
1. 資料庫操作與存儲引擎 1.1 資料庫和資料庫對象 資料庫對象:存儲,管理和使用數據的不同結構形式,如:表、視圖、存儲過程、函數、觸發器、事件等。 資料庫:存儲資料庫對象的容器。 資料庫分兩種: ①系統資料庫(系統自帶的資料庫):不能修改,不能刪除 information_schema:存儲數據 ...
1. 資料庫操作與存儲引擎
1.1 資料庫和資料庫對象
資料庫對象:存儲,管理和使用數據的不同結構形式,如:表、視圖、存儲過程、函數、觸發器、事件等。
資料庫:存儲資料庫對象的容器。
資料庫分兩種:
①系統資料庫(系統自帶的資料庫):不能修改,不能刪除
information_schema:存儲資料庫對象信息,如:用戶表信息,列信息,許可權,字元,分區等信息。
performance_schema:存儲資料庫伺服器性能參數信息。
mysql:存儲資料庫用戶許可權信息。
test: 任何用戶都可以使用的測試資料庫。
②用戶資料庫(用戶自定義的資料庫):一般的,一個項目一個用戶資料庫。
1.2 查看和選擇資料庫
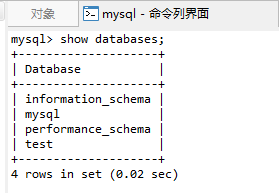
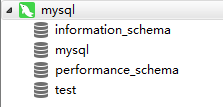
①查看資料庫伺服器存在哪些資料庫:
show databases;
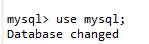
②操作具體的資料庫:
use mysql;(註:mysql為具體的資料庫名)
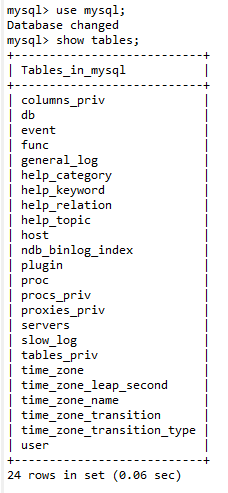
③查看某個資料庫中所有的表:
Show tables;(註:查看的是當前使用的資料庫中的所有表,即必須先進入這個資料庫)
1.3 創建和刪除資料庫
①創建指定名稱的資料庫:
create database testdatabase;(註:testdatabase即為要創建的資料庫的相對於名稱)


②刪除資料庫:
drop database testdatabase;

1.4資料庫存儲引擎的介紹
MySQL中的數據用各種不同的技術存儲在文件(或者記憶體)中。這些技術中的都使用不同的存儲機制、索引技巧、鎖定水平並且最終提供不同的功能和能力。
通過選擇不同的技術,你能夠獲得額外的速度或者功能,從而改善你的應用的整體功能。
事務:針對於一組操作,要麼都成功 要麼都失敗。
MyISAM:擁有較高的插入,查詢速度,但不支持事務,不支持外鍵。
InnoDB:支持事務,支持外鍵,支持行級鎖定,性能較低。
InnoDB 存儲引擎提供了具有提交、回滾和崩潰恢復能力的事務安全。但對比MyISAM,處理效率差,且會占用更多的磁碟空間以保留數據和索引。
2. MySQL常用列類型
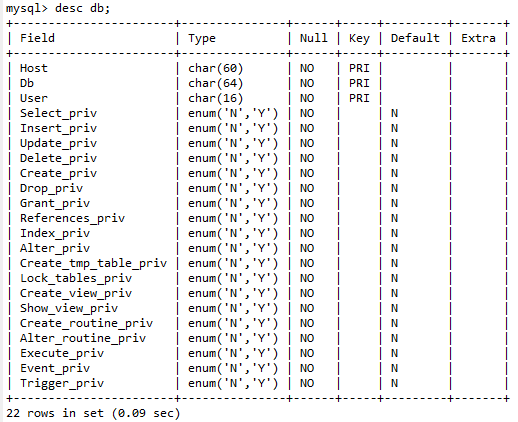
2.1 查看表結構分析列類型
desc db; (註:db指當前所進入的資料庫中的想查看的表)
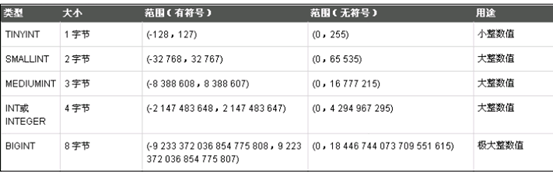
2.2 整型
最常用的整數類型:
INT/BIGINT
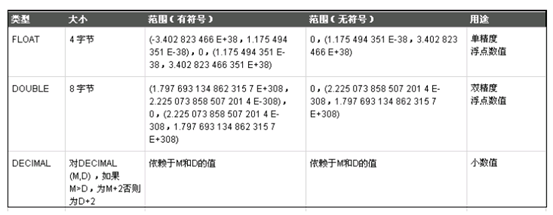
2.3 小數類型
最常用的小數類型:
FLOAT[(s,p)] 、DOUBLE[(s,p)]
小數類型,可存放實型和整型 ,精度(p)和範圍(s),如:double(5,2): 整數和小數一共占5位.其中小數占2位.不夠精確。
精確的小數類型:
DECIMAL(比如銀行 對小數要求比較高情況下使用)
BIGDECIMAL 高精度類型,金額貨幣優先選擇
2.4 字元類型
常用字元類型:
char(size) 定長字元
0 - 255位元組,size指N個字元數,若插入字元數超過設定長度,會被截取並警告。
varchar(size) 變長字元
0 -255位元組,從MySQL5開始支持65535個位元組,若插入字元數超過設定長度,會被截取並警告。(不是越長越好,壓縮很耗費時間)
char和varchar長度都是255,那char 和 varchar 的區別:
比如 定義char(100),若字元只是占了2個,其他98個也是占用;
char好處:大小固定,不用壓縮空間,速度更快一些;
而定義varchar(100),如果只占2個,那它總共就占2個;
保存超長字元類型:
TEXT系列類型,可以保存文章的純文本,一般用於存儲大量的字元串。

