
OO第三單元作業總結——JML 第三單元的主題是JML規格的學習,其中的三次作業也是圍繞JML規格的實現所展開的(雖然感覺作業中最難的還是如何正確適用數據結構以及如何正確地對於時間複雜度進行優化)。 關於JML語言 JML語言概述 JML是Java Modeling Language的縮寫,意思是J ...
OO第三單元作業總結——JML
第三單元的主題是JML規格的學習,其中的三次作業也是圍繞JML規格的實現所展開的(雖然感覺作業中最難的還是如何正確適用數據結構以及如何正確地對於時間複雜度進行優化)。
關於JML語言
JML語言概述
JML是Java Modeling Language的縮寫,意思是Java建模語言,是一種進行詳細設計的符號語言。
使用JML語言的好處主要有以下幾點:
- 能夠描述類和方法的運行方式,從而使代碼的編寫過程更加契合面向對象思想;
- 可以更加高效地發現和修正程式中的bug
- 在程式開發中降低bug的出現幾率並及時發現已有的bug
所以說,JML對於面向對象的學習還是有很大的幫助的。
JML基本語法
下麵總結一下目前JML學習中使用到的常用語法:
JML表達式
原子表達式:
\result表達式:表示方法執行後的返回值。\old( expr )表達式:用來表示一個表達式expr在相應方法執行前的取值。量化表達式:
\forall表達式:全稱量詞修飾的表達式,表示對於給定範圍內的元素,每個元素都滿足相應的約束。例如(\forall int i,j; 0 <= i && i < j && j < 10; a[i] < a[j])\exists表達式:存在量詞修飾的表達式,表示對於給定範圍內的元素,存在某個元素滿足相應的約束。例如(\exists int i; 0 <= i && i < 10; a[i] < 0)\sum表達式:返回給定範圍內的表達式的和。例如,(\sum int i; 0 <= i && i < 5; i)此外,還有集合表達式、包含操作符的表達式等。
