提到死鎖,最最常規的場景之一是Session1 以排它鎖的方式鎖定A表,請求B表,session2以排它鎖的方式鎖定B表,請求A表之類的,訪問順序不一致導致死鎖的情況本文通過簡化,測試這樣一種稍顯特殊的場景:對同一張表,併發update其中的多行記錄引起的死鎖,同時簡單分析,對於update操作的加 ...
提到死鎖,最最常規的場景之一是Session1 以排它鎖的方式鎖定A表,請求B表,session2以排它鎖的方式鎖定B表,請求A表之類的,訪問順序不一致導致死鎖的情況
本文通過簡化,測試這樣一種稍顯特殊的場景:對同一張表,併發update其中的多行記錄引起的死鎖,同時簡單分析,對於update操作的加鎖步驟
這種場景引起的死鎖比較少見,但是並不代表不存在,在某些併發場景下,可能會引起死鎖的,應該需要引起重視。
測試環境搭建
sqlserver 資料庫版本:
Microsoft SQL Server 2014 - 12.0.2269.0 (X64)
Jun 10 2015 03:35:45
Copyright (c) Microsoft Corporation
Enterprise Edition (64-bit) on Windows NT 6.1 <X64> (Build 7601: Service Pack 1)
創建測試表並寫入測試數據
create table test_deadlock ( id int identity(1,1), col2 varchar(10), col3 varchar(5000), createdate datetime ) alter table test_deadlock add constraint pk_test_deadlock primary key(id) create index idx_col2 on test_deadlock(col2) go insert into test_deadlock select concat('A',cast(rand()*1000000 as int)),replicate('B',5000),getdate() go 1000000