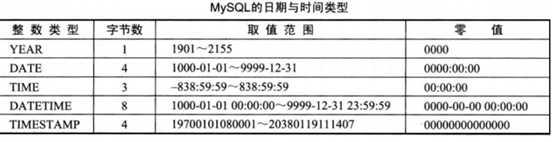
2.5 日期類型
常用的日期時間類型:
DATE(年月 日)
DATETIME(年月日,時分秒)
TIMESTAMP(時間戳--範圍19700101080001 - 203801191111407 基本不會用它,瞭解)
TIME和YEAR
註意:在MySQL中,日期時間值使用單引號引起來。
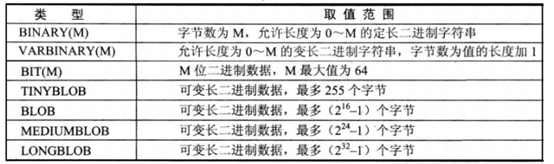
2.6二進位類型
為什麼存放二進位?
項目中可能會需要保存圖片,保存電影,這就需要使用到二進位類型。因為資料庫中沒有圖片類型和電影類型,需要使用二進位流的形式存進來,讀取也通過流來;
開發中,我們一般存儲二進位類型保存(圖片、視頻)文件路徑。
常用的二進位類型:
BIT:我們一般存儲0或1,相當於Java中的boolean/Boolean類型的值。
在mysql中沒有boolean類型 ,可以使用Bit替代;
BLOB:保存的時候,根據自己的大小,選擇使用的類型.一般使用BLOB就夠用了。
建議:今後的項目,不要把大的文件存放到資料庫,如果文件太大,會影響查詢和修改的速度,還有備份資料庫的時候,也很慢.
如果還是有這樣的需求,還是要保存圖片,保存電影,怎麼辦?
通過IO流寫到磁碟上,然後再資料庫上面保存路徑;
BINARY、VARBINARY、TINYBLOB、BLOB、MEDIUMBLOB、LONGBLOB:
存放圖形、聲音和影像,二進位對象,0-4GB。
3. 表操作SQL語句
3.1 創建表
語法:
create table 表名 (
列名1 列的類型 [約束],
列名2 列的類型 [約束],
列名3 列的類型 [約束],
……
列名N 列的類型 [約束],
);

如使用以上語句即可創建對應如下4列的約束表單:

3.2 刪除表
語法:
drop table 表名;

3.3 修改表
語法:
alter table 表名稱 modify 欄位名稱 欄位類型 [是否允許非空];
如需修改mytable表中的name列長度為40並設置預設為null:

