
爬蟲要想爬取需要的信息,首先第一步就要抓取到頁面html內容,然後對html進行分析,獲取想要的內容。上一篇隨筆《Java爬蟲系列一:寫在開始前》中提到了HttpClient可以抓取頁面內容。 今天就來介紹下抓取html內容的工具:HttpClient。 圍繞下麵幾個點展開: 什麼是HttpClie ...
爬蟲要想爬取需要的信息,首先第一步就要抓取到頁面html內容,然後對html進行分析,獲取想要的內容。上一篇隨筆《Java爬蟲系列一:寫在開始前》中提到了HttpClient可以抓取頁面內容。
今天就來介紹下抓取html內容的工具:HttpClient。
圍繞下麵幾個點展開:
-
什麼是HttpClient
-
HttpClient入門實例
- 複雜應用
-
結束語
一、什麼是HttpClient
度娘說:
HttpClient 是Apache Jakarta Common 下的子項目,可以用來提供高效的、最新的、功能豐富的支持 HTTP 協議的客戶端編程工具包,並且它支持 HTTP 協議最新的版本和建議。 以下列出的是 HttpClient 提供的主要的功能,要知道更多詳細的功能可以參見 HttpClient 的官網: (1)實現了所有 HTTP 的方法(GET,POST,PUT,HEAD 等) (2)支持自動轉向 (3)支持 HTTPS 協議 (4)支持代理伺服器等
這裡面提到了官網,那就順便說下它官網上的一些東西。
根據百度給出的HomePage是這個:http://hc.apache.org/httpclient-3.x/,但是進入後你會發現有句話
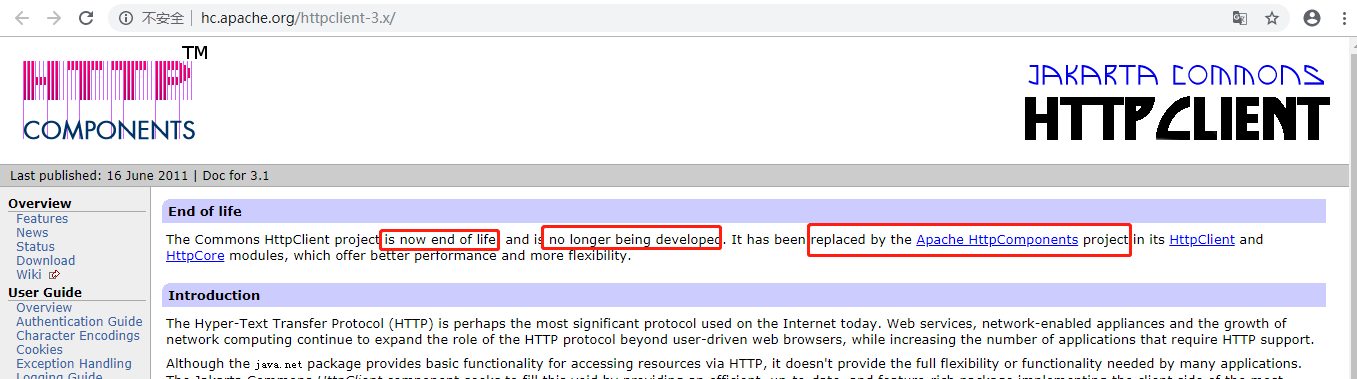
大意是:Commons HttpClient這個項目已經不再維護了,它已經被Apache HttpComponents替代了。也就是說我們以後要用的話就用新的。點這個Apache HttpComponents的鏈接進去能看到它最新的版本是4.5,而且有快速上手的例子和專業的說明文檔。有興趣並且英文好的朋友可以好好研究下哦 ~~
額~~那個~~我的英文不好,就不按照官網的來了,直接給出我自己在網上學的練習案例~~
二、HttpClient入門實例
- 新建一個普通的maven項目:名字隨便起,我的叫:httpclient_learn
- 修改pom文件,引入依賴
<dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5.8</version> </dependency>
- 新建java類
package httpclient_learn; import java.io.IOException; import org.apache.http.HttpEntity; import org.apache.http.HttpStatus; import org.apache.http.client.ClientProtocolException; import org.apache.http.client.methods.CloseableHttpResponse; import org.apache.http.client.methods.HttpGet; import org.apache.http.client.utils.HttpClientUtils; import org.apache.http.impl.client.CloseableHttpClient; import org.apache.http.impl.client.HttpClients; import org.apache.http.util.EntityUtils; public class HttpClientTest { public static void main(String[] args) { //1.生成httpclient,相當於該打開一個瀏覽器 CloseableHttpClient httpClient = HttpClients.createDefault(); CloseableHttpResponse response = null; //2.創建get請求,相當於在瀏覽器地址欄輸入 網址 HttpGet request = new HttpGet("https://www.cnblogs.com/"); try { //3.執行get請求,相當於在輸入地址欄後敲回車鍵 response = httpClient.execute(request); //4.判斷響應狀態為200,進行處理 if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) { //5.獲取響應內容 HttpEntity httpEntity = response.getEntity(); String html = EntityUtils.toString(httpEntity, "utf-8"); System.out.println(html); } else { //如果返回狀態不是200,比如404(頁面不存在)等,根據情況做處理,這裡略 System.out.println("返回狀態不是200"); System.out.println(EntityUtils.toString(response.getEntity(), "utf-8")); } } catch (ClientProtocolException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { //6.關閉 HttpClientUtils.closeQuietly(response); HttpClientUtils.closeQuietly(httpClient); } } }
- 執行代碼,我們會發現列印出來的其實就是首頁完整的html代碼
<!DOCTYPE html> <html lang="zh-cn"> <head> //Java開發老菜鳥備註:由於內容太多,具體不再貼出來了 </head> <body>//Java開發老菜鳥備註:由於內容太多,具體內容不再貼出來了
</body> </html>
操作成功!
