
前言 今天上午被 Flink 的一個運算元困惑了下,具體問題是什麼呢? 我有這麼個需求:有不同種類型的告警數據流(包含恢複數據),然後我要將這些數據流做一個拆分,拆分後的話,每種告警裡面的數據又想將告警數據和恢複數據拆分出來。 結果,這個需求用 Flink 的 Split 運算符出現了問題。 分析 需 ...
前言
今天上午被 Flink 的一個運算元困惑了下,具體問題是什麼呢?
我有這麼個需求:有不同種類型的告警數據流(包含恢複數據),然後我要將這些數據流做一個拆分,拆分後的話,每種告警裡面的數據又想將告警數據和恢複數據拆分出來。
結果,這個需求用 Flink 的 Split 運算符出現了問題。
分析
需求如下圖所示:
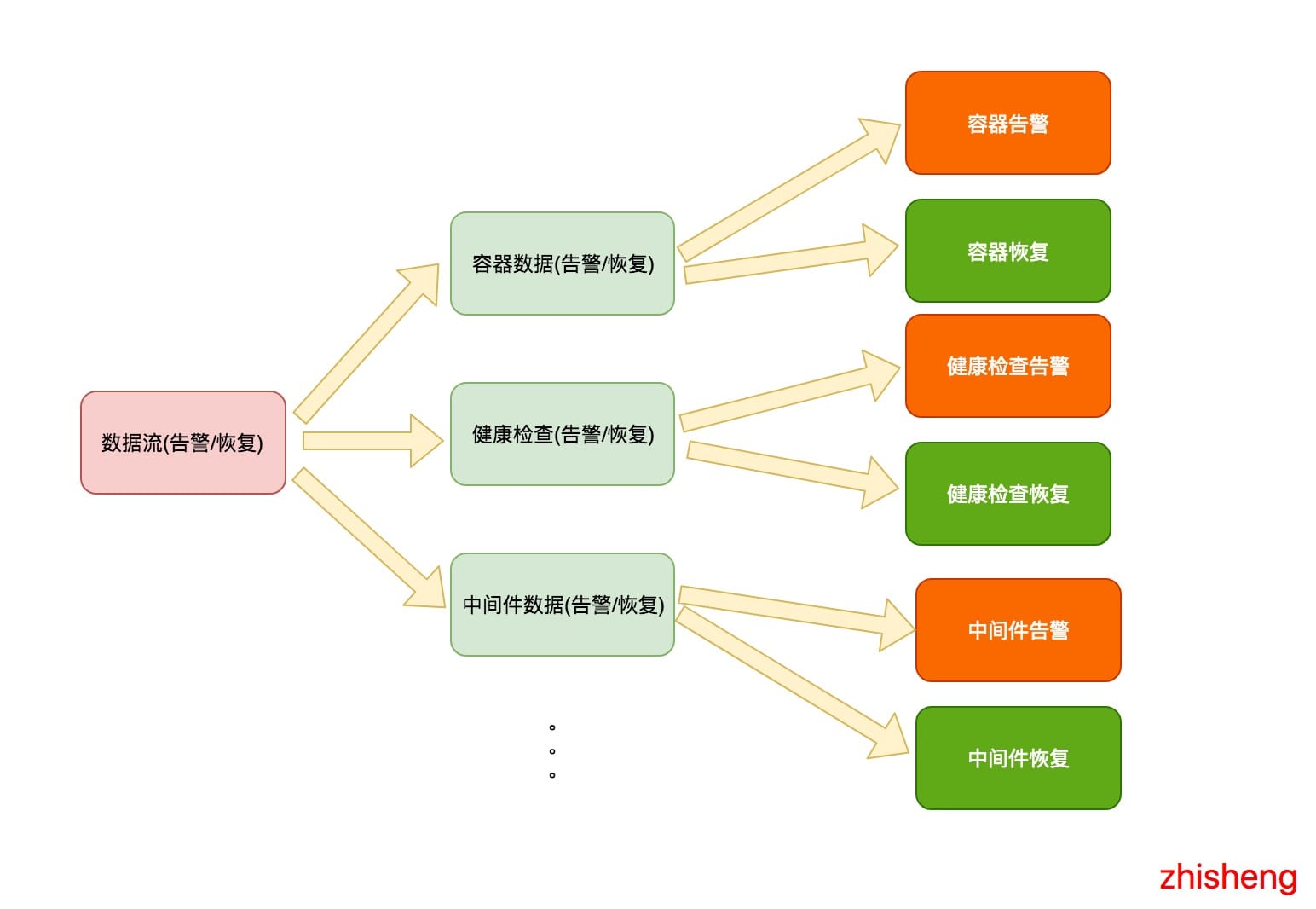
我是期望如上這樣將數據流進行拆分的,最後將每種告警和恢復用不同的消息模版做一個渲染,渲染後再通過各種其他的方式(釘釘群
郵件、簡訊)進行告警通知。
於是我的代碼大概的結構如下代碼所示:
//dataStream 是總的數據流
//split 是拆分後的數據流
SplitStream<AlertEvent> split = dataStream.split(new OutputSelector<AlertEvent>() {
@Override
public Iterable<String> select(AlertEvent value) {
List<String> tags = new ArrayList<>();
switch (value.getType()) {
case MIDDLEWARE:
tags.add(MIDDLEWARE);
break;
case HEALTH_CHECK:
tags.add(HEALTH_CHECK);
break;
case DOCKER:
tags.add(DOCKER);
break;
//...