對應執行SQL語句為:
alter table mytable modify name varchar(40) default NULL;
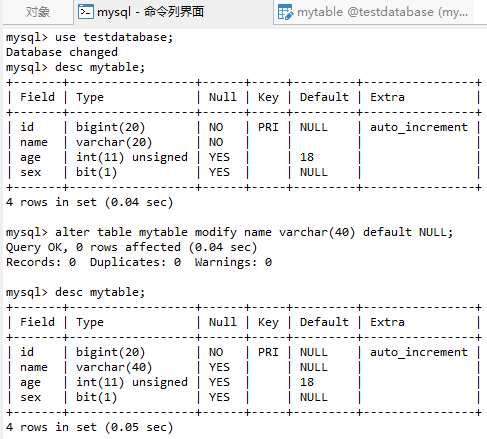
3.4 查看表結構
語法:
desc 表名;
3.5查看表的約束
語法:
show create table 表名;(可以查看表結構,對應創建表SQL語句)
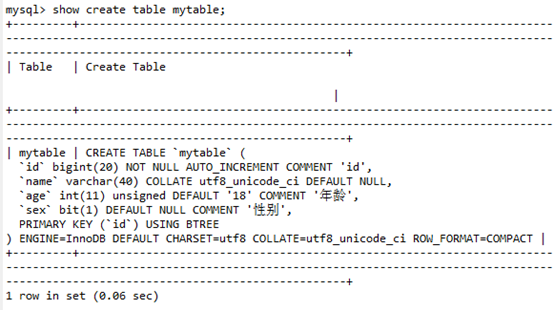
具體可見表中可以有如下表約束:
3.5.1 非空約束
①非空約束-- NOT NULL,不允許某列的內容為空。
3.5.2 列預設值
②設置列預設值-- DEFAULT 預設值。
3.5.3 唯一約束
③唯一約束-- UNIQUE,在該表中,該列的內容必須唯一。

註意:

3.5.4 主鍵約束
④主鍵約束-- PRIMARY KEY, 非空且唯一;主鍵自增長:AUTO_INCREMENT,從1開始,步長為1。
主鍵設計需知:
1:單欄位主鍵:單列作為主鍵,建議使用。(一般來說名字為id)
複合主鍵:使用多列充當主鍵,不建議。(比如用戶名+身份證+電話號碼(表示唯一) )
2:主鍵分為兩種:
1)自然主鍵: 使用有業務含義的列作為主鍵(不推薦使用);(這個主鍵是有意義,比如身份證、用戶名、電話號碼、駕駛證)
2)代理主鍵: 使用沒有業務含義的列作為主鍵(推薦使用); (這個主鍵是沒有任何意義,只要這列非空且唯一就行)
註意: 一般做項目都是使用代理主鍵,如果你用自然主鍵,比如身份證,它必須非空且唯一,隨著業務的發展,一個人可能出現多個號,那身份證可能重覆。由於代理主鍵沒有意義,完全不需要我們來維護 -- 讓它自動生成即可。另外,創建一張表 ,必須有主鍵,如果沒有主鍵,可以認為這張表不合格。
3.5.5 外鍵約束
⑤外鍵約束—FOREIGN KEY
A表中的外鍵列. A表中的外鍵列的值必須參照於B表中的某一列(B表主鍵)
4. 表的查詢SQL
4.1 簡單查詢
4.1.1 簡單數據查詢
語法:
select *(列名1, 列名2…) from 表名;
如查詢product商品表中的信息需求:
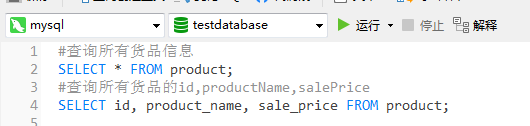
結果分別如下:

4.1.2 避免重覆數據-DISTINCT
語法:
select distinct 列名1, 列名2,...
from 表名;
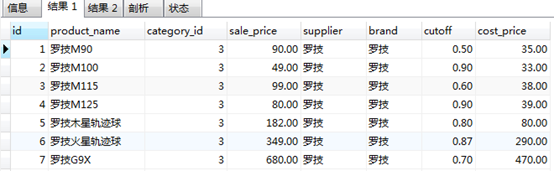
如:#查詢商品的分類編號
SELECT DISTINCT category_id FROM product;

