
一、MySQL可重覆讀級別下,因為MVCC引起的BUG,下圖1為相應的Java代碼,其中事務1的生命周期最長,迴圈開啟的事務2、3、4。。。與事務1並行 ,數據的讀取只會成功一次,後面的讀不到新增數據,從而出現空指針異常,但是當事務隔離級別為讀提交時,程式會正常執行 圖1 解決方案:將方法userR ...
一、MySQL可重覆讀級別下,因為MVCC引起的BUG,下圖1為相應的Java代碼,其中事務1的生命周期最長,迴圈開啟的事務2、3、4。。。與事務1並行 ,數據的讀取只會成功一次,後面的讀不到新增數據,從而出現空指針異常,但是當事務隔離級別為讀提交時,程式會正常執行
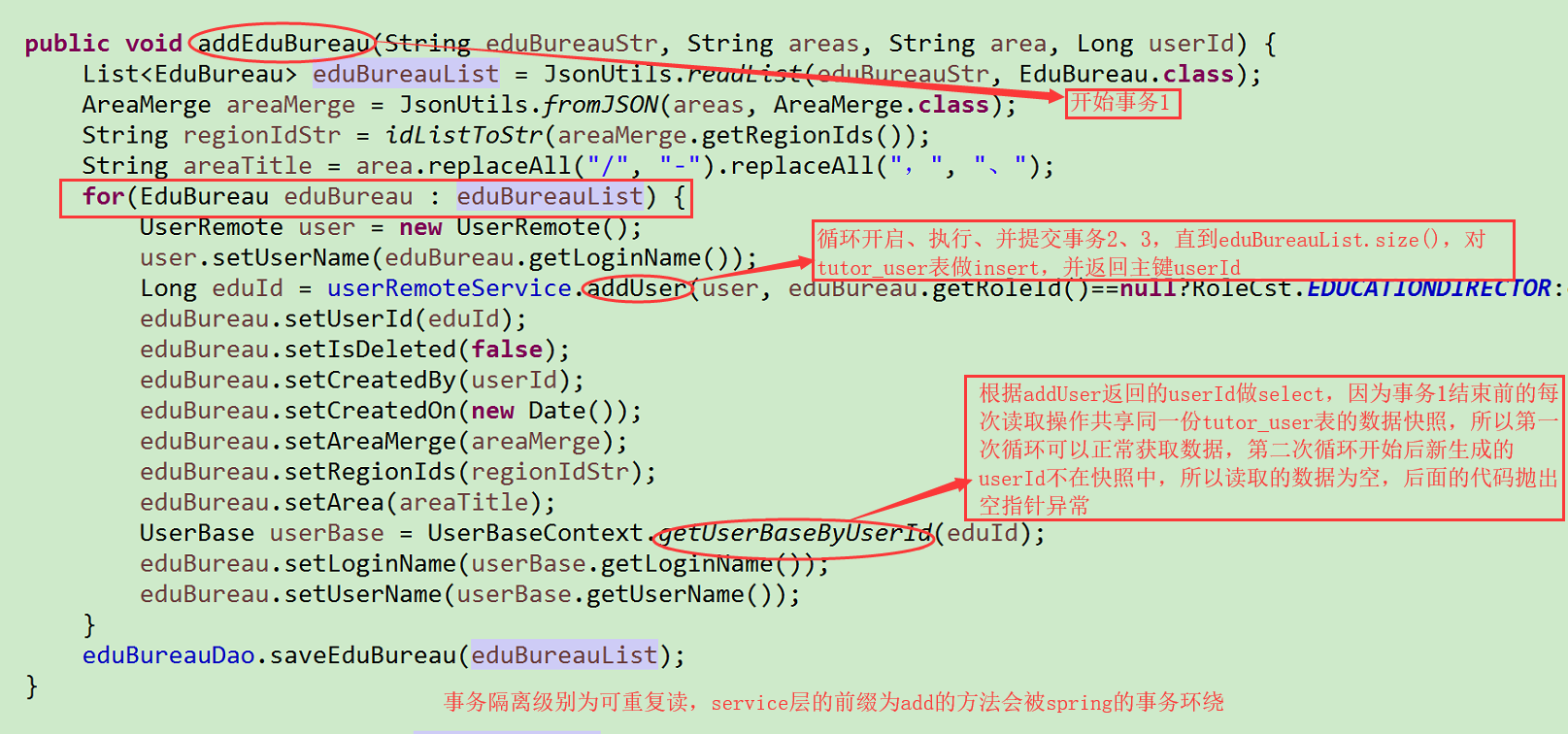
圖1
解決方案:將方法userRemoteService.addUser和UserBaseContext.getUserBaseByUserId放在兩個方法中,避免事務的併發問題
二、MVCC簡介:Multiversion Concurrency Control,多版本併發控制機制,行級鎖的一個變種, 但是它在很多情況下避免了加鎖操作, 因此開銷更低,實現了非阻塞的讀操作,只在read committed和repeatable read兩個隔離級別下工作,因為read uncommitted總是讀取最新的數據行,而serializable則會對所有讀取的行都加鎖
三、數據行隱藏欄位
6位元組的DATA_TRX_ID 標記了最新更新這條行記錄的transaction id,每處理一個事務,其值自動+1
7位元組的DATA_ROLL_PTR 指向當前記錄項的rollback segment的undo log記錄,找之前版本的數據就是通過這個指針
6位元組的DB_ROW_ID,當由innodb自動產生聚集索引時,聚集索引包括這個DB_ROW_ID的值,否則聚集索引中不包括這個值.,這個用於索引當中
DELETE BIT位用於標識該記錄是否被刪除,這裡的不是真正的刪除數據,而是標誌出來的刪除。真正意義的刪除是在commit的時候
對於有有三個欄位id、name、balance的表,其中id為主鍵,實際的擁有的列如下

圖2
四、具體的執行過程:
SELECT:Innodb檢查每行數據,確保他們符合兩個標準:
1、InnoDB只查找版本早於當前事務版本的數據行(也就是數據行的版本必須小於等於事務的版本),這確保當前事務讀取的行都是事務之前已經存在的,或者是由當前事務創建或修改的行