死鎖重現
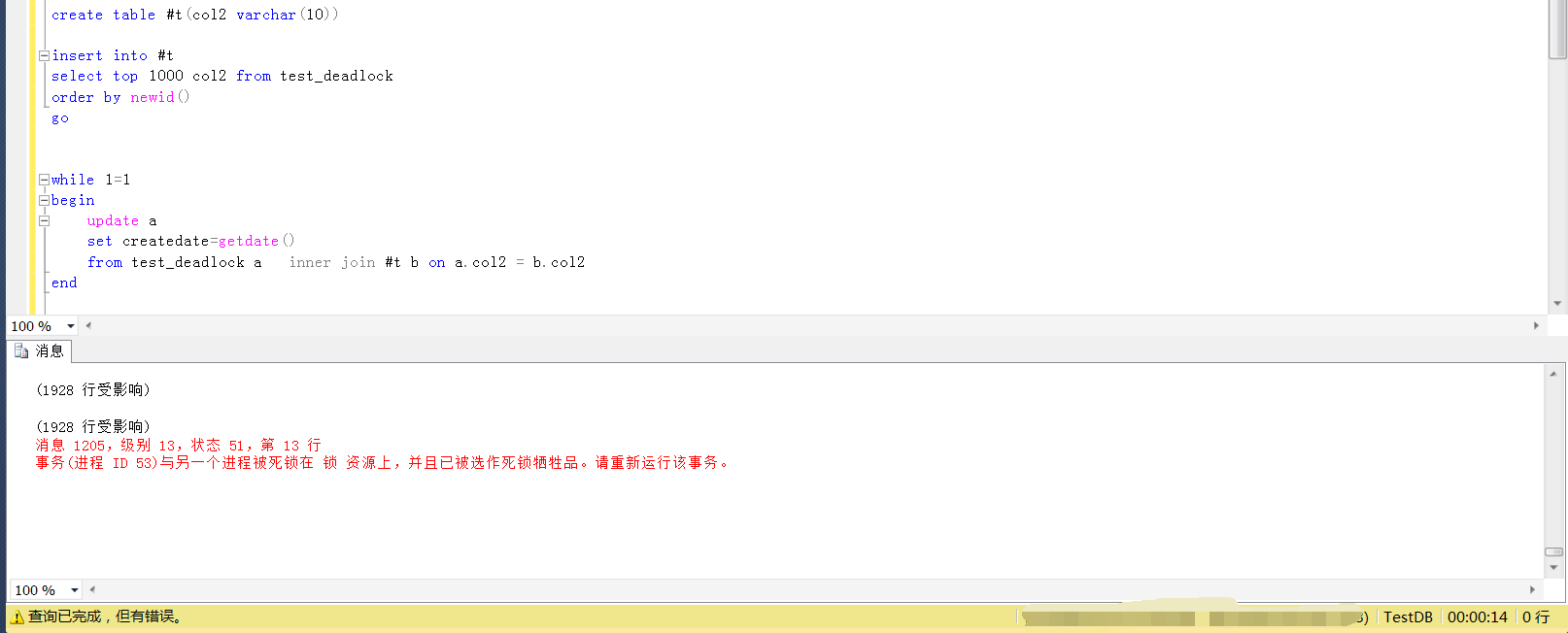
兩個session,假如是session和session2,分別造sqlserver manager studio查詢視窗中執行如下語句,模擬兩個session的併發操作
create table #t(col2 varchar(10)) insert into #t select top 1000 col2 from test_deadlock order by newid() go while 1=1 begin update a set createdate=getdate() from test_deadlock a inner join #t b on a.col2 = b.col2 end
邏輯就是隨機寫里臨時表中1000行記錄,然後依據臨時表中的數據更新測試表test_deadlock
分別執行兩個session的sql之後,因為#t是隨機寫入1000行數據,兩個session中#t的數據肯定是不完全一樣的,然後執行兩個session的語句
等待執行一段時間之後(並不一定每次都會出現,或者很快出現,需要多次測試),就會發現其中一個session的執行遇到了死鎖,如下
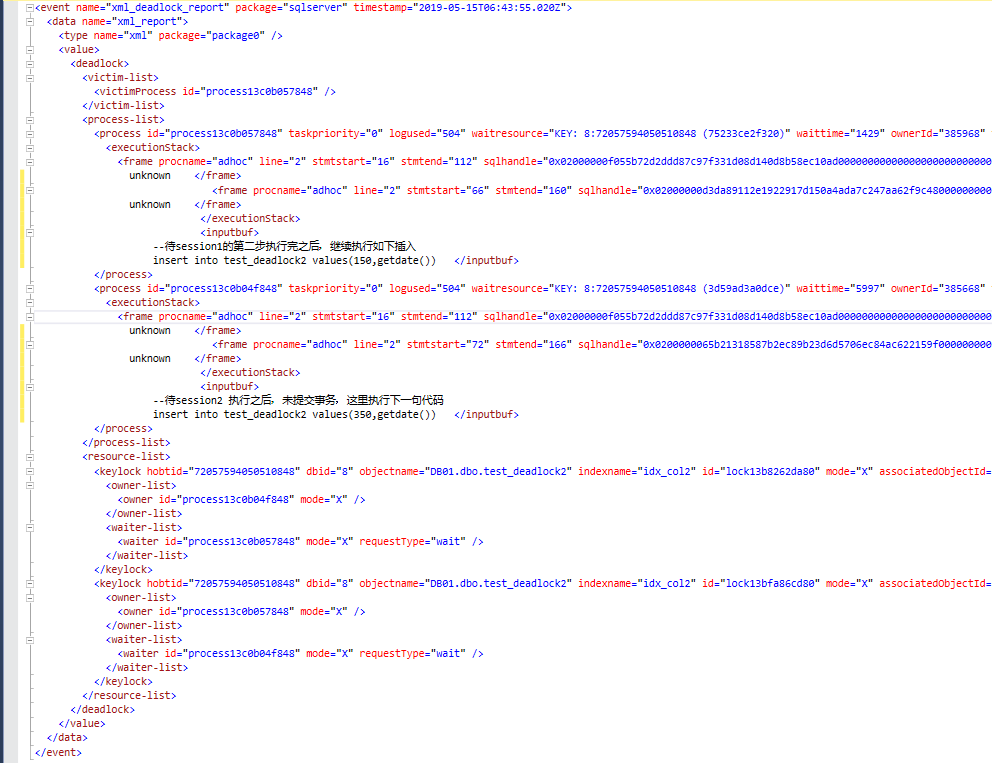
通過sqlserver自帶的擴展事件[system_health]查看死鎖的詳細信息
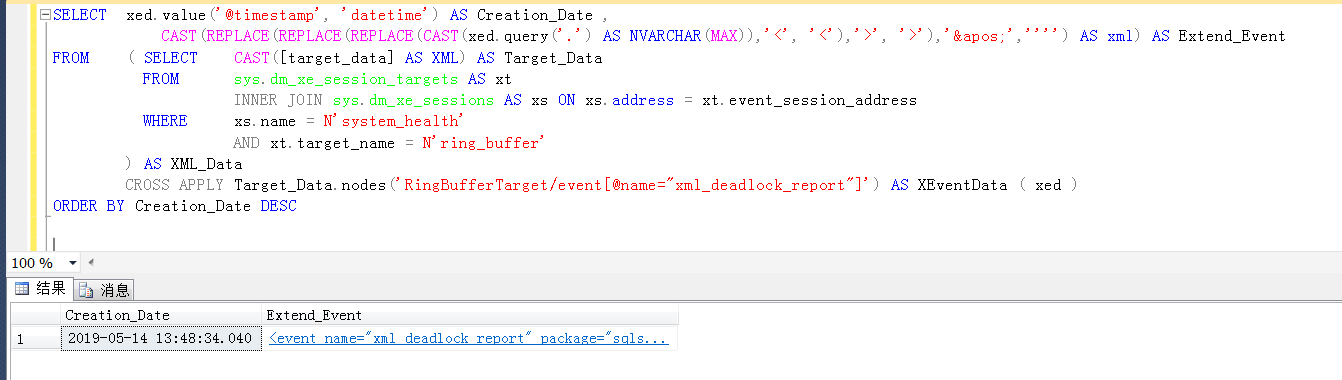
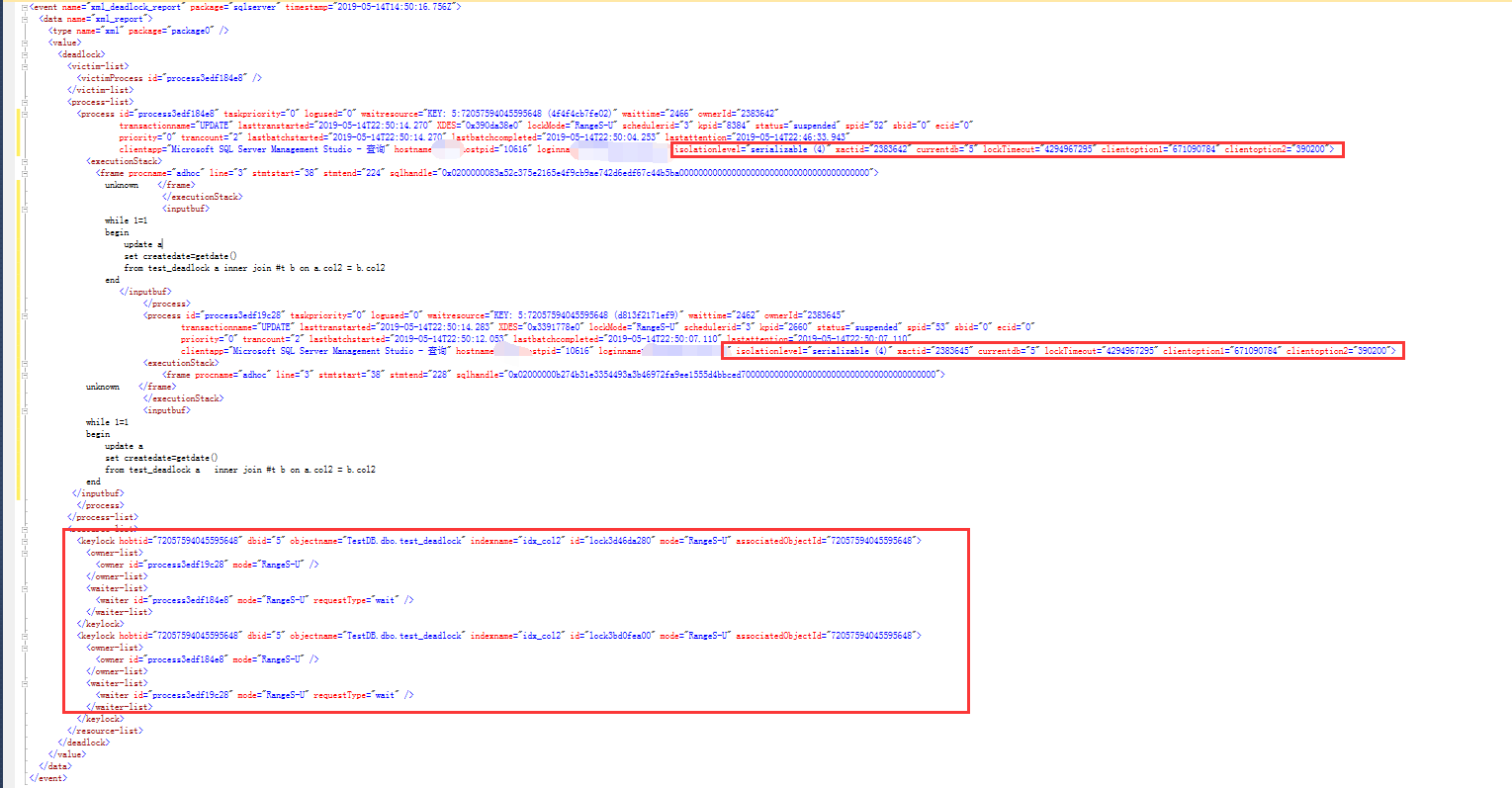