方法規格
前置條件:通過
requires子句來表示;後置條件:通過
ensures子句來表示;副作用範圍限定:通過使用關鍵詞
assignable或者modifiable限定,其中assignable表示可賦值,而modifiable則表示可修改;異常區分:使用
signals子句,signals子句的結構為signals (Exception e) b_expr,表示當b_expr為 true 時,方法會拋出括弧中給出的相應異常e。
類型規格
- 不變式
invariant:不變式是要求在所有可見狀態下都必須滿足的特性,語法上定義invariant P; - 狀態變化約束
constraint:用constraint來對前序可見狀態和當前可見狀態的關係進行約束。
- 不變式
JML應用工具鏈
- OpenJML:檢查JML的語法和邏輯。
- JMLUnit/JMLUnitNG:根據JML自動生成測試樣例。
部署SMT Solver
在多次嘗試試用各種方式安裝openJML後,終於可以基本對於程式使用SMT Solver進行測試。
測試命令(windows環境):
java -jar path1\openjml.jar -check path2\classname.java
(其中,path1為openjml解壓到的文件夾,path2位需進行測試的java程式所在的位置)
最開始,我先對於OpenJML網站上的最簡單的程式進行了測試,代碼如下:
public class MaybeAdd {
//@ requires a > 0;
//@ requires b > 0;
//@ ensures \result == a+b;
public static int add(int a, int b){
return a-b;
}
public static void main(String args[]){