4.1.3實現數學運算查詢+別名設置
對NUMBER型數據可以使用算數操作符創建表達式(+ - * /)
對DATE型數據可以使用部分算數操作符創建表達式 (+ -)
對列進行別名設置使用as + 別名,或直接在列後空格+ 別名,別名使用’’;
如:
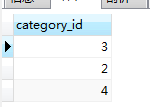
#查詢所有貨品的id,名稱和批發價(批發價=賣價*折扣)
SELECT id, product_name, sale_price*cutoff as '批發價' FROM product;
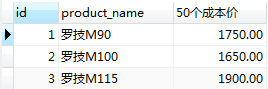
#查詢所有貨品的id,名稱,和各進50個的成本價(成本=cost_price)
SELECT id, product_name, cost_price*50 as '50個成本價' FROM product;
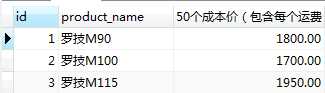
#查詢所有貨品的id,名稱,各進50個,並且每個運費1元的成本
SELECT id, product_name, (cost_price+1)*50 as '50個成本價(包含每個運費1元)' FROM product;
註:其中as可以省略;

4.1.4 設置顯示格式查詢
為方便用戶瀏覽查詢的結果數據,有時需要設置顯示格式,可以使用CONCAT函數來連接字元串。
如:
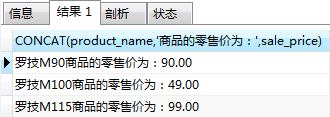
#查詢商品的名字和零售價(sale_price)--(CONCAT)
#格式:xxx商品的零售價為:xxx
SELECT CONCAT(product_name,'商品的零售價為:',sale_price) FROM product;

4.2過濾查詢
4.2.1比較運算符
在MySQL表中查詢條件中數值列或字元列可以使用如下運算符作為限定條件:

如:
#查詢貨品零售價為119的所有貨品信息
SELECT * FROM product WHERE sale_price = 119;


#查詢貨品名為羅技G9X的所有貨品信息
SELECT * FROM product WHERE product_name = '羅技G9X';


#查詢貨品名 不為 羅技G9X的所有貨品信息
SELECT * FROM product WHERE product_name != '羅技G9X';


#查詢分類編號不等於2的貨品信息
SELECT * FROM product WHERE category_id <> 2;


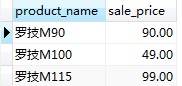
#查詢貨品名稱,零售價小於等於200的貨品
SELECT product_name, sale_price FROM product WHERE sale_price <= 200;

#查詢id,貨品名稱,批發價(sale price*cutoff)大於350的貨品,註:這裡WHERE後不能使用'批發價'查詢
SELECT id, product_name, sale_price*cutoff as '批發價' FROM product WHERE sale_price*cutoff > 350;


註意:因為這裡執行順序是先執行where後面的條件過濾,再執行查詢select看那些列數據是符合條件的。Where --> select
4.2.2邏輯運算符

如:
#選擇id,貨品名稱,批發價(saleprice*cutoff)在300-400之間的貨品
SELECT id, product_name, sale_price*cutoff as '批發價' FROM product WHERE sale_price*cutoff > 300 AND sale_price*cutoff < 400;
SELECT id, product_name, sale_price*cutoff as '批發價' FROM product WHERE sale_price*cutoff > 300 && sale_price*cutoff < 400;

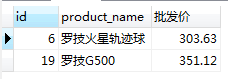
#選擇id,貨品名稱,分類編號為2,4的所有貨品
SELECT id, product_name, category_id FROM product WHERE category_id = 2 or category_id = 4;
SELECT id, product_name, category_id FROM product WHERE category_id = 2 || category_id = 4;
SELECT id, product_name, category_id FROM product WHERE category_id in (2, 4);

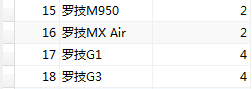
#選擇id,貨品名稱,分類編號不為2的所有商品
SELECT id, product_name, category_id FROM product WHERE category_id != 2;
SELECT id, product_name, category_id FROM product WHERE NOT category_id = 2;


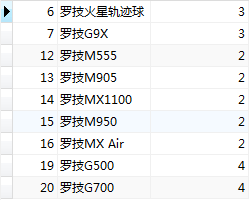
#選擇id,貨品名稱,分類編號並且貨品零售價(sale_price)大於等於250或者是成本(cost_price)大於等於200
SELECT id, product_name, category_id FROM product WHERE sale_price >= 250 OR cost_price >= 200;
SELECT id, product_name, category_id FROM product WHERE sale_price >= 250 || cost_price >= 200;

