
"消息隊列內部實現原理" "兩種消息傳輸方式" "Kafka" "kafka 簡介" "kafka 集群角色" "Kafka 工作流程分析" "Kafka 生產過程分析" "寫入方式" "分區(partition)" "副本(replication)" "寫入數據" "Broker 保存消息" "存 ...
消息隊列內部實現原理
客戶端 A 發送消息給消息隊列,客戶端 B 從消息隊列消費消息
兩種消息傳輸方式
點對點
點對點模式(一對一,消費者主動拉取數據,消息收到後消息清除),發送到隊列的消息只能被一個消費者消費,即使有多個消費者。
- 優點:拉取消息的速度是客戶端來控制的。
- 缺點:需要線程實時監控消息隊列,一有消息就拉取
發佈訂閱模式
一對多,數據產生後,推送給所有訂閱者。發佈訂閱模型可以有多種不同的訂閱者,臨時訂閱者只有在主動監聽主題時才能接受消息,持久訂閱者則監聽主題所有消息,即使當前訂閱者不可用,處於離線狀態。
- 優點:不需要監控消息隊列,消息隊列會主動推送消息。
- 缺點:客戶端獲取消息的速度由消息隊列決定,可能造成資源浪費。
消息隊列優點:
- 消息發送端和接收端不需要直接相連,可以通過一個中間件連接,可以解耦
- 消息隊列可以對數據進行備份
- 擴展性 -- 集群
- 靈活性 & 峰值處理能力
- 可恢復性
- 順序保證(隊列的特性)
- 緩衝
- 非同步通信:A 發送消息 B 掛了也沒事兒
Kafka
kafka 簡介
kafka 是一個分散式消息隊列。kafka 對消息保存時根據 Topic 進行歸類,發送消息者稱為 Producer,消息接受者稱為 Consumer,此外 kafka 集群由多個 kafka 實例組成,每個實例(server)稱為 broker。
無論是 kafka 集群還是 consumer 都依賴於 zookeeper 集群保存一些 meta 消息,來保證系統可用性。
kafka 架構
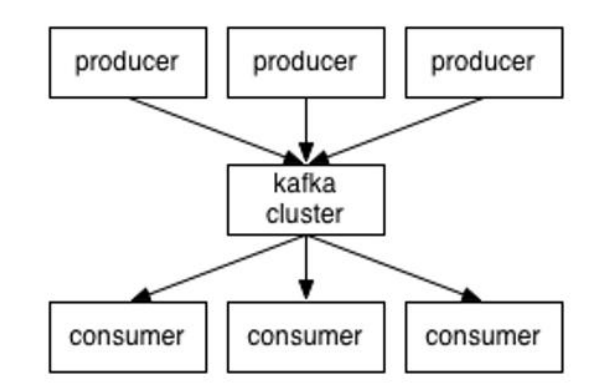
- Producer:消息生產者,就是向 kafka broker (kafka 伺服器)發消息的客戶端
- Consumer:消息消費者,向 kafka broker 取消息的客戶端
- Consumer Group:這是 kafka 用來實現一個 Topic 消息的廣播(發送給所有的 consumer)和單播(發給任意一個 consumer)的手段。topic 的消息會發送到所有的 Consumer Group。但每個 partition 只會把消息發給該 Consumer Group 中的一個 consumer。如果需要實現廣播,只要每個 consumer 有一個獨立的 Consumer Group,即一個 consumer 一個 group。這樣該 topic 下的所有 partition 都會將消息推送給所有 consumer 了。要實現單播只要所有的 consumer 在同一個 Consumer Group。用 Consumer Group 還可以將 consumer 進行自由的分組而不需要多次發送消息到不同的 topic。
- Broker:一臺 kafka 伺服器就是一個 broker。一個集群由多個 broker 組成。一個 broker 可以容納多個 topic。
- Topic:可以理解為一個隊列
