write_io_threads 同innodb_read_io_threads innodb_io_capacity
按照該值的百分比來控制刷新到磁碟頁的數量
1. 在合併插入緩衝時, 合併插入緩衝的數量是該值的5%
2. 在從緩衝中刷新臟頁時, 刷新的臟頁數量等於該值.
若用戶使用了ssd類的磁碟或做了磁碟陣列, 可將該值適當調大.
Created_tmp_disk_tables 和 Created_tmp_tables 狀態來分析是否需要增加tmp_table_size
max_heap_table_size
同tmp_table_size, 它規定了內部記憶體臨時表的最大值,每個線程都要分配。(實際起限製作用的是tmp_table_size和max_heap_table_size的最小值。)
thread_cache_size:
參考:https://www.jianshu.com/p/47adb747652d
線程池緩存大小 ( 當客戶端斷開連接後 將當前線程緩存起來 當在接到新的連接請求時快速響應 無需創建新的線程 )
connect相關參數
參考:https://www.cnblogs.com/jiunadianshi/articles/2475475.html
max_connections最大連接數 wait_timeout 伺服器關閉非交互連接之前等待活動的秒數。 Interactive_timeout 伺服器關閉互動式連接前等待活動的秒數。互動式客戶端定義為在mysql_real_connect()中使用CLIENT_INTERACTIVE選項的客戶端。 connect_timeout和max_connect_errors 參考:https://www.cnblogs.com/kerrycode/p/8405862.html connect_timeout MySQL服務端進程mysqld等待連接建立完成的時間,單位為秒。如果超過connect_timeout時間範圍內,仍然無法完成協議握手話,MySQL客戶端會收到異常, 異常消息類似於: Lost connection to MySQL server at 'XXX', system error: errno,該變數預設是10秒。 max_connect_errors = N 預設值是100,不是防止暴力破解超過N次後禁止連接的,而是計算協議握手錯誤次數之後禁用主機,並且僅用於通過驗證的主機(HOST_VALIDATED = YES)。
為了防止網路中斷造成的連接失敗,從而造成客戶端無法連接,相反,這個值需要配置成一個較大的值,比如10000甚至更多。 相關信息記錄在select * from performance_schema.host_cache;使用 flush hosts;清理。 table_definition_cache: 參考:https://www.cnblogs.com/zhoujinyi/archive/2012/11/29/2795079.html table_definition_cache,該參數值的代表MySQL可以緩存的表定義的數量。和前面的table cache不同的是,表定義的緩存占用空間很小, 而且不需要使用文件描述符,也就是只要打開.frm文件,緩存表定義,然後就可以關閉.frm文件。 table_open_cache: 參考:https://www.cnblogs.com/bayaim/p/9436842.html, https://www.cnblogs.com/zhoujinyi/archive/2013/01/31/2883433.html table_open_cache指定表高速緩存的大小。每當MySQL訪問一個表時,如果在表緩衝區中還有空間,該表就被打開並放入其中,這樣可以更快地訪問表內容。 通過檢查峰值時間的狀態值Open_tables和 Opened_tables,可以決定是否需要增加table_open_cache的值。 如果你發現open_tables等於table_open_cache,並且opened_tables在不斷增長,那麼你就需要增加table_open_cache的值了(上述狀態值可:SHOW STATUS LIKE ‘Open%tables’獲得)。 query_cache 查詢緩存,不建議使用 query-cache-type: 是否打開查詢緩存 query-cache-size: 查詢緩存的大小 open_files_limit: 參考:https://www.cnblogs.com/zhoujinyi/archive/2013/01/31/2883433.html open_files_limit = table_open_cache*2 + innodb表 ###################################################################################### Master-Slave主從複製相關參數 半同步Master端參數: 參考:https://www.cnblogs.com/ivictor/p/5735580.html rpl_semi_sync_master_enabled on 開啟半同步複製 rpl_semi_sync_master_timeout 參數控制,單位是毫秒,預設為10000,即10s,master等待slave超時時間,超時之後關閉半同步,轉為非同步複製
rpl_semi_sync_master_wait_no_slave
ON預設值,當狀態變數Rpl_semi_sync_master_clients中的值小於rpl_semi_sync_master_wait_for_slave_count時,Rpl_semi_sync_master_status依舊顯示為ON。
OFF當狀態變數Rpl_semi_sync_master_clients中的值於rpl_semi_sync_master_wait_for_slave_count時,Rpl_semi_sync_master_status立即顯示為OFF,即非同步複製。
說得直白一點,如果我的架構是1主2從,2個從都採用了半同步複製,且設置的是rpl_semi_sync_master_wait_for_slave_count=2,如果其中一個掛掉了,
對於rpl_semi_sync_master_wait_no_slave設置為ON的情況,此時顯示的仍然是半同步複製,如果rpl_semi_sync_master_wait_no_slave設置為OFF,則會立刻變成非同步複製。
rpl_semi_sync_master_wait_point=wait_after_commit|wait_after_sync
參考:https://mp.weixin.qq.com/s/fvvEn6nSYzQs9NCa1eCOIQ
wait_after_commit:半同步;wait_after_sync:增強(無損)半同步
為什麼要增強的半同步複製?因為傳統的半同步複製有潛在問題
wait_after_commit模式:主上客戶端發出提交指令,事務提交到了存儲引擎後,等待從傳遞過來ack,再向前端返回成功的狀態。
與無損複製的區別就是:如果在主上這個事務已經提交到了存儲引擎,而正在等待從的ack過程中---這個時候發生creash,則主上這個事務其實已經認為commit了,而從還沒commit,
在切換到從後,就會回滾最後的這個事務,這個時候主從的時候其實就不一致了
after_commit在主機事務提交後將日誌傳送到從機,after_sync是先傳再提交
rpl_stop_slave_timeout ???