//當然這裡還可以很多種類型
}
return tags;
}
});
//然後你想獲取每種不同的數據類型,你可以使用 select
DataStream<AlertEvent> middleware = split.select(MIDDLEWARE); //選出中間件的數據流
//然後你又要將中間件的數據流分流成告警和恢復
SplitStream<AlertEvent> middlewareSplit = middleware.split(new OutputSelector<AlertEvent>() {
@Override
public Iterable<String> select(AlertEvent value) {
List<String> tags = new ArrayList<>();
if(value.isRecover()) {
tags.add(RECOVER)
} else {
tags.add(ALERT)
}
return tags;
}
});
middlewareSplit.select(ALERT).print();
DataStream<AlertEvent> healthCheck = split.select(HEALTH_CHECK); //選出健康檢查的數據流
//然後你又要將健康檢查的數據流分流成告警和恢復
SplitStream<AlertEvent> healthCheckSplit = healthCheck.split(new OutputSelector<AlertEvent>() {
@Override
public Iterable<String> select(AlertEvent value) {
List<String> tags = new ArrayList<>();
if(value.isRecover()) {
tags.add(RECOVER)
} else {
tags.add(ALERT)
}
return tags;
}
});
healthCheckSplit.select(ALERT).print();
DataStream<AlertEvent> docekr = split.select(DOCKER); //選出容器的數據流
//然後你又要將容器的數據流分流成告警和恢復
SplitStream<AlertEvent> dockerSplit = docekr.split(new OutputSelector<AlertEvent>() {
@Override
public Iterable<String> select(AlertEvent value) {
List<String> tags = new ArrayList<>();
if(value.isRecover()) {
tags.add(RECOVER)
} else {
tags.add(ALERT)
}
return tags;
}
});