- 邏輯概念:同一個 Topic 的消息可分佈在一個或多個節點(Broker)上。
- 一個 Topic 包含一個或者多個 Partition
- 每條消息都屬於且僅屬於一個 Topic
- Producer 發佈數據時,必須指定將消息發佈到哪個 Topic
- Consumer 訂閱消息時,也必須指定訂閱哪個 Topic 的消息。
- Partition:每個 partition 是一個有序的隊列。partition 中的每條消息都會被分配一個有序的 id(offset)。kafka 只保證按一個 partition 中的順序將消息發給 consumer,不保證一個 topic 的整體(多個 partition 間)的順序。
- 一個 Patition 只分佈於一個 Broker 上(不考慮備份)。
- 一個 Partition 物理上對應一個文件夾
- 一個 Partition 包含多個 Segment(Segment 對用戶透明)。
- 一個 Segment 對應一個文件
- Segment 由一個個不可變記錄組成
- 記錄只會被 append 到 Segmentt 中,不會被單獨刪除或者修改。
- 清除過期日誌時,直接刪除一個或多個 Segment。
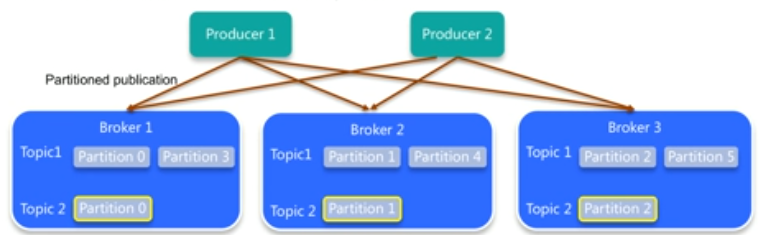
- Offset:偏移量。當前消費到的消息的位置。
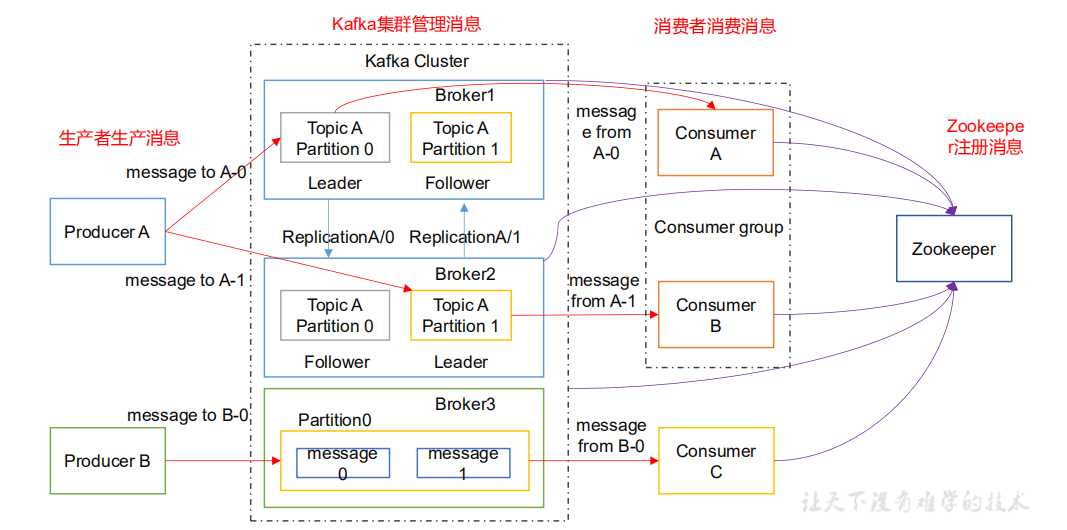
如圖可以看出:kafka 集群 > broker > topic > partition。即一個 kafka 集群中有多台 kafka 伺服器,每台伺服器可以有多個 topic 存放不同主題的消息,當一個 topic 太大了,可以將其劃分成多個 partition。上圖中 消息生產者 A 發送 主題 A 的消息到伺服器上,topic A 的消息被分在了兩個 partition 上:partition 0 與 partition 1。partition 0 和 partition 1 分別在 broker 1 和 broker 2 上有著 leader 和 follower。其中 leader 可以處理讀寫請求,當生產者發送消息到 topic 上時是發送到對應的 partition 的 leader 上去,leader 再將消息同步到 follower 上。follower 消息只能處理消費者的讀請求。然後 每個Consumer Group 可以有一個或者多個 consumer。同一個 consumer group 上的 consumer 不能消費同一個topic 下的同一個 partition,但是可以消費不同的 partition。也就是說 上圖的 consumer A 和 consumer B 不能同時消費 Topic A 下的 partition 0 但是可以分別消費 partition 0 和 partition 1。不同的 consumer group 上的 consumer 之間的消費沒有衝突,可以隨便消費。這樣可以非常方便的實現一個 Topic 的廣播和單播。
註意:上圖中 同一個 partition 出現在了不同 broker 中是因為實現了 Replication(備份)
kafka 集群角色
Leader
所有的通信都是跟 Leader 進行,當 Leader 寫完數據後,Follower 會自動向 Leader 獲取數據同步
