
1.儘量在合適的場合使用單例 使用單例可以減輕載入的負擔,縮短載入的時間,提高載入的效率,但並不是所有地方都適用於單例,簡單來說,單例主要適用於以下三個方面: 控制資源的使用,通過線程同步來控制資源的併發訪問; 控制實例的產生,以達到節約資源的目的; 控制數據共用,在不建立直接關聯的條件下,讓多個不 ...
1.儘量在合適的場合使用單例
使用單例可以減輕載入的負擔,縮短載入的時間,提高載入的效率,但並不是所有地方都適用於單例,簡單來說,單例主要適用於以下三個方面:
- 控制資源的使用,通過線程同步來控制資源的併發訪問;
- 控制實例的產生,以達到節約資源的目的;
- 控制數據共用,在不建立直接關聯的條件下,讓多個不相關的進程或線程之間實現通信。
2.儘量避免隨意使用靜態變數
要知道,當某個對象被定義為static變數所引用,那麼GC通常是不會回收這個對象所占有的記憶體,如:
此時靜態變數b的生命周期與A類同步,如果A類不會卸載,那麼b對象會常駐記憶體,直到程式終止。
3.儘量避免過多過常的創建Java對象
儘量避免在經常調用的方法,迴圈中new對象,由於系統不僅要花費時間來創建對象,而且還要花時間對這些對象進行垃圾回收和處理,在我們可以控制的範圍內,最大限度的重用對象,最好能用基本的數據類型或數組來替代對象。
4.儘量使用final修飾符
帶有final修飾符的類是不可派生的。在JAVA核心API中,有許多應用final的例子,例如java.lang.String,為String類指定final防止了使用者覆蓋length方法。另外,如果一個類是final的,則該類所有方法都是final的。java編譯器會尋找機會內聯(inline)所有的final方法(這和具體的編譯器實現有關)。此舉能夠使性能平均提高50%。
如:讓訪問實例內變數的getter/setter方法變成”final:
簡單的getter/setter方法應該被置成final,這會告訴編譯器,這個方法不會被重載,所以,可以變成”inlined”,例子:

5.儘量使用局部變數
調用方法時傳遞的參數以及在調用中創建的臨時變數都保存在棧(Stack)中,速度較快。其他變數,如靜態變數,實例變數等,都在堆(Heap)中創建,速度較慢。
6.儘量處理好包裝類型和基本類型兩者的使用場所
雖然包裝類型和基本類型在使用過程中是可以相互轉換,但它們兩者所產生的記憶體區域是完全不同的,基本類型數據產生和處理都在棧中處理,包裝類型是對象,是在堆中產生實例。在集合類對象,有對象方面需要的處理適用包裝類型,其他的處理提倡使用基本類型。
7.慎用synchronized,儘量減小synchronize的方法
都知道,實現同步是要很大的系統開銷作為代價的,甚至可能造成死鎖,所以儘量避免無謂的同步控制。synchronize方法被調用時,直接會把當前對象鎖 了,在方法執行完之前其他線程無法調用當前對象的其他方法。所以synchronize的方法儘量小,並且應儘量使用方法同步代替代碼塊同步。
8.儘量不要使用finalize方法
實際上,將資源清理放在finalize方法中完成是非常不好的選擇,由於GC的工作量很大,尤其是回收Young代記憶體時,大都會引起應用程式暫停,所以再選擇使用finalize方法進行資源清理,會導致GC負擔更大,程式運行效率更差。
9.儘量使用基本數據類型代替對象
String str = “hello”;
上面這種方式會創建一個“hello”字元串,而且JVM的字元緩存池還會緩存這個字元串;
String str = new String(“hello”);
此時程式除創建字元串外,str所引用的String對象底層還包含一個char數組,這個char數組依次存放了h,e,l,l,o
10.多線程在未發生線程安全前提下應儘量使用HashMap、ArrayList
HashTable、Vector等使用了同步機制,降低了性能。
11.儘量合理的創建HashMap
當你要創建一個比較大的hashMap時,充分利用這個構造函數