控制stop slave 命令的執行時間
控制stop slave 的執行時間,在重放一個大的事務的時候,突然執行stop slave,命令 stop slave會執行很久,這個時候可能產生死鎖或阻塞,嚴重影響性能,mysql
5.6可以通過rpl_stop_slave_timeout參數控制stop slave 的執行時間
master_info持久化方式 sync_master_info = N 每N個事件寫入一次表/文件 relay_log_info_repository = file|table relay_info持久化方式 sync_relay_log_info = N 每N個事件寫入一次表/文件 relay log信息如果配置為非Table模式,寫事物和寫文件(將已經應用的日誌位置寫入文件)是無法保持一致的 MySQL 5.6版本通過將複製信息存放到表中來解決此問題.通過配置兩個參數 relay_log_info_repository=TABLE,master_info_repository=TABLE, relay log info 會存放到 mysql.slave_relay_log_info表中, master info 會存放mysql.slave_master_info表中。就是把SQL線程執行事務和更新mysql.slave_replay_log_info的語句看成一個事務處理,這樣就會一直同步的. 半同步複製Slave端相關參數 rpl-semi-sync-slave-enabled = on Slave開啟半同步 rpl_semi_sync_master_trace_level 用於開啟半同步複製模式時的調試級別,預設是32 rpl_semi_sync_slave_trace_level 用於開啟半同步複製模式時的調試級別,預設是32 parallel replication多線程複製 slave_parallel_workers = N slave上多個線程回放master上的binlog slave_parallel_type = DATABASE | LOGICAL_CLOCK DATABASE:預設值,基於庫的並行複製方式 LOGICAL_CLOCK:基於組提交的並行複製方式 slave_preserve_commit_order =0| 1 當slave_preserve_commit_order=0時 沒有辦法保證順序,在恢復的過程中會有問題,到時候你怎麼start slave 呢? start slave until SQL_AFTER_MTS_GAPS ; reset slave Master執行順序: last_committed=0,sequence_number=1,2,3,4 slave執行順序: 有可能就是 last_committed=0,sequence_number=1,4,3,2 當slave_preserve_commit_order=1時 後一個sequence_number提交的時候,會等待前一個sequence_number完成。 Waiting for preceding transaction to commit Slave Relay log
max_relay_log_size
標記relay log 允許的最大值,如果該值為0,則預設值為max_binlog_size(1G);如果不為0,則max_relay_log_size則為最大的relay_log文件大小;
relay_log
定義relay_log的位置和名稱,如果值為空,則預設位置在數據文件的目錄,文件名為host_name-relay-bin.nnnnnn(By default, relay log file names have the form host_name-relay-bin.nnnnnn in the data directory);
relay_log_index
同relay_log,定義relay_log的位置和名稱;
relay_log_info_repository = table|file
relay_log_info_file
設置relay-log.info的位置和名稱(relay-log.info記錄MASTER的binary_log的恢複位置和relay_log的位置),也可以配置記錄到mysql庫中的slave_relay_log_info表中;
relay-log-recovery = 1
這個參數的作用是:當slave從庫宕機後,假如relay-log損壞了,導致一部分中繼日誌沒有處理,則自動放棄所有未執行的relay-log,並且重新從
master上獲取日誌,這樣就保證了relay-log的完整性。預設情況下該功能是關閉的,將relay_log_recovery的值設置為 1時,可在slave從庫上開啟該功能,建議開啟。
relay-log-purge
是否自動清空不再需要中繼日誌時。預設值為1(啟用)