Follwer
當實現副本(Replication 後)會創建 Follwer 用來備份。當 Leader 獲取數據後,會自動向 Leader 同步數據。如果沒有實現副本。那麼每個分區都只會有 Leader,不會有 Follwer。
Kafka 工作流程分析
Kafka 生產過程分析
寫入方式
Producer 採用推 (push)模式將消息發佈到 broker,每條消息都被 append 到分區中(其實是 append 到 partition 文件夾內的 Segment 文件中),屬於順序寫磁碟(順序寫磁碟效率比隨機寫記憶體高,保障 kafka 吞吐率)。
分區
消息發送時都被髮送到一個 topic,其本質就是一個目錄,而 topic 是由一些 Partition Logs(分區日誌)組成,其組織結構如下圖所示。

我們可用看到,每個 Partition 中的消息都是有序的,生產的消息不斷追加到 Partition log 上,其中的每個消息都被賦予了一個唯一的 offset 值。
- 分區的原因
- 方便在集群中擴展,每個 Partition 可以通過調整以適應它所在的機器。而一個 topic 又可以由多個 partition 組成,因此整個集群就可以適應任意大小的數據了
- 可以提高併發量,因為可以以 partition 為單位讀寫了。
- 分區的原則
- 指定 Partition,直接使用
- 未指定 partition 但指定 key,可以通過 key 進行 hash 出一個 partition
- 採用輪詢方法選出一個 partition
副本
同一個 partition 可能有 多個 replication。沒有 replication 的情況下,一旦 broker 宕機,其上所有 partition 的數據都不可被消費,同時 producer 也不能再將消息存於其他 partition。引入 replication 之後,同一個 partition 可能會有多個 replication,而這時需要這些 replication 之間選擇出一個 leader,producer 和 consumer 只與這個 leader 交互,其他 replication 作為 follower 從 leader 中複製數據。
寫入數據
- Producer 先從 zookeeper 的 “brokers/.../state” 節點找到該 partition 的 leader
- producer 將消息發送給該 leader
- leader 將消息寫入本地 log
- followers 從 leader pull 消息,寫入本地 log 後向 leader 發送 ACK
- leader 收到所有 follower 的 ACK 後,向 prodicer 發送 ACK
Broker 保存消息
存儲方式
物理上把 topic 分成一個或者多個 partition,每個 partition 物理上對應一個文件夾(該文件夾存儲該 partition 的所有消息和索引文件)

存儲策略
無論消息是否被消費, kafka 都會保留所有消息。有兩種策略可以刪除舊數據。
- 基於事件
- 基於大小
需要註意的是,因為 Kafka 讀取特定消息的時間複雜度為 O(1),即與文件大小無關,所以這裡刪除過期文件與提高 Kafka 性能無關。
ZooKeeper 存儲結構