dockerSplit.select(ALERT).print();結構我抽象後大概就長上面這樣,然後我先本地測試的時候只把容器的數據那塊代碼打開了,其他種告警的分流代碼註釋掉了,一運行,發現竟然容器告警的數據怎麼還摻雜著健康檢查的數據也一起列印出來了,一開始我以為自己出了啥問題,就再起碼運行了三遍 IDEA 才發現結果一直都是這樣的。
於是,我只好在第二步分流前將 docekr 數據流列印出來,發現是沒什麼問題,列印出來的數據都是容器相關的,沒有摻雜著其他種的數據啊。這會兒遍陷入了沉思,懵逼發呆了一會。
解決問題
於是還是開始面向 Google 編程:


發現第一條就找到答案了,簡直不要太快,點進去可以看到他也有這樣的需求:
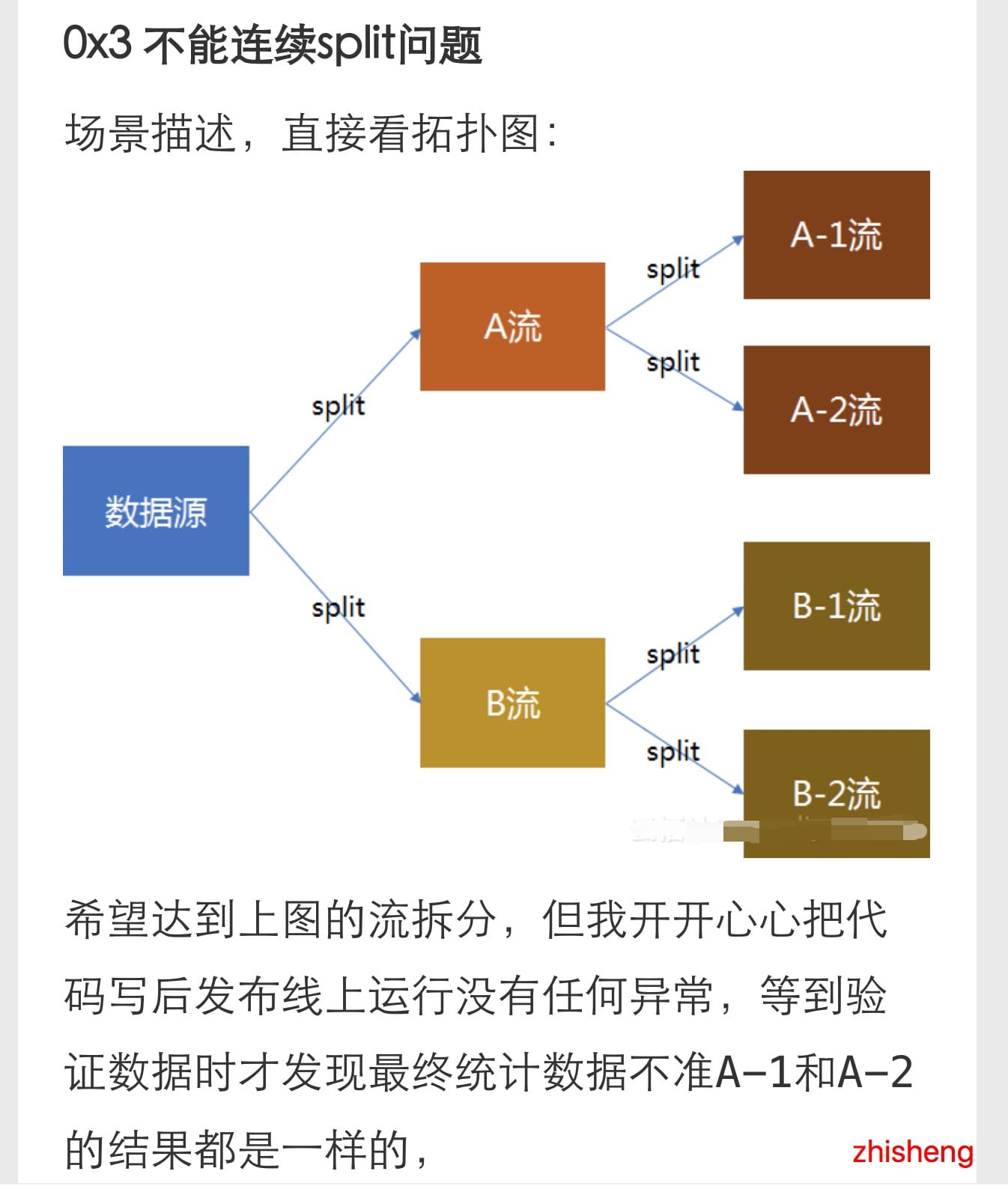
然後這個小伙伴還掙扎了下用不同的方法(雖然結果更慘):

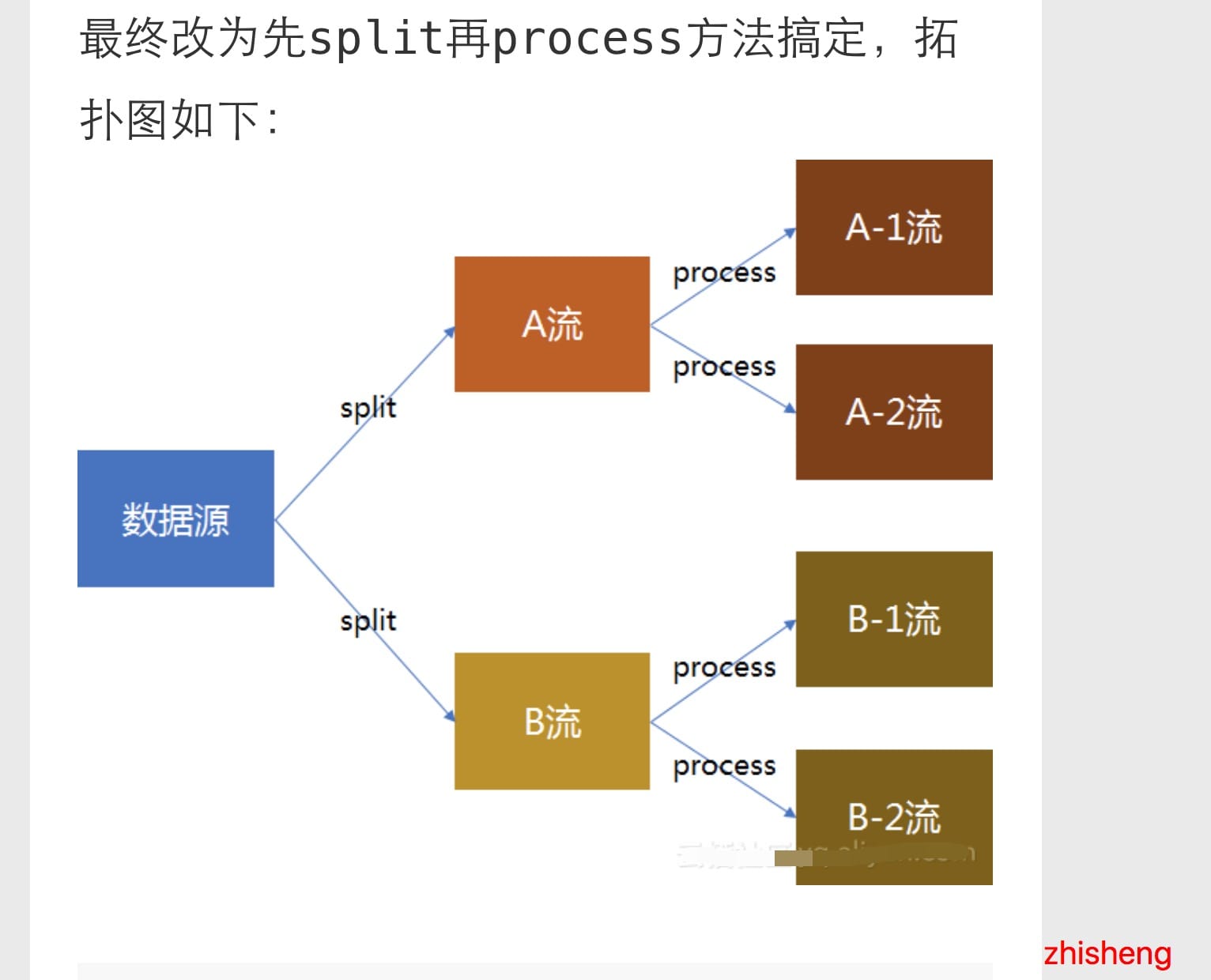
最後換了個姿勢就好了(果然小伙子會的姿勢挺多的):
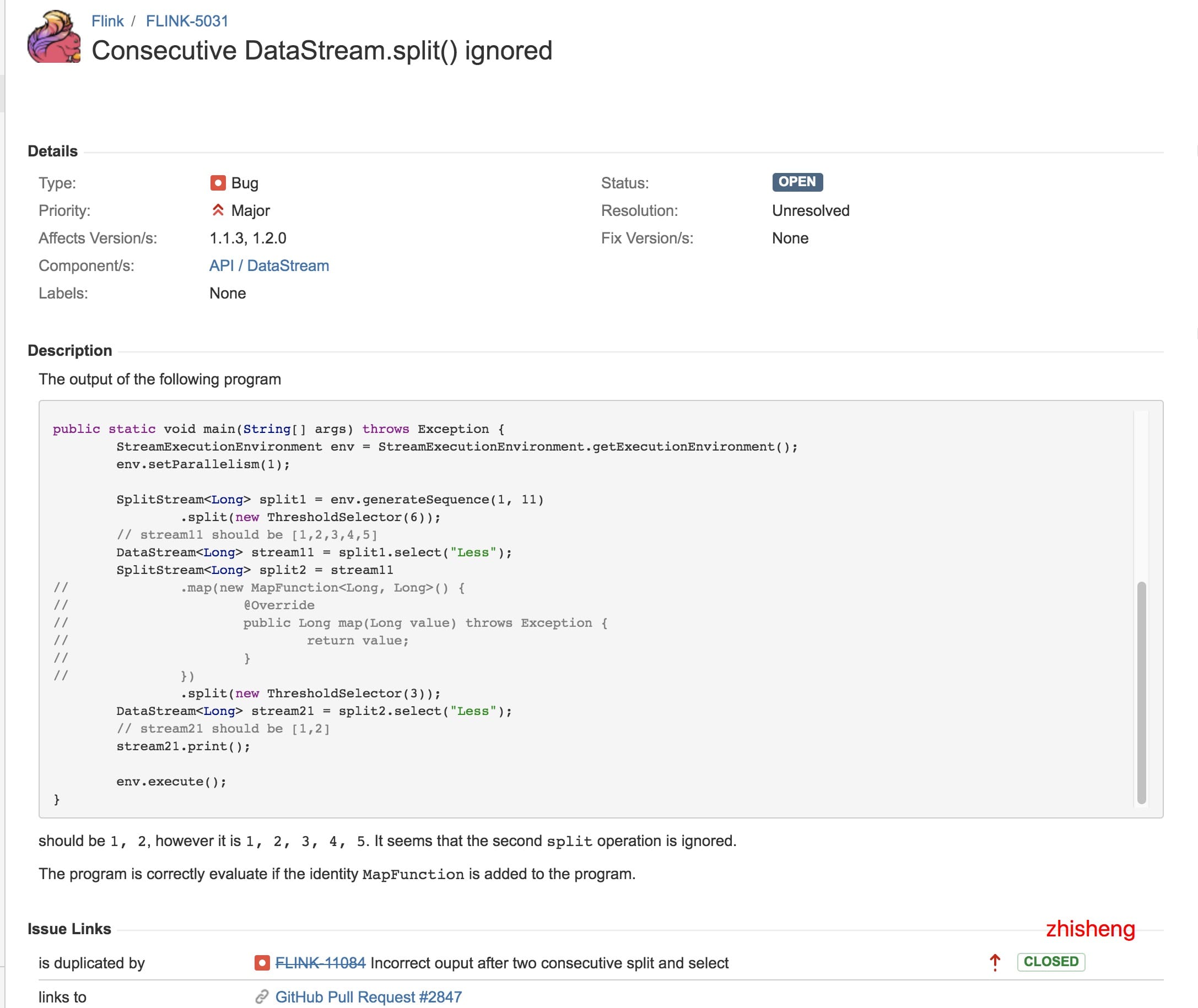
但從這篇文章中,我找到了關聯到的兩個 Flink Issue,分別是:
1、https://issues.apache.org/jira/browse/FLINK-5031
2、https://issues.apache.org/jira/browse/FLINK-11084
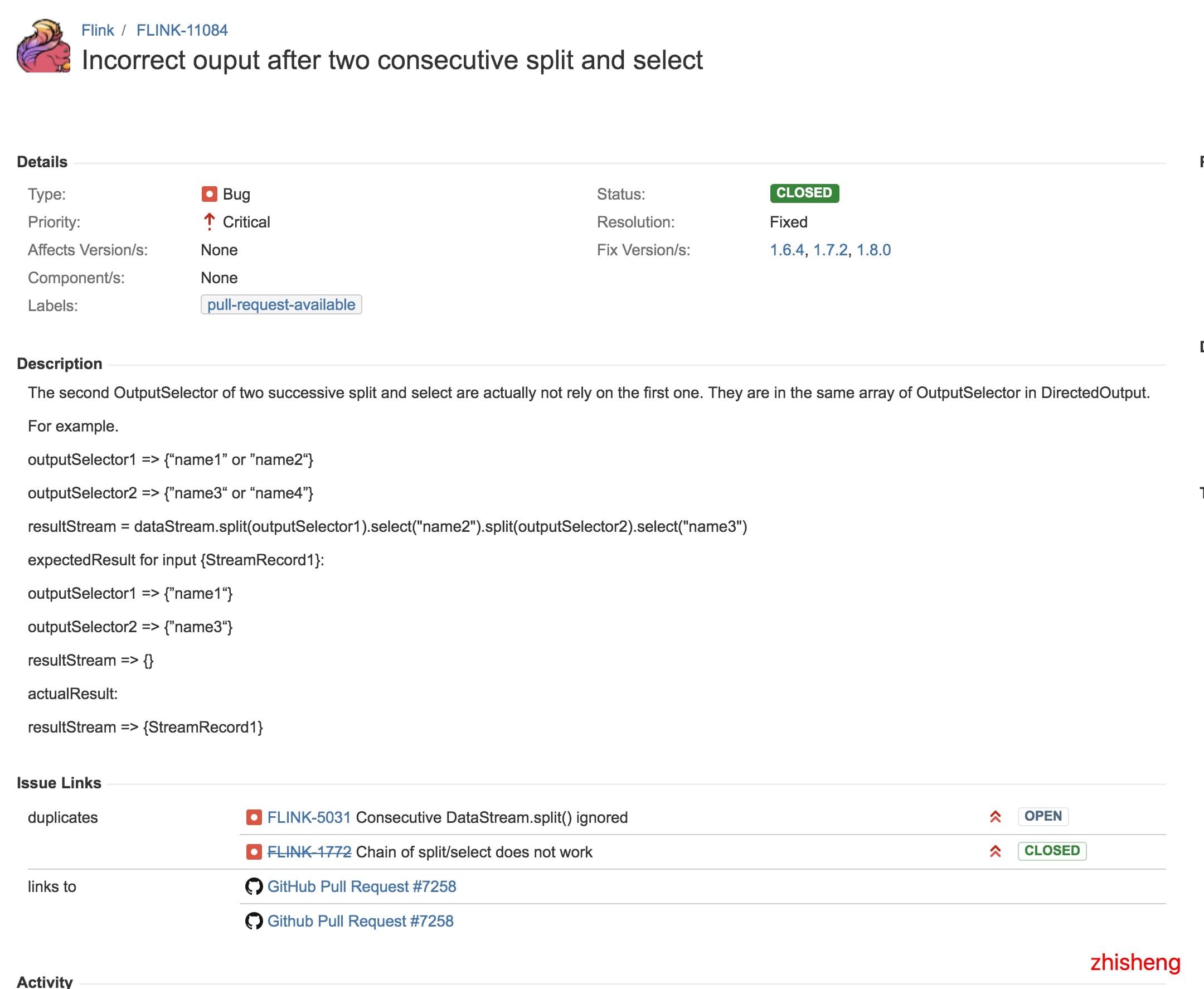
然後呢,從第二個 Issue 的討論中我發現了一些很有趣的討論:
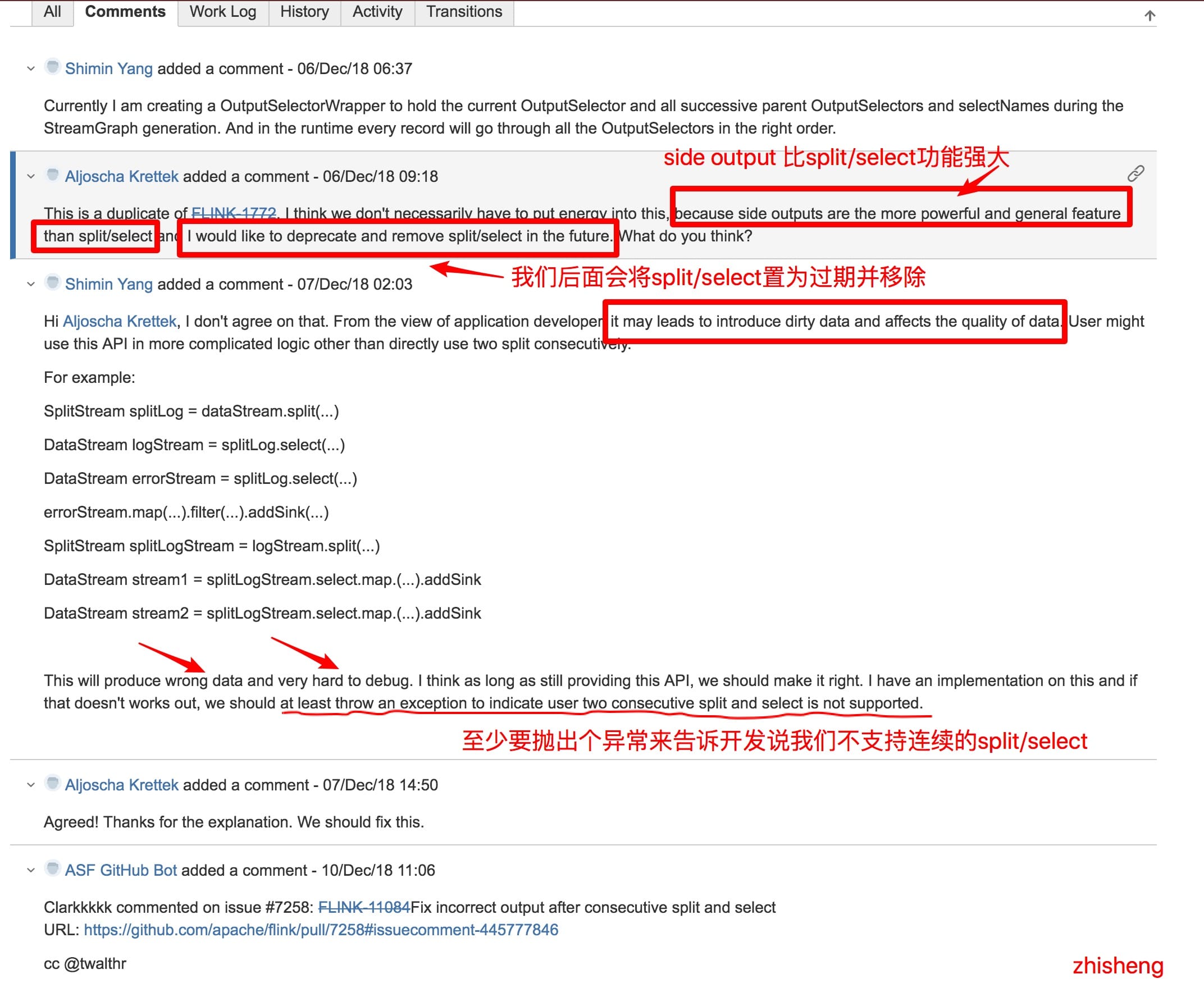