查看死鎖xml的詳細信息,非常清楚地顯示,兩個session在占用了某個key值的U鎖之後,相互請求對方占用的U鎖的,結果就是死鎖
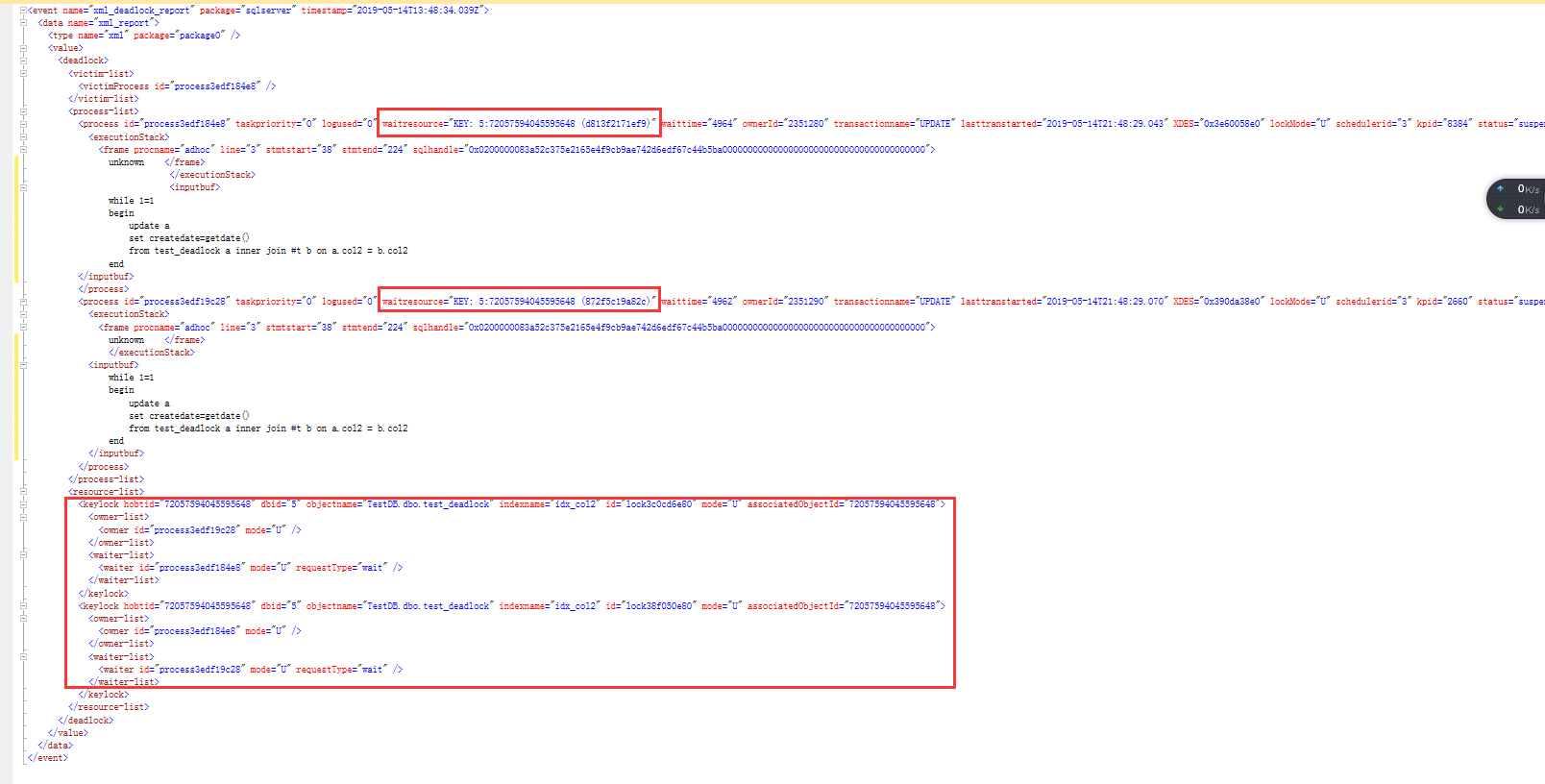
對於兩個session wait的key分別是:KEY: 5:72057594045595648 (d813f2171ef9)和KEY: 5:72057594045595648 (872f5c19a82c)
關於key值格式的含義,簡單說一下,以KEY: 5:72057594045595648 (872f5c19a82c)為例,5代表數據Id,72057594045595648 代表index的id,(872f5c19a82c)代表key值的內部Id
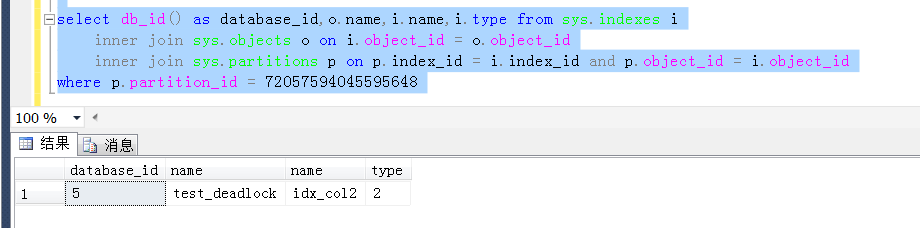
關於前兩者,相對比較簡單,通過系統表可以查詢出來,如下是當前測試庫執行的查詢結果,很直觀地顯示了key值中的信息含義
關於(872f5c19a82c)代表key值的內部Id,可以通過一個未公佈的系統函數 %%lockres%% 查看得到,如下,也相對比較清楚。關於 %%lockres%% 不做過多的表述,偏避免偏離主題。
有興趣瞭解%%lockres%% 的參考:https://dba.stackexchange.com/questions/106762/how-can-i-convert-a-key-in-a-sql-server-deadlock-report-to-the-value
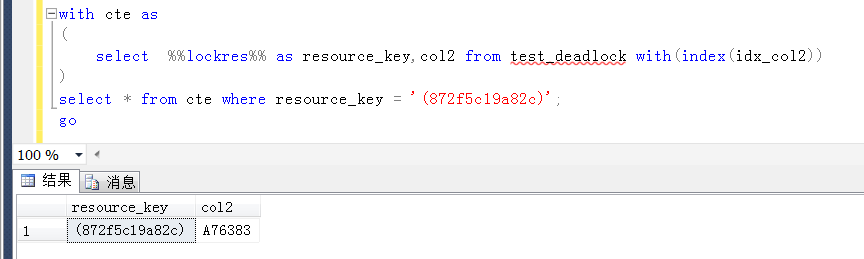
現在可以清楚地得到:
session1 以U鎖的方式鎖定了一個idx_col2上的索引值 (d813f2171ef9),請求索引值 (872f5c19a82c)上的U鎖