4.2.3優先順序規則
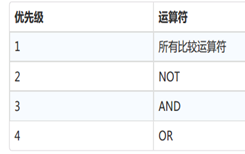
註意:括弧將跨越所有優先順序規則
4.2.4範圍查詢-BETWEEN AND
使用BETWEEN運算符顯示某一值域範圍的記錄,這個操作符最常見的使用在數字類型數據的範圍上,
但對於字元類型數據和日期類型數據同樣可用。
語法:
Where 列名 between minvalue and maxvalue
註意:
between 的範圍是包含兩邊的邊界值
eg: id between 3 and 7 等價與 id >=3 and id<=7
not between 的範圍是不包含邊界值
eg:id not between 3 and 7 等價與 id <3 or id>7
如:
#選擇id,貨品名稱,批發價在300-400之間的貨品
SELECT id, product_name, sale_price*cutoff as '批發價' FROM product WHERE sale_price*cutoff BETWEEN 300 AND 400;

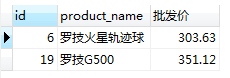
#選擇id,貨品名稱,批發價不在300-400之間的貨品
SELECT id, product_name, sale_price*cutoff as '批發價' FROM product WHERE sale_price*cutoff NOT BETWEEN 300 AND 400;


4.2.5集合查詢-in
使用IN運算符,判斷列的值是否在指定的集合中。
語法:
where 列名 in (值1, 值2);
如:
#選擇id,貨品名稱,分類編號為2,4的所有貨品
SELECT id, product_name, category_id FROM product WHERE category_id IN (2, 4);
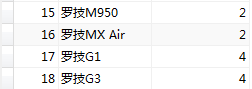
#選擇id,貨品名稱,分類編號不為2,4的所有貨品
SELECT id, product_name, category_id FROM product WHERE category_id NOT IN (2, 4);
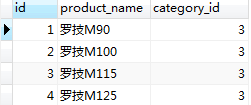
4.2.6空值查詢-IS NULL
IS NULL:判斷列的值是否為空。
語法:
where 列名 is null
註意:查詢是否為NULL不能用=;
如:
#查詢商品名為不為NULL的所有商品
SELECT * FROM product WHERE product_name is NOT NULL;

4.2.7模糊查詢-LIKE
使用LIKE運算符執行通配查詢,查詢條件可包含文字字元或數字:
通配符:用來實現匹配部分值的特殊字元。
%通配符:可表示零或多個字元。
_通配符:可表示一個字元。
__通配符:可表示兩個字元。
語法:
where 列名 like ‘%’(或者_或者__)
如:
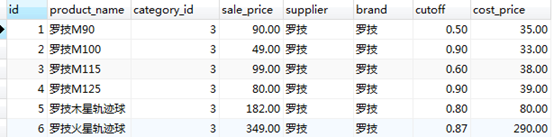
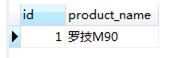
#查詢id,貨品名稱,貨品名稱匹配'%羅技M9_'
SELECT id, product_name FROM product WHERE product_name LIKE '%羅技M9_';
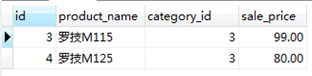
#查詢id,貨品名稱,分類編號,零售價大於等於50並且貨品名稱匹配'%羅技M1__
SELECT id, product_name, category_id, sale_price FROM product WHERE sale_price >= 50 AND product_name LIKE '%羅技M1__';


4.3結果排序
使用 ORDER BY 子句將記錄排序
ASC : 升序,預設。
DESC: 降序。
ORDER BY 子句出現在SELECT語句的最後。
語法:
select *(列1,列2,…列N) from 表名 where 條件 order by 列名1 [ASC/DESC], 列名2 [ASC/DESC]
如:
#查詢M系列並按照批發價排序(加上別名),預設ASC升序,可以省略
SELECT id, product_name, sale_price*cutoff as '批發價'
FROM product WHERE product_name LIKE '%M%'
ORDER BY sale_price*cutoff ASC;


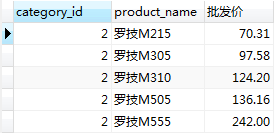
#查詢分類為2的商品並按照批發價排序(加上別名),可以使用中文別名排序,因為ORDER BY在最後
SELECT category_id, product_name, sale_price*cutoff as '批發價'
FROM product WHERE category_id = 2
ORDER BY '批發價' DESC;