2、行的刪除操作的版本一定是未定義的或者大於當前事務的版本號,確定了當前事務開始之前,行沒有被刪除
符合了以上兩點則返回查詢結果。
INSERT:InnoDB為每個新增行記錄當前系統版本號作為創建ID,該操作沒有回滾指針,因為不存在歷史版本
DELETE:InnoDB為每個刪除行的記錄當前系統版本號作為行的刪除ID。
UPDATE:InnoDB複製了一行。這個新行的版本號使用了系統版本號。它也把系統版本號作為了刪除行的版本
事務執行過程中,只有在第一次真正修改記錄時(比如使用INSERT、DELETE、UPDATE語句),才會被分配一個單獨的事務id,這個事務id是遞增的,下麵以update為例說明
begin->用排他鎖鎖定該行->記錄回滾數據到undo log->將修改前的行標記為刪除,寫事務編號->新增行保存修改後的值,寫事務編號,回滾指針指向undo log中的修改前的行->記錄修改後數據redo log->commit->後臺線程將數據寫磁碟

圖3
優點:
保存這兩個額外系統版本號,使大多數讀操作都可以不用加鎖。這樣設計使得讀數據操作很簡單,性能很好。
缺點:
每行紀錄都需要額外的存儲空間,需要做更多的行檢查工作,以及一些額外的維護工作。
五、read view
1.判斷當前版本數據項是否可見
2.提交讀的隔離級別下,事務開始後到結束前,每次讀取數據都會生成一個read view,而可重覆讀的隔離級別,只有事務開始後第一次讀取數據,才生成read view
2.在innodb中, 每創建一個新事務, 存儲引擎都會將當前系統中的活躍事務列表創建一個副本(read view), 副本中保存的是系統中當前不應該被本事務看到的其他事務id列表
3.當用戶在事務中要讀取某行記錄的時候, innodb會將該行當前的版本號與該read view進行比較
4.比較流程:read view中最早的事務id為tmin,最遲的事務id為tmax,當前事務id為t0
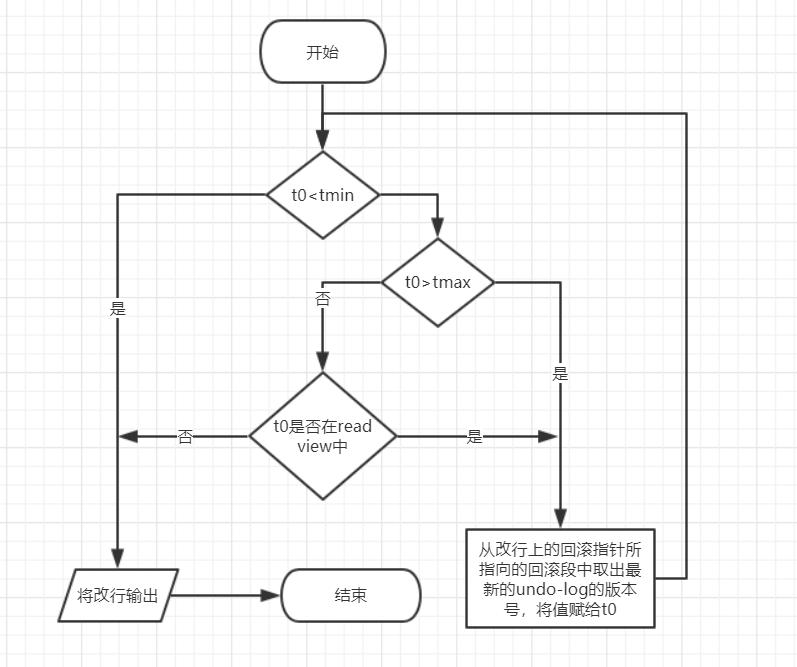
圖4
參考文章
https://www.cnblogs.com/williamjie/p/9492810.html
https://www.jianshu.com/p/db334404d909
https://juejin.im/post/5c9b1b7df265da60e21c0b57