避免HashMap多次進行了hash重構,擴容是一件很耗費性能的事,在預設中initialCapacity只有16,而loadFactor是 0.75,需要多大的容量,你最好能準確的估計你所需要的最佳大小,同樣的Hashtable,Vectors也是一樣的道理。
12.儘量減少對變數的重覆計算
如:應該改為
並且在迴圈中應該避免使用複雜的表達式,在迴圈中,迴圈條件會被反覆計算,如果不使用複雜表達式,而使迴圈條件值不變的話,程式將會運行的更快。
13.儘量在finally塊中釋放資源
程式中使用到的資源應當被釋放,以避免資源泄漏。這最好在finally塊中去做。不管程式執行的結果如何,finally塊總是會執行的,以確保資源的正確關閉。
14.儘量使用移位來代替’a/b’的操作
“/”是一個代價很高的操作,使用移位的操作將會更快和更有效
15.儘量確定StringBuffer的容量
StringBuffer 的構造器會創建一個預設大小(通常是16)的字元數組。在使用中,如果超出這個大小,就會重新分配記憶體,創建一個更大的數組,並將原先的數組複製過來,再 丟棄舊的數組。在大多數情況下,你可以在創建 StringBuffer的時候指定大小,這樣就避免了在容量不夠的時候自動增長,以提高性能。
16.儘量早釋放無用對象的引用
大部分時,方法局部引用變數所引用的對象 會隨著方法結束而變成垃圾,因此,大部分時候程式無需將局部,引用變數顯式設為null。例如:
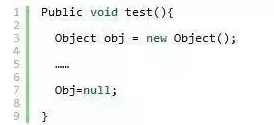

上面這個就沒必要了,隨著方法test的執行完成,程式中obj引用變數的作用域就結束了。但是如果是改成下麵:


這時候就有必要將obj賦值為null,可以儘早的釋放對Object對象的引用。
17.儘量避免使用二維數組
二維數據占用的記憶體空間比一維數組多得多,大概10倍以上。
18.儘量避免使用split
除非是必須的,否則應該避免使用split,split由於支持正則表達式,所以效率比較低,如果是頻繁的幾十,幾百萬的調用將會耗費大量資源,如果確實需要頻繁的調用split,可以考慮使用apache的StringUtils.split(string,char),頻繁split的可以緩存結果。
19.ArrayList & LinkedList
一個是線性表,一個是鏈表,一句話,隨機查詢儘量使用ArrayList,ArrayList優於LinkedList,LinkedList還要移動指針,添加刪除的操作LinkedList優於ArrayList,ArrayList還要移動數據,不過這是理論性分析,事實未必如此,重要的是理解好2者得數據結構,對症下藥。
20.儘量使用System.arraycopy 代替通過來迴圈複製數組
System.arraycopy 要比通過迴圈來複制數組快的多
21.儘量緩存經常使用的對象
儘可能將經常使用的對象進行緩存,可以使用數組,或HashMap的容器來進行緩存,但這種方式可能導致系統占用過多的緩存,性能下降,推薦可以使用一些第三方的開源工具,如EhCache,Oscache進行緩存,他們基本都實現了FIFO/FLU等緩存演算法。
22.儘量避免非常大的記憶體分配
有時候問題不是由當時的堆狀態造成的,而是因為分配失敗造成的。分配的記憶體塊都必須是連續的,而隨著堆越來越滿,找到較大的連續塊越來越困難。
23.慎用異常
當創建一個異常時,需要收集一個棧跟蹤(stack track),這個棧跟蹤用於描述異常是在何處創建的。構建這些棧跟蹤時需要為運行時棧做一份快照,正是這一部分開銷很大。當需要創建一個 Exception 時,JVM 不得不說:先別動,我想就您現在的樣子存一份快照,所以暫時停止入棧和出棧操作。棧跟蹤不只包含運行時棧中的一兩個元素,而是包含這個棧中的每一個元素。
如果您創建一個 Exception ,就得付出代價。好在捕獲異常開銷不大,因此可以使用 try-catch 將核心內容包起來。從技術上講,您甚至可以隨意地拋出異常,而不用花費很大的代價。招致性能損失的並不是 throw 操作——儘管在沒有預先創建異常的情況下就拋出異常是有點不尋常。真正要花代價的是創建異常。幸運的是,好的編程習慣已教會我們,不應該不管三七二十一就拋出異常。異常是為異常的情況而設計的,使用時也應該牢記這一原則。