session2 以U鎖的方式鎖定了一個idx_col2上的索引值 (872f5c19a82c),請求索引值(d813f2171ef9)上的U鎖
U鎖與U鎖不相容,然後發生了死鎖。
這裡簡單分析一下,這兩個key值內部Id對應的具體的key值以及兩個session的鎖定情況。
兩個內部Id對應的col2欄位分別是A229853和A76383,
也就是說session1 對col2=A229853 key值加U鎖,請求col2 = A76383的key值的U鎖
session2 對col2=A76383 key值加U鎖,請求col2 = A229853 的key值的U鎖

那麼去具體的session(查詢視窗)中的臨時表驗證一下這兩個Id是不是同時存在於兩個session的臨時表中,是不是這樣的。
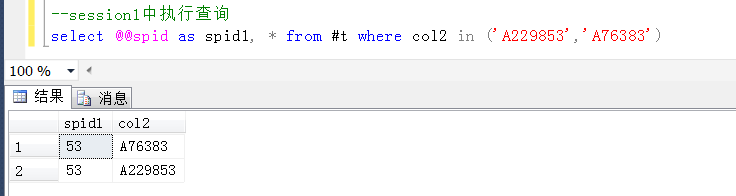
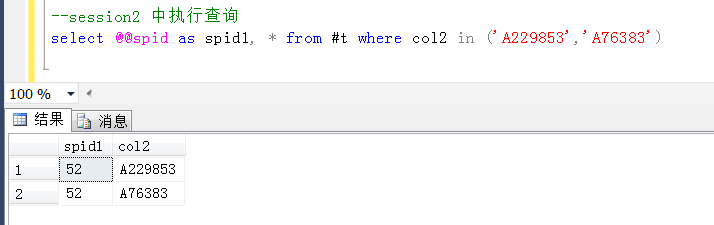
沒有問題,session1和session2中都包含了這兩個id,這裡預設查詢出來的順序,也剛好相反,更加可以支持上述推斷,在執行update的過程中,造成了上述的死鎖。
死鎖原因分析
update的加鎖,這裡是對1000個col2的值執行更新,內部可以看做是一個過程,即便是使用了索引查找(index seek)
批量update,雖然是一個事物,但是執行的過程,對於目標數據的加鎖是一個過程(逐行),這個過程不是隔離的或者說排他性執行的(除非是表級別的排它鎖)
粗略地講,推斷其大概過程如下:
依次遍歷符合條件的目標數據(#t中的col2與test_deadlock)進行查找,如果找到,加U鎖(尚不考慮鎖升級為表鎖)
偽代碼如下
foreach(key in #t)--直接以#t中的col2欄位的值,通過索引查找的方式驅動test_deadlock,依次加(U)鎖
{