對話很有趣,但是我突然想到之前我的知識星球裡面一位很細心的小伙伴問的一個問題了:
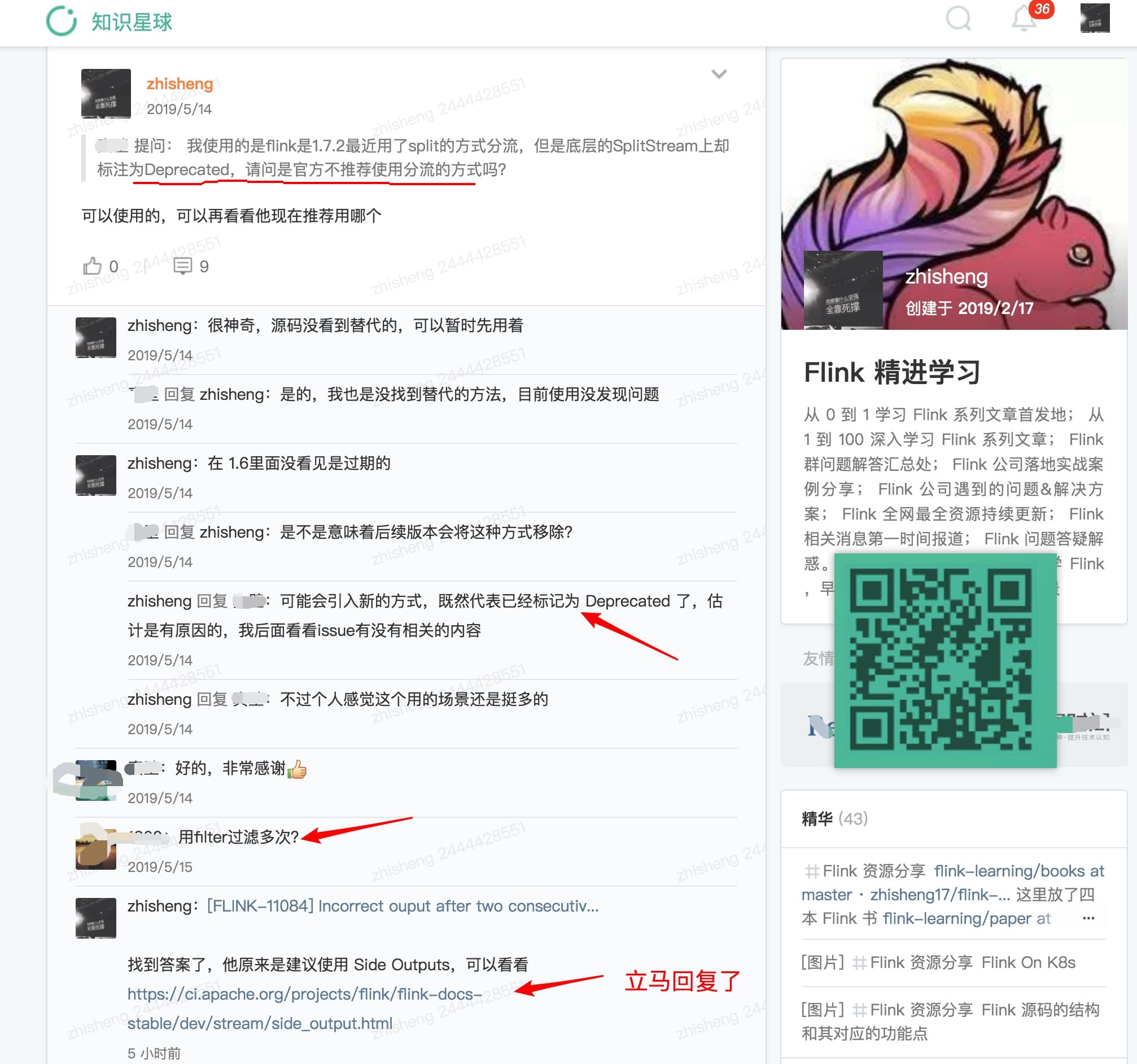
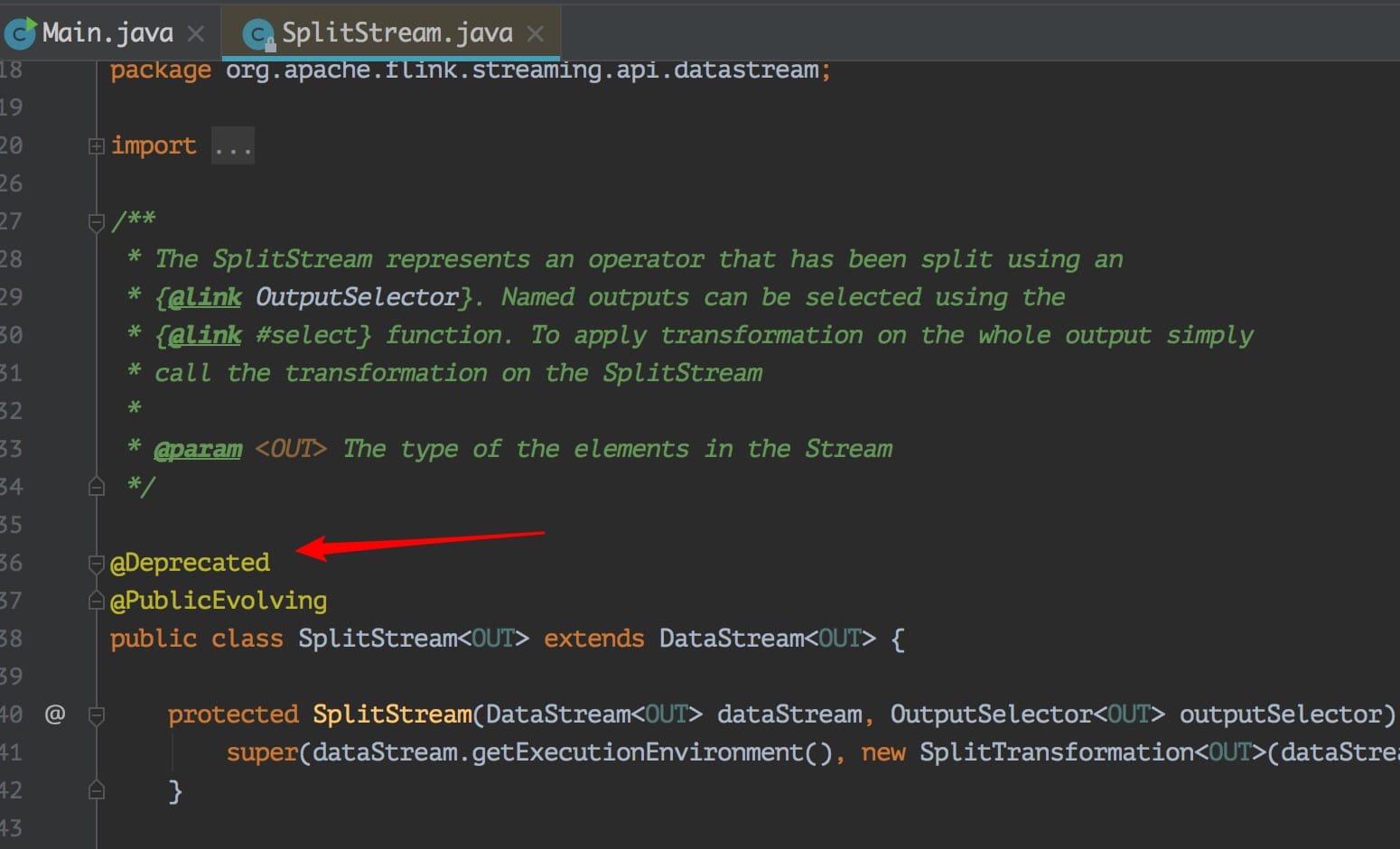
可以發現代碼上確實是標明瞭過期了,但是註釋裡面沒寫清楚推薦用啥,幸好我看到了這個 Issue,不然腦子裡面估計這個問題一直會存著呢。
那麼這個問題解決方法是不是意味著就可以利用 Side Outputs 來解決呢?當然可以啦,官方都推薦了,還不能都話,那麼不是打臉啪啪啪的響嗎?不過這裡還是賣個關子將 Side Outputs 後面專門用一篇文章來講,感興趣的可以先看看官網介紹:https://ci.apache.org/projects/flink/flink-docs-stable/dev/stream/side_output.html
另外其實也可以通過 split + filter 組合來解決這個問題,反正關鍵就是不要連續的用 split 來分流。
用 split + filter 的方案代碼大概如下:
DataStream<AlertEvent> docekr = split.select(DOCKER); //選出容器的數據流
//容器告警的數據流
docekr.filter(new FilterFunction<AlertEvent>() {
@Override
public boolean filter(AlertEvent value) throws Exception {