24.儘量重用對象
特別是String對象的使用中,出現字元串連接情況時應使用StringBuffer代替,由於系統不僅要花時間生成對象,以後可能還需要花時間對這些對象進行垃圾回收和處理。因此生成過多的對象將會給程式的性能帶來很大的影響。
25.不要重覆初始化變數
預設情況下,調用類的構造函數時,java會把變數初始化成確定的值,所有的對象被設置成null,整數變數設置成0,float和double變數設置成0.0,邏輯值設置成false。當一個類從另一個類派生時,這一點尤其應該註意,因為用new關鍵字創建一個對象時,構造函數鏈中的所有構造函數都會被自動調用。
這裡有個註意,給成員變數設置初始值但需要調用其他方法的時候,最好放在一個方法比如initXXX中,因為直接調用某方法賦值可能會因為類尚未初始化而拋空指針異常,如:public int state = this.getState;
26.在java+Oracle的應用系統開發中
在java+Oracle的應用系統開發中,java中內嵌的SQL語言應儘量使用大寫形式,以減少Oracle解析器的解析負擔。
27.I/O流操作
在java編程過程中,進行資料庫連接,I/O流操作,在使用完畢後,及時關閉以釋放資源。因為對這些大對象的操作會造成系統大的開銷。
28.創建對象會消耗系統的大量記憶體
過分的創建對象會消耗系統的大量記憶體,嚴重時,會導致記憶體泄漏,因此,保證過期的對象的及時回收具有重要意義。JVM的GC並非十分智能,因此建議在對象使用完畢後,手動設置成null。
29.在使用同步機制時
在使用同步機制時,應儘量使用方法同步代替代碼塊同步。
30.不要在迴圈中使用Try/Catch語句,應把Try/Catch放在迴圈最外層
Error是獲取系統錯誤的類,或者說是虛擬機錯誤的類。不是所有的錯誤Exception都能獲取到的,虛擬機報錯Exception就獲取不到,必須用Error獲取。
31.通過StringBuffer的構造函數來設定他的初始化容量,可以明顯提升性能
StringBuffer的預設容量為16,當StringBuffer的容量達到最大容量時,她會將自身容量增加到當前的2倍+2,也就是2*n+2。無論何時,只要StringBuffer到達她的最大容量,她就不得不創建一個新的對象數組,然後複製舊的對象數組,這會浪費很多時間。所以給StringBuffer設置一個合理的初始化容量值,是很有必要的!
32.合理使用java.util.Vector
Vector與StringBuffer類似,每次擴展容量時,所有現有元素都要賦值到新的存儲空間中。Vector的預設存儲能力為10個元素,擴容加倍。
vector.add(index,obj) 這個方法可以將元素obj插入到index位置,但index以及之後的元素依次都要向下移動一個位置(將其索引加 1)。 除非必要,否則對性能不利。同樣規則適用於remove(int index)方法,移除此向量中指定位置的元素。將所有後續元素左移(將其索引減 1)。返回此向量中移除的元素。所以刪除vector最後一個元素要比刪除第1個元素開銷低很多。刪除所有元素最好用removeAllElements方法。
如果要刪除vector里的一個元素可以使用 vector.remove(obj);而不必自己檢索元素位置,再刪除,如int index = indexOf(obj);vector.remove(index);
33.不用new關鍵字創建對象的實例
用new關鍵詞創建類的實例時,構造函數鏈中的所有構造函數都會被自動調用。但如果一個對象實現了Cloneable介面,我們可以調用她的clone方法。clone方法不會調用任何類構造函數。
下麵是Factory模式的一個典型實現:
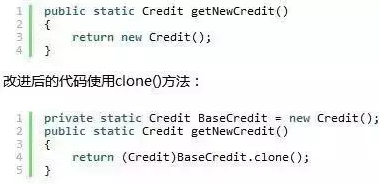
34.HaspMap的遍歷
利用散列值取出相應的Entry做比較得到結果,取得entry的值之後直接取key和value。
————END————