if(key==test_deadlock.col2)
{
updlock test_deadlock.col2
}
}
加鎖,這裡是逐行對test_deadlock中的col2 key加U鎖是一個過程,而不是一瞬間。一旦兩個session加鎖目標存在交集,並且對加鎖的key值加鎖順序不一致,就潛在發生死鎖的可能性。
比如session1 先對key = A229853 的值加U鎖,再視圖key = A229853 加U鎖
session2先對key = A229853 的值加U鎖,再試圖key = A229853 加U鎖,死鎖就因此而產生
這裡的update語句,內部是一個事物沒錯,但是需要個事物區分來看,當前update加的鎖是一個key鎖,而不是表鎖,既然是key鎖,需要逐個查找然後加鎖,而不是一次性加鎖
這就是當前這種場景產生死鎖的原因。
該死鎖產生的條件
1,存在比較大的併發量,或者是做併發壓力測試
2,併發session update的目標數據存在交集
3,伺服器資源使用率比較高或者負載比較重的時候更容易出現
如何解決
上述分析原因是一次對不同的key值加U鎖,不同session加鎖目標存在交集,且加鎖順序不一致引起的,在read committed或者可重覆度隔離級別,都無法解決上述家鎖衝突問題
1,從邏輯key值加鎖順序入手:
問題的本質在於,併發session對目標數據加鎖目標存在交集,且對加鎖目標的加鎖(key值)順序不一致,如果使併發session對加鎖目標(key值)加鎖順序一致,也就不會出現死鎖的情況了。
如果按照對key值順序的方式加鎖(通過在key值上創建cluster索引),
可以將上面key值的隨機訪問變為順序訪問(table scan變為cluster index scan),只會出現相互阻塞,而不是死鎖,想一想為什麼……
這裡通過對#t的目標值欄位,創建一個索引,再經併發測試,不會出現死鎖.