System.out.println(add(2,3));
}
}測試並沒有報出錯誤,為了檢測這種測試方法的正確性,我改了原代碼中requires中的==,將其改為了=,再次進行測試:
public class MaybeAdd {
//@ requires a > 0;
//@ requires b > 0;
//@ ensures \result = a+b; //此處發生改變
public static int add(int a, int b){
return a-b;
}
public static void main(String args[]){
System.out.println(add(2,3));
}
}此次,測試報出兩個錯誤,表明等號位置發生錯誤:

由於使用SMT Solver測試經常出現一些不可知的錯誤,所以這回我只選用了一個MyPath類中非常簡單的方法進行了測試:
public class GetNode {
private /*@spec_public@*/ int[] nodes;
/*@ requires index >= 0 && index < nodes.length;
@ assignable \nothing;
@ ensures \result == nodes[index];
@*/
public int getNode(int index) {
return nodes[index];
}
}測試沒有報錯,表示程式正確。
此時改變代碼中的nodes.length為nodes.size():
public class GetNode {
private /*@spec_public@*/ int[] nodes;
/*@ requires index >= 0 && index < nodes.size();
@ assignable \nothing;
@ ensures \result == nodes[index];
@*/
public int getNode(int index) {
return nodes[index];
}
}測試報出一個錯誤,如下圖所示:

部署JMLUnitNG/JMLUnit
由於之前的代碼的jml規格中存在不少問題,所以這回我還是使用官網給出的簡易demo先進行測試:
public class MaybeAdd {
//@ requires a > 0;
//@ requires b > 0;
//@ ensures \result == a+b;
public static int add(int a, int b){
return a-b;
}
public static void main(String args[]){
System.out.println(add(2,3));
}
}測試命令與SMT Solver類似:
java -jar path1\jmlunitng.jar path2\classname.java
最終產生的測試文件如下圖:
同樣,對於MyPath類中getNode方法進行生成測試文件:
public class GetNode {
private /*@spec_public@*/ int[] nodes;
/*@ requires index >= 0 && index < nodes.length;
@ assignable \nothing;
@ ensures \result == nodes[index];
@*/
public int getNode(int index) {
return nodes[index];
}
}最終生成的測試文件如下:
梳理架構設計與BUG分析
這個單元的作業可以說是至今為止最差的幾次,雖然在JML的理解上是沒有出現什麼問題的,但是由於數據結構上使用的錯誤,以及演算法優化的問題,導致在代碼的實現方面出現了很大的問題。
第一次作業
- 類圖