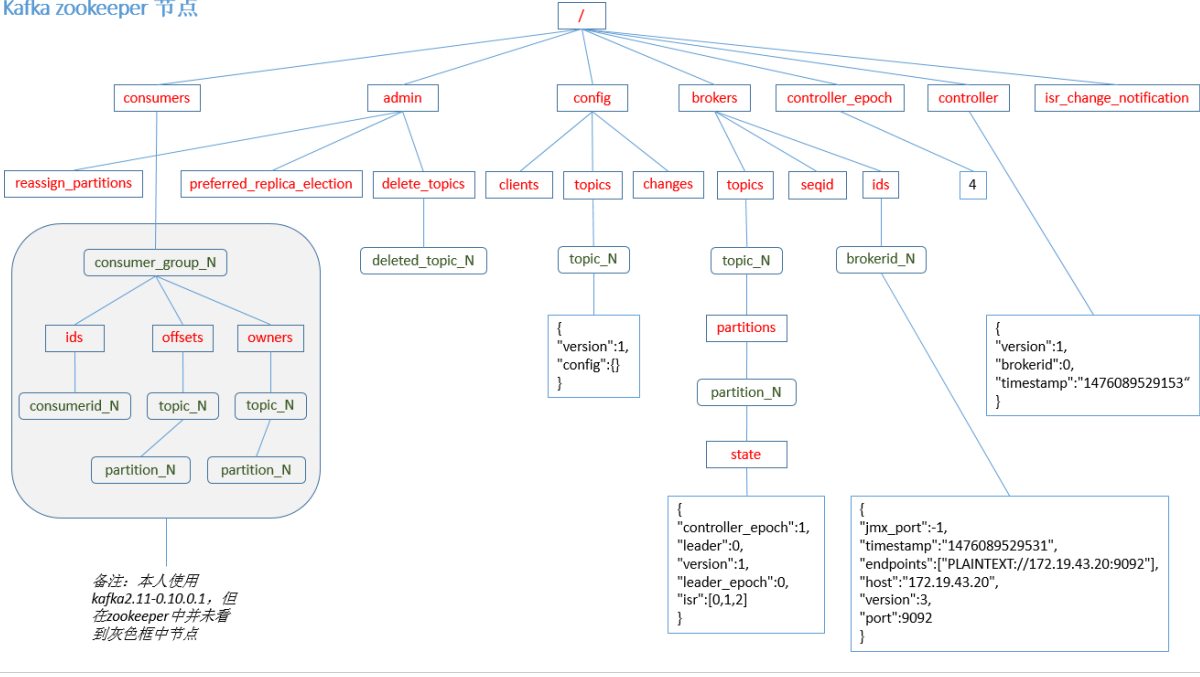
其中由於新版本 kafka 消費者的 offset 存在本地,因此在 zookeeper 中看不到。brokers 節點下的 ids 存放著 brokerid,存放所有 broker 的信息。topics 節點內可以看到每個 topic 的 各個 partition 的具體信息。
註意:producer 不在 zk 中註冊,消費者在 zk 中註冊。
Kafka 消費過程分析
kafka 提供了兩套 consimer API,高級和低級的。
高級 API
- 優點
- 寫起來檢點
- 不需要自行去管理 offset,系統通過 zookeeper 自行管理。
- 不需要管理分區,副本等情況,系統自動管理。
- 消費者斷線後會自動根據上一次記錄在 zookeeper 中的 offset 去接著獲取數據(預設設置 1 分鐘更新一下 zookeeper 中存的 offset)
- 可以使用 group 來區分對同一個 topic 的不同程式訪問分離開來(不同的 group 記錄不同的 offset,這樣不同程式讀取同一個 topic 才不會因為 offset 互相影響)
- 缺點
- 不能自行控制 offset
- 不能細化控制如分區、副本、zk 等
低級 API
- 優點
- 能夠讓開發者自己控制 offset,想從那裡讀取就從哪裡讀取
- 自行控制連接分區,對分區自定義進行負載均衡
- 對 zk 的依賴性降低(offset 不一定非要存在 zk,自行存儲 offset 即可,比如存在文件或者記憶體中)
- 缺點
- 太過複雜,需要自行控制 offset,連接哪個分區,找到分區 leader 等
消費者組
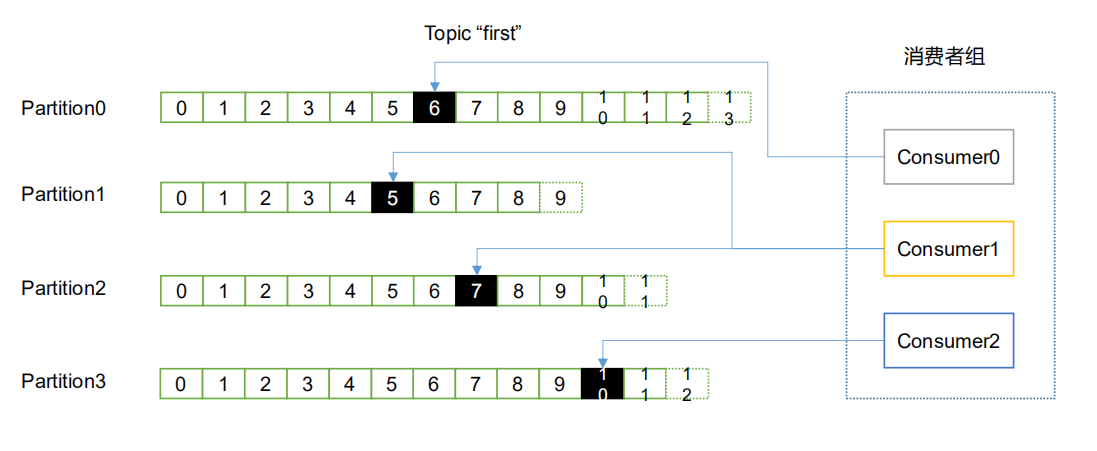
消費者是以 consumer group 消費者組的方式工作,由一個或者多個消費者組成一個組,共同消費一個 topic。每個分區在同一時間只能由 group 內的一個消費者讀取,但是多個 group 可以同時消費這個 partition。在上圖,有一個由三個消費者組成的 group,有一個消費者讀取 topic 中的兩個分區,另外兩個分別讀取一個分區。某個消費者讀取某個分區,也可以叫做某個消費者是某個分區的擁有者。
在這種情況下,消費者可以通過水平擴展方式同時讀取大量的消息。
消費方式
consumer 採用 pull(拉)模式從 broker 中讀取數據。
push 模式很難適應消費速率不同的消費者,因為消息發送速率是由 broker 決定的。它的目標是儘可能以最快速度的傳遞消息,但是這樣很容易造成 consumer 來不及處理消息,容易引起拒絕服務以及網路擁塞。而 pull 模式則是可以根據 consumer 的消費能力以適當的速率消費消息。
對於 kafka 而言,pull 模式更合適,它可以簡化 broker 的設計,consumer 可自主控制消費消息的速率,同時 consumer 可以自己控制消費方式 ------ 批量消費或者逐條消費。
pull 模式不足之處是,如果 kafka 沒有數據,消費者可能會陷入迴圈中,一直等待數據到達。為了避免這種情況,我們在我們的拉請求中有參數,允許消費者請求在等待數據到達的長輪詢中進行阻塞(並且可選地等待到達給定的位元組數,以確保大的傳輸大小)。