4.4分頁查詢LIMIT
對select * from product得出的結果進行分頁顯示,每頁顯示固定條數。
語法:
select 列1, 列2...
from 表名
[where 條件]
limit beginIndex, pageSize;
beginIndex:是開始索引(從0開始):第一條記錄:0,第二條記錄:1
pageSize:每頁顯示多少條數據
beginIndex = (當前頁數 - 1) * pageSize
如:
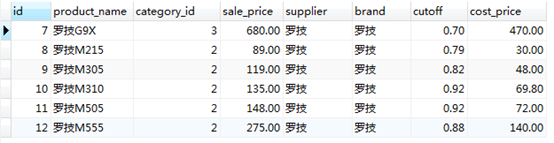
#每頁6條數據,要查詢前3頁,LIMIT pageIndex, pageSize
SELECT * FROM product LIMIT 0, 6;
SELECT * FROM product LIMIT 6, 6;
SELECT * FROM product LIMIT 12, 6;

註意:LIMIT後面沒有()
4.5聚集函數
聚集函數作用於一組數據,並對一組數據返回一個值。
比如,2,4,6,7,8 一組數據中,最大數8,最小數2,一共多少數 5個,它們的總和27,平均數27/5 ,mysql中聚集函數就完成上面的功能
常見的聚集函數如下:
COUNT:統計結果記錄數
MAX:
統計計算最大值
MIN:
統計計算最小值
SUM:
統計計算求和
AVG:
統計計算平均值
具體使用如下:
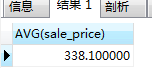
#查詢所有商品平均零售價
SELECT AVG(sale_price) FROM product;

#查詢商品總記錄數
SELECT COUNT(id) FROM product;


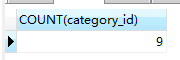
查詢分類為2的商品總數
SELECT COUNT(category_id) FROM product WHERE category_id = 2;

#查詢商品的最小零售價,最高零售價,以及所有商品零售價總和
SELECT MIN(sale_price), MAX(sale_price), SUM(sale_price) FROM product;


註意:使用聚集函數的時候,不要添加列名
4.6分組查詢GROUP BY
Group by --- group表示組,by 依靠什麼分組;
可以使用GROUP BY 子句將表中的數據分成若幹組,再對分組之後的數據做統計計算,一般使用聚集函數才使用GROUP BY.
語法:
select 聚集函數 from 表名 where 條件 group by having 分組後的條件
註意:GROUP BY 後面的列名的值要有重覆性出現,分組才有意義。
使用HAVING字句,對分組之後的結果作篩選。
不能在
WHERE 子句中使用組函數(註意)。
可以在
HAVING 子句中使用組函數。
如:
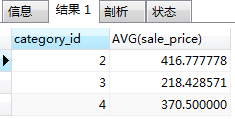
#查詢每個商品分類編號和每個商品分類各自的平均零售價(求2,3,4每類商品的平均零售價)
SELECT category_id,AVG(sale_price) FROM product GROUP BY category_id;

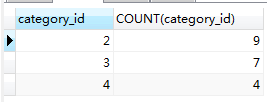
#查詢每個商品分類編號和每個商品分類各自的商品總數。(求2,3,4每類商品的總數)
SELECT category_id,COUNT(category_id) FROM product GROUP BY category_id;

#查詢每個商品分類編號和每個商品分類中零售價大於100的商品總數:
SELECT category_id, COUNT(*) FROM product WHERE sale_price > 100 GROUP BY category_id;


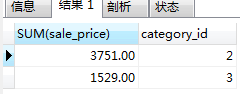
#查詢零售價總和大於1500的 商品分類編號以及總零售價和;(根據分類編號查零售價的總和,然後零售價總和大於1500)
SELECT SUM(sale_price), category_id FROM product GROUP BY category_id HAVING SUM(sale_price) > 1500;

什麼時候用where,什麼時候用having?
Where 是先過濾已有的數據(數據是已經存在的),在進行分組,在聚集計算
Having 先分組,在對每組進行計算,根據得到結果再過濾(分組把數據算出之後,再過濾)
4.7Select語句總體執行順序
1.from語句----2.where語句----3.group by語句----4.having語句----5.select語句----6.order by語句,根據目前1-4章節總結。
更詳細的總體執行順序:
(1)from
(2) join
(3) on
(4) where
(5)group by(開始使用select中的別名,後面的語句中都可以使用)
(6) avg,sum....
(7)having
(8) select
(9) distinct
(10) order by