但是這種方式,並上不是最佳的,因為執行計劃不會永遠只有一種,
這裡主觀上要求一定是#t表驅動目標表test_deadlock,面對更加複雜的實際情形,如何保證?難道需要再次加強制索引+驅動順序提示?
insert into #t select top 1000 col2 from test_deadlock order by newid() create cluster index idx_col2 on #t(col2) go while 1=1 begin update a set createdate=getdate() from test_deadlock a inner join #t b on a.col2 = b.col2 end
2,從鎖定方式入手:
可序列化隔離級別,或者直接對update的目標表加表級別鎖解決
事實上經過測試,出乎意料的是,可序列化隔離級別依舊解決不了上述加鎖衝突,如下,當然,序列化隔離級別下,死鎖類型跟預設隔離級別下並不完全相同,是RangeS-U之間的衝突
序列化可能造成的死鎖,也有大把的例子,這裡不繼續扯了,參考https://stackoverflow.com/questions/27347730/serializable-transaction-deadlock,https://stackoverflow.com/questions/39029573/why-does-a-serializable-isolation-level-lead-to-deadlock-and-concurrency-issues
經測試,直接加表級別鎖,可以解決上述死鎖問題,參考如下
while 1=1 begin update a set createdate=getdate() from test_deadlock a with(updlock,tablock) inner join #t b on a.col2 = b.col2 end
