
【問題描述】 開發反饋有個應用在後端資料庫某次計劃性重啟後經常會出現資料庫連接異常問題,通過監控系統的埋點數據,發現應用連接資料庫異常有兩類表現: 其一:連接超時 131148.00ms Tomcat Connection Pool &en ...
【問題描述】
開發反饋有個應用在後端資料庫某次計劃性重啟後經常會出現資料庫連接異常問題,通過監控系統的埋點數據,發現應用連接資料庫異常有兩類表現:
其一:連接超時
131148.00ms Tomcat Connection Pool
其二:連接耗時過長
DAL.getConnectionCost 64018ms
【問題分析】
通過監控數據彙總,出現此異常問題來自應用群集中的多台WEB伺服器,沒有規律性,資料庫伺服器也沒有做過系統版本升級及硬體調整,且資料庫各主要性能指標正常,負載很低。因此最大可疑是網路通訊上的異常導致,於是通過客戶端/伺服器端同時抓包進行分析。
分析後,發現數據包中有許多TCP Retransmission
六次重連失敗樣例:

五次重連失敗,第六次連接成功樣例:

TCP SYN重傳次數與請求端的tcp_syn_retries參數值有關,本案例中應用WEB伺服器設置為6(查看命令:sudo sysctl -a | grep tcp_syn_retries),即重試的間隔時間從1s開始每次都翻倍,6次的重試時間間隔為1s, 2s, 4s, 8s,16s,32S總共63s,第6次發出後還要等64s才知道第6次也超時了,所以總共需要 1s + 2s + 4s+ 8s+ 16s + 32s+64S =127S,TCP才會斷開連接。
因此上述問題描述中
“連接超時”計算公式為:1s + 2s + 4s+ 8s+ 16s + 32s+64S =127S
“建連耗時”計算公式與實際重試次數有關,以5次重試為例:1s + 2s + 4s+ 8s+ 16s + 32s=63S
查詢資料得知TCP Retransmission問題很大可能與tcp_tw_recycle設置有關,在此參數開啟後,服務端會對TCP包中timestamp有效性進行校驗,數據包中的timestamp理應是順序遞增,如最新的數據包timestamp小於前一個包的timestamp,服務端則認為最新的數據包已過時從而丟棄,此問題常出現在NAT網路,如負載均衡設備後面,因為數據包經過轉發,source_ip相同,但是後端不同機器的timestamp不同。
檢查資料庫伺服器配置,發現tcp_tw_recycle功能被開啟,同時網卡統計中存在因為時間戳被拒的數據包信息
netstat -s |grep reject
251286 passive connections rejected because of time stamp
795 packets rejects in established connections because of timestamp關閉tcp_tw_recycle功能後,應用連接資料庫恢復正常。本案例中為何資料庫伺服器重啟後應用報錯,那是因為參數先前只是做了動態關閉,沒有修改配置文件固化,重啟後讀到舊的配置從而導致應用突然報錯。
【問題重現】
本案例中的應用伺服器與後端資料庫直連,並不在NAT網路中,那理論上特定機器發送給DB的TCP包中timestamp數值是遞增,不會出現亂序丟包問題,但實際抓包中的timestamp是亂序的,忽大忽小,沒有規律性。
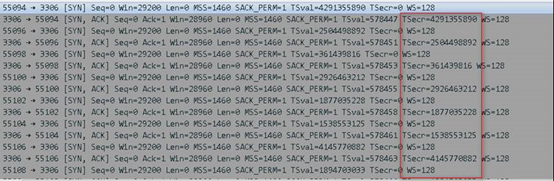
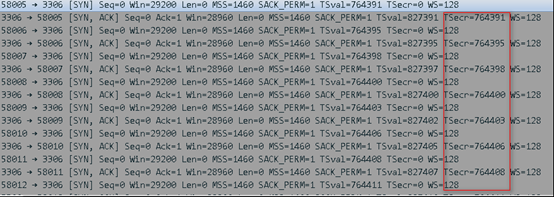
在不同Kernel版本環境中模擬用戶請求,發現在不同內核環境中,timestamp行為有明顯差異
Kernel 4.10.13,TSecr(請求方timestamp)隨機
Kernel 3.10,TSecr(請求方timestamp)遞增
查詢資料發現timestamp生成演算法在linux kernel 4.10之後進行了調整,加入偏移因數,從而變為隨機性。因此如開啟了tcp_tw_recycle,即使在非NAT網路環境中也會出現丟包問題,tcp_tw_recycle的弊端更為突顯,因此在4.12內核中被移除
【結論】
tcp_tw_recycle在高版本內核中弊大於利,應保持系統預設設置,關閉參數。
【參考資料】
https://mp.weixin.qq.com/s/uwykopNnkcRL5JXTVufyBw
http://80x86.io/post/linux-kernel-v4.10.1-tcp-timestamps-random-offset-problem