return !value.isRecover();
}
})
.print();
//容器恢復的數據流
docekr.filter(new FilterFunction<AlertEvent>() {
@Override
public boolean filter(AlertEvent value) throws Exception {
return value.isRecover();
}
})
.print(); 上面這種就是多次 filter 也可以滿足需求,但是就是代碼有點啰嗦。
總結
Flink 中不支持連續的 Split/Select 分流操作,要實現連續分流也可以通過其他的方式(split + filter 或者 side output)來實現
本篇文章連接是:http://www.54tianzhisheng.cn/2019/06/12/flink-split/
關註我
微信公眾號:zhisheng
另外我自己整理了些 Flink 的學習資料,目前已經全部放到微信公眾號了。你可以加我的微信:zhisheng_tian,然後回覆關鍵字:Flink 即可無條件獲取到。

更多私密資料請加入知識星球!

Github 代碼倉庫
https://github.com/zhisheng17/flink-learning/
以後這個項目的所有代碼都將放在這個倉庫里,包含了自己學習 flink 的一些 demo 和博客。
Flink 實戰
1、Flink 從0到1學習—— Apache Flink 介紹
2、Flink 從0到1學習—— Mac 上搭建 Flink 1.6.0 環境並構建運行簡單程式入門
4、Flink 從0到1學習—— Data Source 介紹
5、Flink 從0到1學習—— 如何自定義 Data Source ?
7、Flink 從0到1學習—— 如何自定義 Data Sink ?
8、Flink 從0到1學習—— Flink Data transformation(轉換)
9、Flink 從0到1學習—— 介紹Flink中的Stream Windows
10、Flink 從0到1學習—— Flink 中的幾種 Time 詳解
11、Flink 從0到1學習—— Flink 寫入數據到 ElasticSearch
12、Flink 從0到1學習—— Flink 項目如何運行?
13、Flink 從0到1學習—— Flink 寫入數據到 Kafka
14、Flink 從0到1學習—— Flink JobManager 高可用性配置
15、Flink 從0到1學習—— Flink parallelism 和 Slot 介紹
16、Flink 從0到1學習—— Flink 讀取 Kafka 數據批量寫入到 MySQL
17、Flink 從0到1學習—— Flink 讀取 Kafka 數據寫入到 RabbitMQ
18、Flink 從0到1學習》—— 你上傳的 jar 包藏到哪裡去了?
19、Flink 從0到1學習 —— Flink 中如何管理配置?