另外,如果其他辦法,也未嘗不可,從應用程式的角度,可以使用類似於單例模式,從發起端開始排隊,或者將目標數據寫入隊列的方式,依次排隊打入數據的方式執行,都是可以避免死鎖的。
最後
這種死鎖,並不會輕易生成,但它是確確實實存在的,或者說是潛在的,筆者根據實際場景在本地反覆做測試,中間也遇到一些問題
1,基於當前測試方式和場景,測試數據量要足夠大,設計case的時候,要避免自動的鎖升級造成測試干擾,避免某些寫法讓#t中生成的數據有序,都會重現這種場景
2,如果想從預設擴展事件system_health的ring_buffer中查看死鎖信息,類似本文,需要對[system_health]預設的擴展事件加大ring_buffer的max_events_limit和max_memory。
至於為什麼,參考這個:https://www.cnblogs.com/wy123/p/9055731.html
3,對於高性能的伺服器,比較難以重現這種場景,因為每個session都執行的相對較快
4,測試庫如果是完整恢復模式,小心撐爆事物日誌或者磁碟空間
該死鎖產生場景的擴展
對於類似的死鎖產生場景,與併發批量update的邏輯一樣,在併發批量做delete的時候也會出現死鎖,並且已經在生產環境發現過。
併發批量insert,會不會產生類似的死鎖,如果產生了,又如何解決,繼續測試。
可能會死鎖產生的場景,還是超出了預料……
併發insert的造成的死鎖場景,也可以間接模擬出來,通過將批量insert拆分成多句單個的insert,來模擬key值加鎖順序衝突造成的死鎖死鎖
如下代碼創建一個測試表
