
MySQL 主從架構已經被廣泛應用,保障主從複製關係的穩定性是大家一直關註的焦點。MySQL 5.6 針對主從複製穩定性提供了新特性: slave 支持 crash-safe。該功能可以解決之前版本中系統異常斷電可能導致 relay_log.info 位點信息不准確的問題。 本文將從原理,參數,新的... ...

一 前言
MySQL 主從架構已經被廣泛應用,保障主從複製關係的穩定性是大家一直關註的焦點。MySQL 5.6 針對主從複製穩定性提供了新特性: slave 支持 crash-safe。該功能可以解決之前版本中系統異常斷電可能導致 relay_log.info 位點信息不准確的問題。
本文將從原理,參數,新的問題等幾個方面對該特性進行介紹。
二 crash-unsafe
在瞭解 slave crash-safe 之前,我們先分析 MySQL 5.6 之前的版本出現 slave crash-unsafe 的原因。我們知道在一套主從結構體系中,slave 包含兩個線程:即 IO thread 和 SQL thread。兩個線程的執行進度(偏移量)都保存在文件中。
IO thread 負責從 master 拉取 binlog 文件並保存到本地的 relay-log 文件中。SQL thread 負責執行重覆 sql,執行 relay-log 記錄的日誌。
crash-unsafe 情況下 SQL_thread 的 的工作模式:
START TRANSACTION; Statement 1 ... Statement N COMMIT; Update replication info files (master.info, relay_log.info)
IO thread 的執行狀態信息保存在 master.info 文件, SQL thread 的執行狀態信息保存在 relay-log.info 文件。slave 運行正常的情況下,記錄位點沒有問題。但是每當系統發生 crash,存儲的偏移量可能是不准確的(需要註意的是這些文件被修改後不是同步寫入磁碟的)。因為應用 binlog 和更新位點信息到文件並不是原子操作,而是兩個獨立的步驟。比如 SQL thread 已經應用 relay-log.01 的4個事務
trx1(pos:10) trx2(pos:20) trx3(pos:30) trx4(pos:40)
但是 SQL thread 更新位點 (relay-log.01,30) 到 relay-log.info 文件中,slave 實例重啟的時候 sql thread 會重覆執行事務 trx4,於是乎,大家就看到比較常見的複製報錯 error 1062,error 1032。
MySQL 5.5 通過兩個參數來緩解該問題,使用 sync_master_info=1 和sync_replay_log_info=1 來保證 Slave 的兩個線程每次寫一個事務就分別向兩個文件同步一次 IO thread 和 SQL thread 當前執行的位點信息。當然同步操作不是免費的,頻繁更新磁碟文件需要消耗性能。
但是,即使設置了 sync_master_info=1 和 sync_relay_info=1,問題還是會出現,因為複製信息是在 transactions 提交後寫入的,如果 crash 發生在事務提交和 OS 寫文件之間,那麼 relay-log.info 就可能是錯誤的。當 slave 從新啟動的時候,最後那個事務可能會被執行兩次.具體的影響取決於事務的具體操作.複製可能會繼續運行比如 update/delete,或者報錯 比如 insert 操作,此時主從數據的一致性可能會被破壞。
三 crash-safe 特性
3.1 保障 apply log 和更新位點信息操作的原子性
通過上面的分析,我們知道 slave crash-unsafe 的原因在於應用 binlog 和更新文件的非原子性。MySQL 5.6 版本通過將更新位點信息存放到表中,並且和正常的事務一起執行,進而保障 apply binlog 的事務和更新 relay info 信息到 slave_relay_log_info 的原子性.