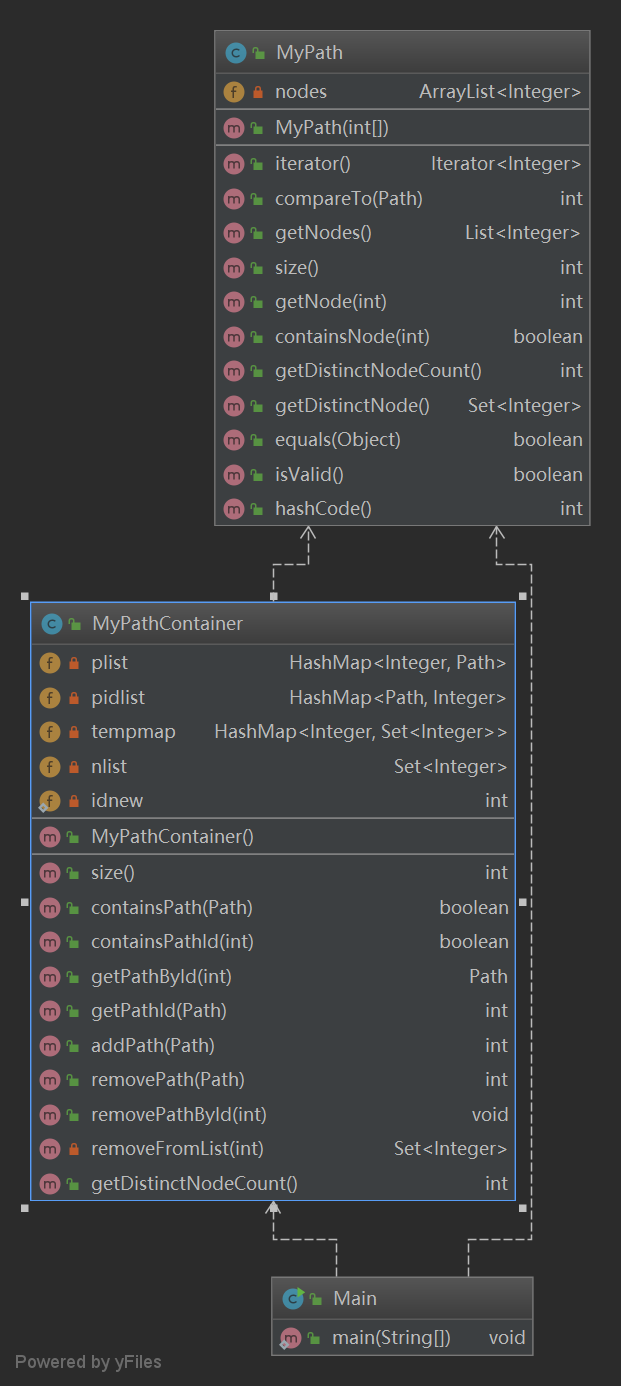
這次的架構基本就是按照指導書的要求寫的,分為了Main,Mypath和MyPathContainer三個類。
- 主要度量圖
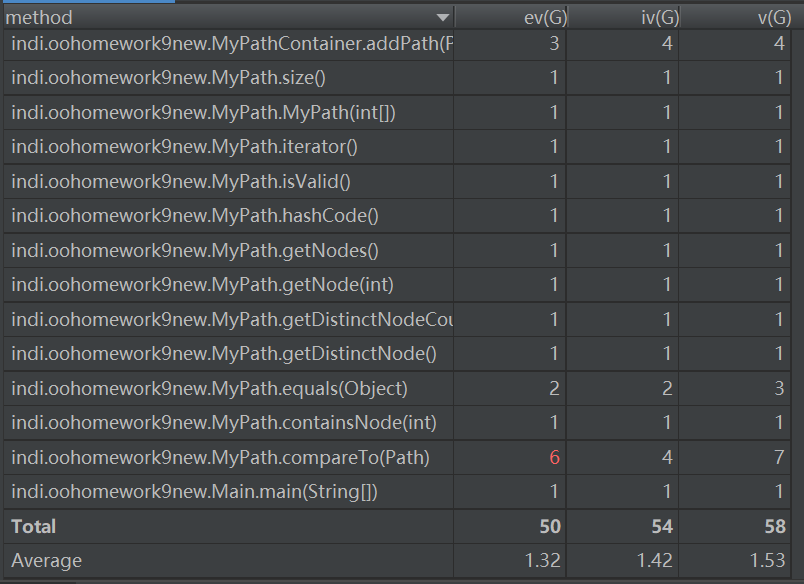
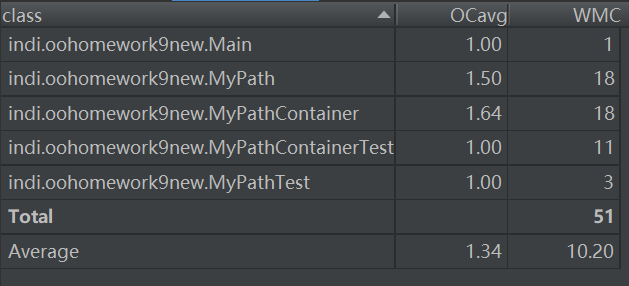
從度量圖中可以看出,由於第一次作業較為簡單,所以每個類和方法的複雜度都還是比較低的。
bug分析
這單元第一次作業其實非常簡單,但是需要考慮的方面還是比較多的。一方面是對於數據容器的選擇,在這方面我使用的是hashmap,可以在查找時儘量保證複雜度為O(1)。另一方面是如何分配操作的位置,在這一方面我栽了跟頭,沒能註意到加減道路的指令比查不同點的數目的指令的數量少的多,所以可以將找不同點的數目這一運算分散到加減路徑的操作中,而這個問題也使我在強測中TLE了不少點。
修改方法:
使用一個hashset進行點的儲存,可以直接防止重覆加點,並且將加點操作分散到加減路徑中,代碼修改即為:
public int getDistinctNodeCount() { return nlist.size(); }
第二次作業
- 類圖
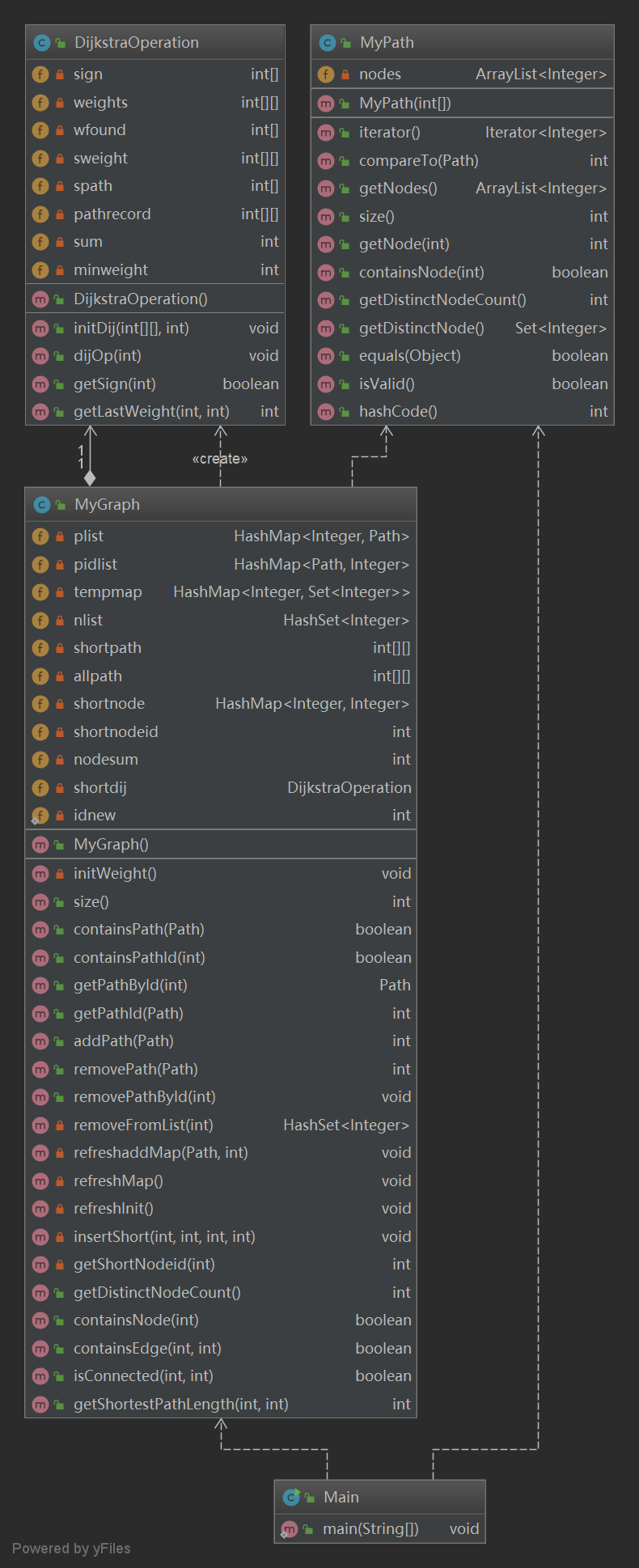
- 主要度量圖
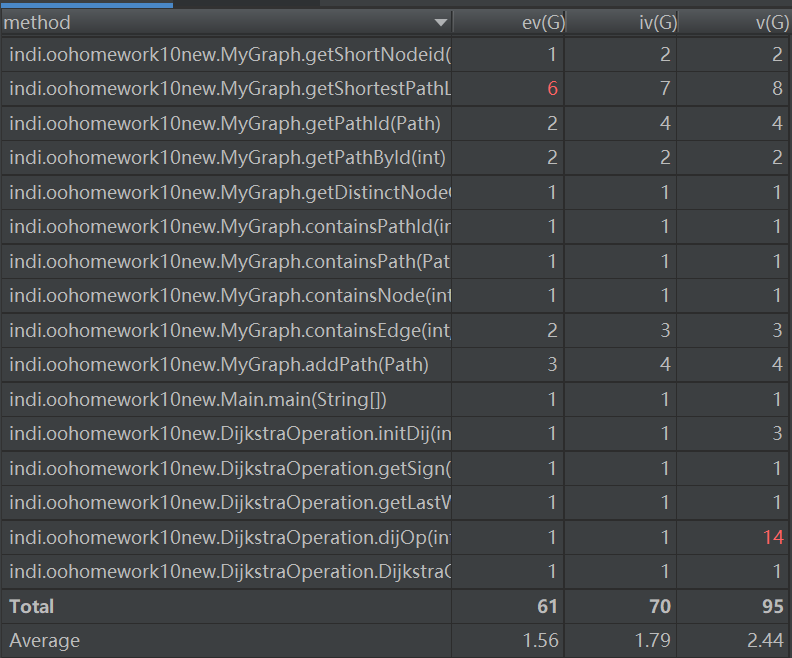
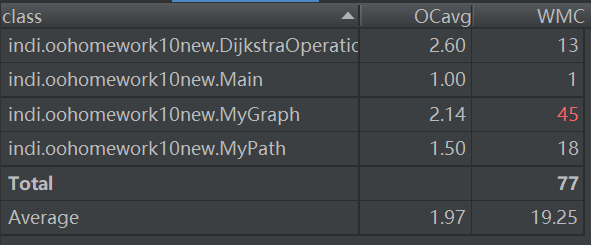
bug分析
在這一次作業中,我犯了一個致命性的錯誤,在演算法的選擇上沒有清晰的認識,導致自己沒有用現成的演算法,而是使用了自己所想的龜速演算法,每次查找都遍歷了所有的邊,導致TLE成為了必然。在bug修複中,我將演算法改為了dijkstra演算法,結果輕鬆地過了之前TLE的點。(上面的圖為修改後代碼的類圖和主要度量圖)