好了,到這裡就完成了一個簡單的小例子。
爬一個網站不過癮,再來一打。接下來我們換個網站:https://www.tuicool.com/,你會發現結果是這樣的:
返回狀態不是200 <!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"> </head> <body> <p>系統檢測親不是真人行為,因系統資源限制,我們只能拒絕你的請求。如果你有疑問,可以通過微博 http://weibo.com/tuicool2012/ 聯繫我們。</p> </body> </html>
爬蟲程式被識別了,怎麼辦呢? 彆著急,慢慢往下看
三、複雜應用
第二個網站訪問不了,是因為網站有反爬蟲的處理,怎麼繞過他呢?
1.最簡單的是對請求頭進行偽裝,看代碼,加上紅框裡面的內容後再執行
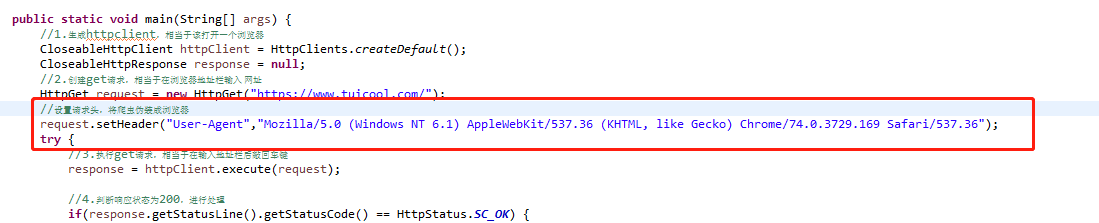
你會發現返回結果變了,有真內容了(紅字警告先不管它,我們起碼獲取到了html內容)
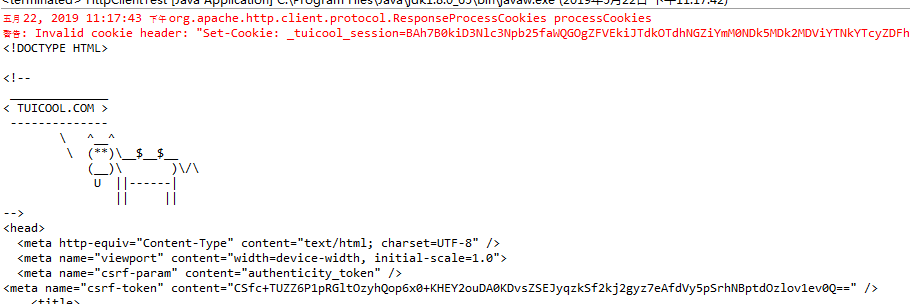
那代碼中新加的那段內容是哪裡來的呢?
請打開谷歌瀏覽器的F12,對就是這裡了:

當然我們還可以設置請求的其他頭信息,如cookie等
2.上面說的是偽裝成瀏覽器,其實如果你偽裝了之後,如果短時間內一直多次訪問的話,網站會對你的ip進行封殺,這個時候就需要換個ip地址了,使用代理IP
網上有一些免費的代理ip網站,比如xici

我們選擇那些存活時間久並且剛剛被驗證的ip,我這裡選擇了“112.85.168.223:9999”,代碼如下
//2.創建get請求,相當於在瀏覽器地址欄輸入 網址 HttpGet request = new HttpGet("https://www.tuicool.com/"); //設置請求頭,將爬蟲偽裝成瀏覽器 request.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36"); HttpHost proxy = new HttpHost("112.85.168.223", 9999); RequestConfig config = RequestConfig.custom().setProxy(proxy).build(); request.setConfig(config);
執行代碼,能正常返回html結果。如果代理ip剛好不能用的話,會報錯,如下顯示連接超時,這個時候需要更換一個新的代理ip
3.另外,程式被識別出來很大原因是短時間內做了太多訪問,這個是正常人不會有的頻率,因此我們也可以放慢爬取的速度,讓程式sleep一段時間再爬下一個也是一種反 反爬蟲的簡單方法。
四、結束語
這篇簡單介紹了下httpclient和它的官網,並用代碼說明瞭如何使用它,也提到瞭如果遇到反爬蟲的話我們還可以用一些簡單的反反爬蟲方法進行應對。
對於其他複雜的反反爬蟲的方法我還沒有研究過,就是用這幾種結合使用。 比如在爬取了一段時間後,網站需要輸入驗證碼來驗證是人在操作,我沒有去管如何突破驗證碼的事兒,而是獲取代理ip池然後在遇到驗證碼的時候逐個換新的ip,這樣就可以躲過了驗證碼。如果有其他方法,歡迎留言哦