就是把 SQL thread 執行事務和更新 mysql.slave_replay_log_info 的語句合併為同一個事務,由 MySQL 系統來保障事務的原子性。我們可以通過偽代碼來模擬 crash-safe 的原理:crash-safe 情況下 SQL_thread 的工作模式
START TRANSACTION; Statement 1 ... Statement N Update replication info COMMIT
一圖勝千言:
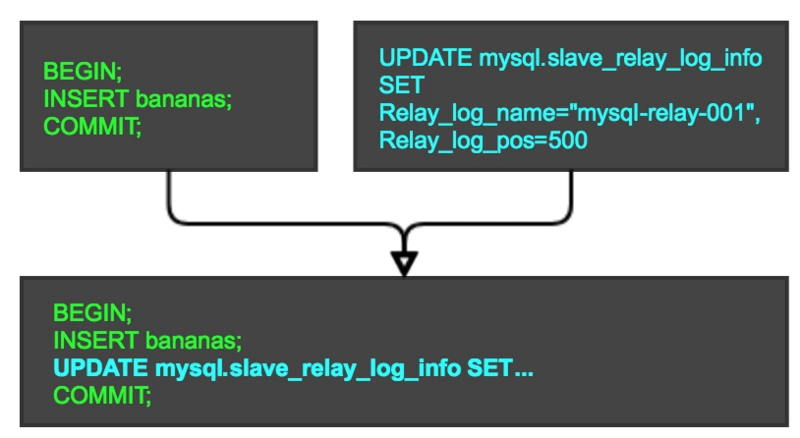
綠色的代表實際業務的事務,藍色的是開啟 MySQL 執行的更新slave_replay_log_info 相關位點信息的 sql ,然後將這兩個 sql 合併在一個事務中執行,利用 MySQL 事務機制和 InnoDB 表保障原子性。不會出現應用 binlog 和更新位點信息兩個動作割裂導致不一致的問題。
3.2 crash 後的恢復動作
通過設置 relay_log_recovery = ON,slave 遇到異常 crash,然後重啟的時候,系統會刪除現有的 relay log,然後 IO thread 會從 mysql.slave_replay_log_info 記錄的位點信息重新拉取主庫的 binlog。MySQL 如此設計的出發點是:
- SQL thread apply binlog 的位點永遠小於等於 IO thread 從主庫拉取的位點。
- SQL thread 記錄的位點是已經執行並且提交的事務之後位點信息。
一圖勝千言:
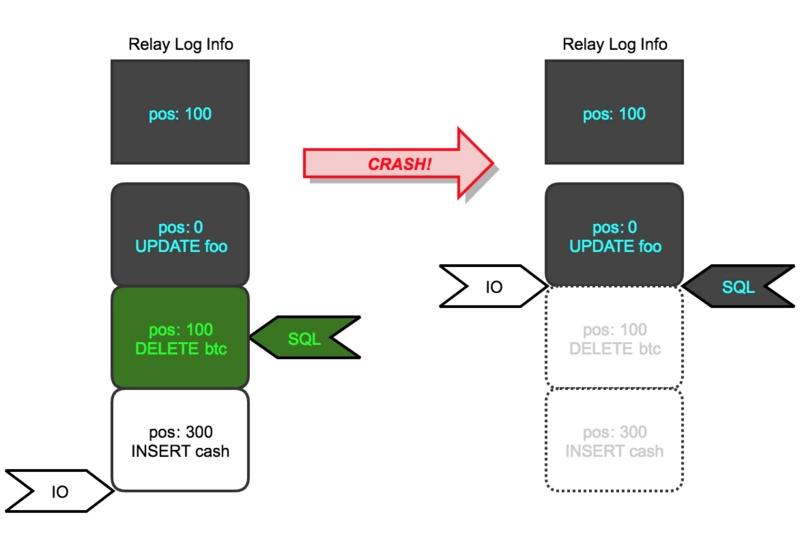
藍色的 update 語句代表已經執行並提交的事務,綠色的 delete 語句表示正在執行的 sql,還未提交。此時 slave_replay_log_info 表記錄的 relay log info是**update 語句結束,delete 語句開始之前的位點
(relay_log.01,100)** 。如果遇到系統 crash,slave 實例重啟之後,會刪除已經有的 relaylog,並且 IO thread 會從(relay_log.01,100)對應的 master binlog 位點重新拉取主庫的 binlog,SQL thread 也會從這個位點開始應用 binlog。
3.3 GTID 模式下的 crash safe
和基於位點的複製不同,GTID 模式下使用新的複製協議 COM_BINLOG_DUMP_GTID 進行複製。舉個