create table test_deadlock2 ( id int identity(1,1), col2 int, createdate datetime ) alter table test_deadlock2 add constraint pk_test_deadlock2 primary key(id) --註意,這裡是的col2是一個唯一索引 create unique index idx_col2 on test_deadlock2(col2) --預先寫入測試數據 insert into test_deadlock2 values (0,getdate()),(100,getdate()),(200,getdate()),(300,getdate())
這裡模式的死鎖方式並不是偶然的,是必然的,需要瞭解insert的加鎖機制
第一步,session1中,開事物,執行第一句insert語句
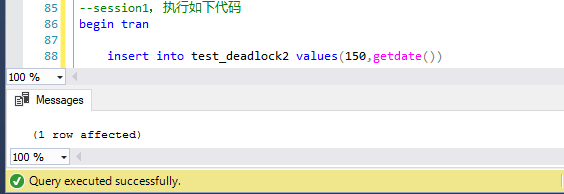
第二步,session2中,開事物,執行第一句insert語句

第三步,session1中執行第二句insert,被阻塞
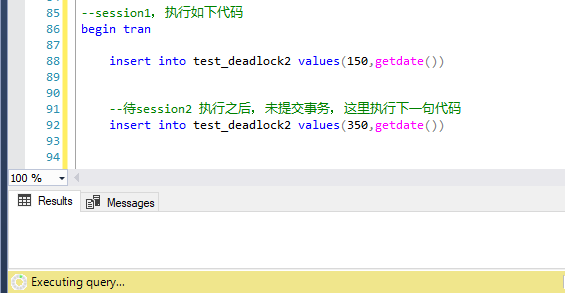
第四部,session2中執行第二句insert語句,session2作為死鎖的犧牲品,session1順利完成
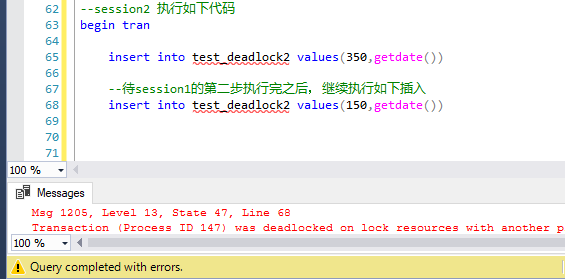
最後,session2死鎖應運而生,session1 正常執行完成,至於問題的原因,跟上面批量update造成的死鎖,基本上完全一樣
只不過這裡把批量insert(類似於insert into table select col from #t)轉換為單行的insert,使得問題更容易出現。
僅測試本文的場景,筆者個人的機器是12GB記憶體,8核心I7 CPU,測試過程,機器沒有開其他應用程式,已經巨卡無比,記憶體幾乎完全占滿(當然CPU沒有太大壓力),重啟資料庫服務之後,瞬間輕鬆。