第三次作業
- 類圖
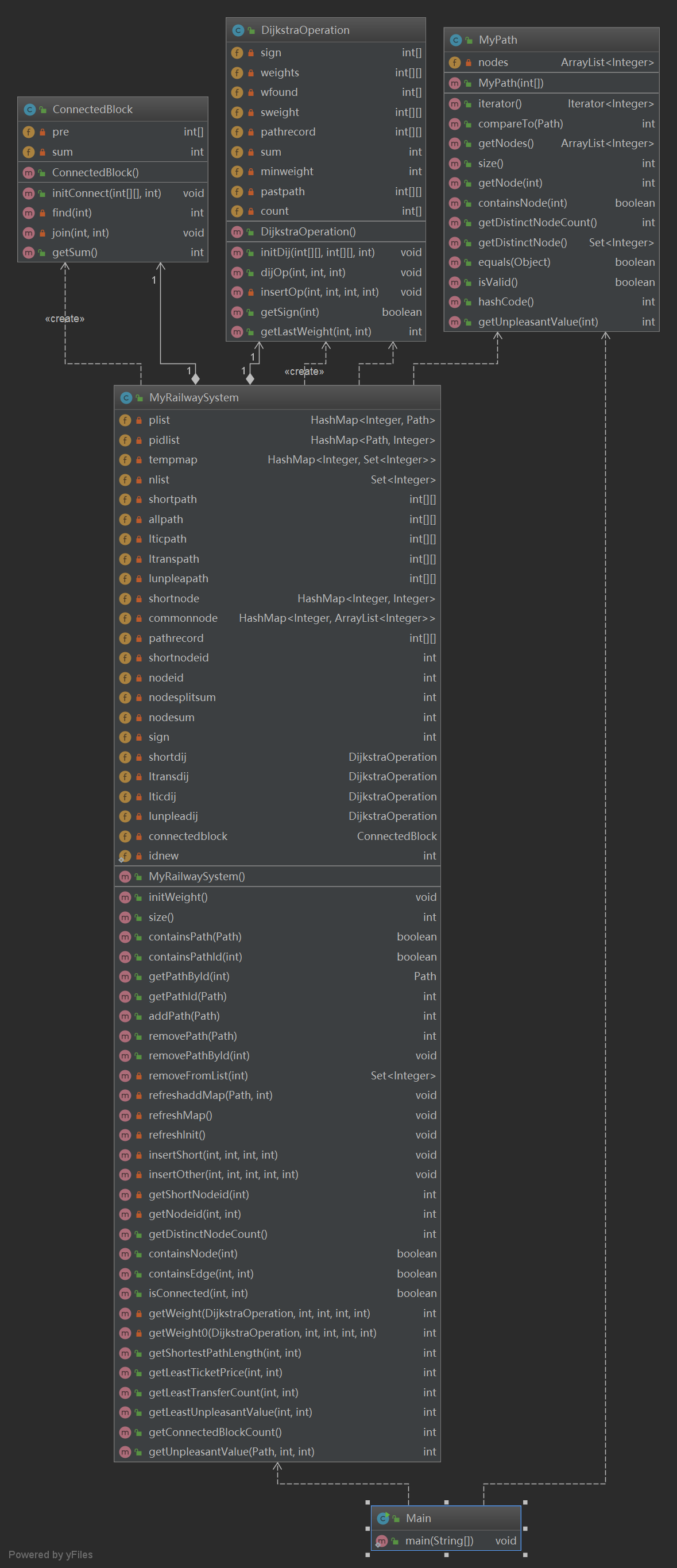
本次的架構是沿用上次的作業,使用dijkastra演算法,並將四種查找綜合為同一種,都當作為求最小權值的路徑。
- 主要度量圖
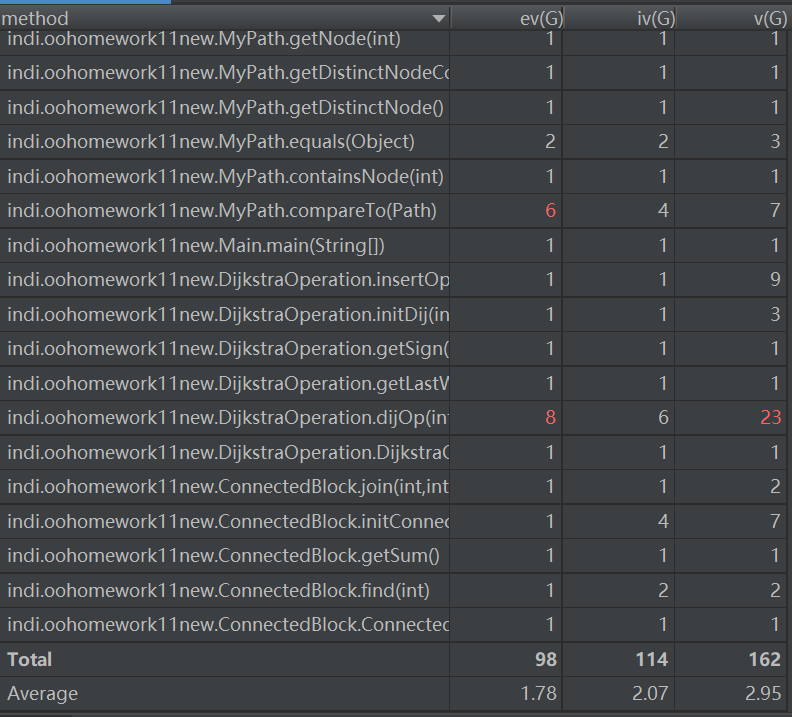

bug分析
自己的bug:
這次作業我因為使用了不正確的拆點法而死的很慘。其實在最初寫代碼的時候,我已經意識到用我所想到的拆點法會需要比較大的數組,但是由於我想當然地以為測評機是實現很多如此大的數組,這點並沒有引起我的註意,結果是我太天真,最終由於RE,又沒有多少時間進行重構,導致最後只能改小數組來通過中測,但是這也使我強測發生了爆棧的問題。
最後在bug修複的時候,我改了一種方法,將拆點法改為了不拆點的方法,並借鑒討論區大佬和身邊大佬的方法,將同一條路徑中的點兩兩相連,這樣它們之間的權值就可以直接加上換乘時需多加的權值,之後再進行dij演算法查找最小權值的邊,最後結果在減去各個情況換乘需加上的權值(因為之前都加了一遍)。這種方法可以完美避開了使用dij演算法時易出現的找不到最優解的情況。
他人的bug:
在測試他人的bug,發現大家主要錯的還是兩點:一種情況是演算法不夠優化,速度過慢導致TLE;另一種情況是在查找最小權值路徑時,發生了隱形的錯誤,導致最後的結果不是最終情況。
對規格撰寫和理解上的心得體會
這三次作業的理解和完成雖然並不是非常順利,在數據結構和演算法的使用上遇到了一些瓶頸,但是可以肯定的是,對於jml語言已經初步入門,能夠基本地根據方法編寫相應的JML規格和理解現有的JML規格。根據JML規格編寫代碼,我也體驗到了真正面向對象編寫程式的過程。雖然目前寫的程式規模還比較小,JML還沒有體現出很大的作用,但是當之後的代碼量大的時候,使用JML可以使我們更快地定位到錯誤的地方,這就能對我這個經常debug無能的人提供很大的幫助。