源碼解析
4、Flink 源碼解析 —— standalonesession 模式啟動流程
5、Flink 源碼解析 —— Standalone Session Cluster 啟動流程深度分析之 Job Manager 啟動
6、Flink 源碼解析 —— Standalone Session Cluster 啟動流程深度分析之 Task Manager 啟動
7、Flink 源碼解析 —— 分析 Batch WordCount 程式的執行過程
8、Flink 源碼解析 —— 分析 Streaming WordCount 程式的執行過程
9、Flink 源碼解析 —— 如何獲取 JobGraph?
10、Flink 源碼解析 —— 如何獲取 StreamGraph?
11、Flink 源碼解析 —— Flink JobManager 有什麼作用?
12、Flink 源碼解析 —— Flink TaskManager 有什麼作用?
13、Flink 源碼解析 —— JobManager 處理 SubmitJob 的過程
14、Flink 源碼解析 —— TaskManager 處理 SubmitJob 的過程
15、Flink 源碼解析 —— 深度解析 Flink Checkpoint 機制
16、Flink 源碼解析 —— 深度解析 Flink 序列化機制
17、Flink 源碼解析 —— 深度解析 Flink 是如何管理好記憶體的?原文出處:zhisheng的博客,歡迎關註我的公眾號:zhisheng


