
SparkSql 是架構在 Spark 計算框架之上的分散式 Sql 引擎,使用 DataFrame 和 DataSet 承載結構化和半結構化數據來實現數據複雜查詢處理,提供的 DSL可以直接使用 scala 語言完成 Sql 查詢,同時也使用 thriftserver 提供服務化的 Sql 查詢... ...
本文首發於 vivo互聯網技術 微信公眾號 https://mp.weixin.qq.com/s/YPN85WBNcnhk8xKjTPTa2g
作者:李勇
目錄:
1.SparkSql
2.連接查詢和連接條件
3.謂詞下推
4.內連接查詢中的謂詞下推規則
4.1.Join後條件通過AND連接
4.2.Join後條件通過OR連接
4.3.分區表使用OR連接過濾條件
1.SparkSql
SparkSql 是架構在 Spark 計算框架之上的分散式 Sql 引擎,使用 DataFrame 和 DataSet 承載結構化和半結構化數據來實現數據複雜查詢處理,提供的 DSL可以直接使用 scala 語言完成 Sql 查詢,同時也使用 thriftserver 提供服務化的 Sql 查詢功能。
SparkSql 提供了 DataSource API ,用戶通過這套 API 可以自己開發一套 Connector,直接查詢各類數據源,數據源包括 NoSql、RDBMS、搜索引擎以及 HDFS 等分散式文件系統上的文件等。和 SparkSql 類似的系統有 Hive、PrestoDB 以及 Impala,這類系統都屬於所謂的" Sql on Hadoop "系統,每個都相當火爆,畢竟在這個不搞 SQL 就是耍流氓的年代,沒 SQL 確實很難找到用戶使用。
2.連接查詢和連接條件
Sql中的連接查詢(join),主要分為內連接查詢(inner join)、外連接查詢(outter join)和半連接查詢(semi join),具體的區別可以參考wiki的解釋。
連接條件(join condition),則是指當這個條件滿足時兩表的兩行數據才能"join"在一起被返回,例如有如下查詢:

其中的"LT.id=RT.idAND LT.id>1"這部分條件被稱為"join中條件",直接用來判斷被join的兩表的兩行記錄能否被join在一起,如果不滿足這個條件,兩表的這兩行記錄並非全部被踢出局,而是根據連接查詢類型的不同有不同的處理,所以這並非一個單表的過濾過程或者兩個表的的“聯合過濾”過程;而where後的"RT.id>2"這部分被稱為"join後條件",這裡雖然成為"join後條件",但是並非一定要在join後才能去過濾數據,只是說明如果在join後進行過濾,肯定可以得到一個正確的結果,這也是我們後邊分析問題時得到正確結果的基準方法。
3.謂詞下推
所謂謂詞(predicate),英文定義是這樣的:A predicate is a function that returns bool (or something that can be implicitly converted to bool),也就是返回值是true或者false的函數,使用過scala或者spark的同學都知道有個filter方法,這個高階函數傳入的參數就是一個返回true或者false的函數。
但是如果是在sql語言中,沒有方法,只有表達式。where後邊的表達式起的作用正是過濾的作用,而這部分語句被sql層解析處理後,在資料庫內部正是以謂詞的形式呈現的。
那麼問題來了,謂詞為什麼要下推呢? SparkSql中的謂詞下推有兩層含義,第一層含義是指由誰來完成數據過濾,第二層含義是指何時完成數據過濾。要解答這兩個問題我們需要瞭解SparkSql的Sql語句處理邏輯,大致可以把SparkSql中的查詢處理流程做如下的劃分:
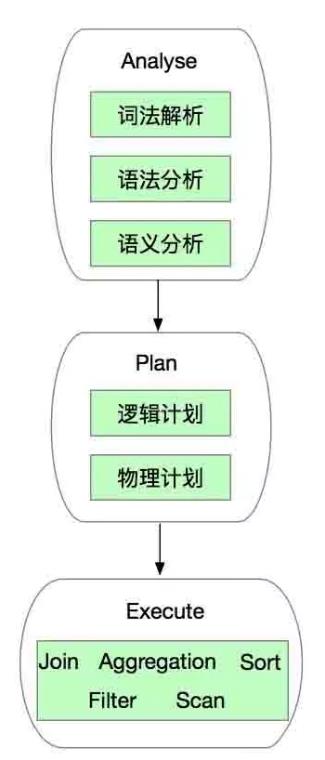
SparkSql首先會對輸入的Sql語句進行一系列的分析(Analyse),包括詞法解析(可以理解為搜索引擎中的分詞這個過程)、語法分析以及語義分析(例如判斷database或者table是否存在、group by必須和聚合函數結合等規則);之後是執行計劃的生成,包括邏輯計劃和物理計劃。其中在邏輯計劃階段會有很多的優化,對謂詞的處理就在這個階段完成;而物理計劃則是RDD的DAG圖的生成過程;這兩步完成之後則是具體的執行了(也就是各種重量級的計算邏輯,例如join、groupby、filter以及distinct等),這就會有各種物理操作符(RDD的Transformation)的亂入。
能夠完成數據過濾的主體有兩個,第一是分散式Sql層(在execute階段),第二個是數據源。那麼謂詞下推的第一層含義就是指由Sql層的Filter操作符來完成過濾,還是由Scan操作符在掃描階段完成過濾。
上邊提到,我們可以通過封裝SparkSql的Data Source API完成各類數據源的查詢,那麼如果底層數據源無法高效完成數據的過濾,就會執行全局掃描,把每條相關的數據都交給SparkSql的Filter操作符完成過濾,雖然SparkSql使用的Code Generation技術極大的提高了數據過濾的效率,但是這個過程無法避免大量數據的磁碟讀取,甚至在某些情況下會涉及網路IO(例如數據非本地化存儲時);如果底層數據源在進行掃描時能非常快速的完成數據的過濾,那麼就會把過濾交給底層數據源來完成(至於哪些數據源能高效完成數據的過濾以及SparkSql又是如何完成高效數據過濾的則不是本文討論的重點,會在其他系列的文章中介紹)。
那麼謂詞下推第二層含義,即何時完成數據過濾則一般是在指連接查詢中,是先對單表數據進行過濾再和其他表連接還是在先把多表進行連接再對連接後的臨時表進行過濾,則是本系列文章要分析和討論的重點。
4.內連接查詢中的謂詞下推規則
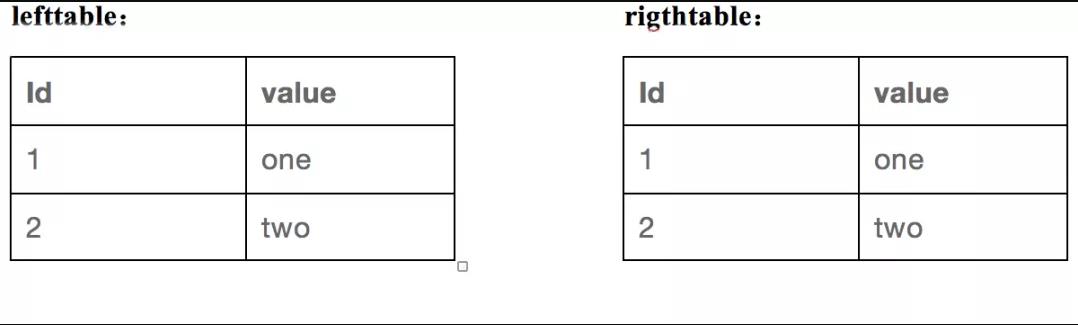
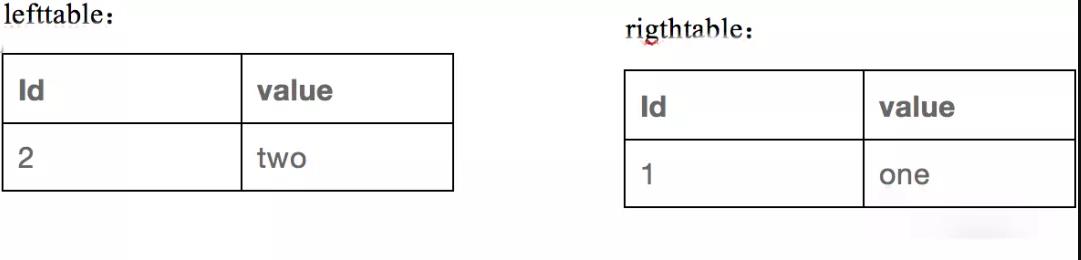
假設我們有兩張表,表結構很簡單,數據也都只有兩條,但是足以講清楚我們的下推規則,兩表如下,一個lefttable,一個righttable:
4.1.Join後條件通過AND連接
先來看一條查詢語句:

這個查詢是一個內連接查詢,join後條件是用and連接的兩個表的過濾條件,假設我們不下推,而是先做內連接判斷,這時是可以得到正確結果的,步驟如下:
-
左表id為1的行在右表中可以找到,即這兩行數據可以"join"在一起
-
左表id為2的行在右表中可以找到,這兩行也可以"join"在一起
至此,join的臨時結果表(之所以是臨時表,因為還沒有進行過濾)如下:
然後使用where條件進行過濾,顯然臨時表中的第一行不滿足條件,被過濾掉,最後結果如下:

來看看先進行謂詞下推的情況。先對兩表進行過濾,過濾的結果分別如下:
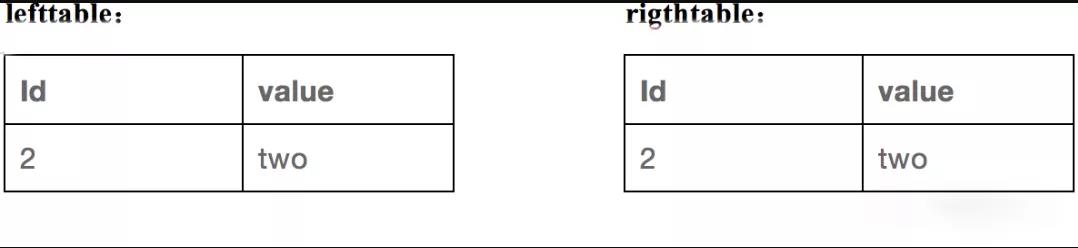
然後再對這兩個過濾後的表進行內連接處理,結果如下:

可見,這和先進行join再過濾得到的結果一致。
4.2.Join後條件通過OR連接
再來看一條查詢語句:

我們先進行join處理,臨時表的結果如下:
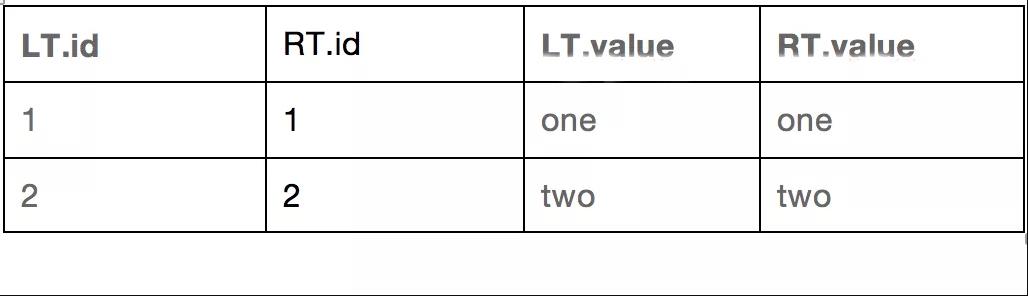
然後使用where條件進行過濾,最終查詢結果如下:
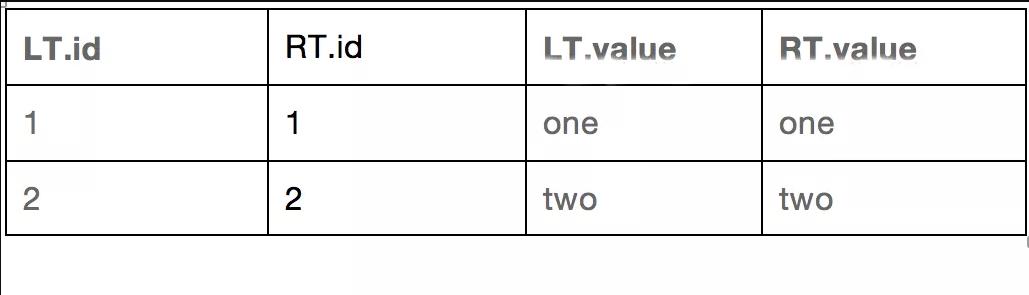
如果我們先使用where條件後每個表各自的過濾條件進行過濾,那麼兩表的過濾結果如下:
然後對這兩個臨時表進行內連接處理,結果如下:

表格有問題吧,只有欄位名,沒有欄位值,怎麼回事?是的,你沒看錯,確實沒有值,因為左表過濾結果只有id為1的行,右表過濾結果只有id為2的行,這兩行是不能內連接上的,所以沒有結果。
那麼為什麼where條件中兩表的條件被or連接就會出現錯誤的查詢結果呢?分析原因主要是因為,對於or兩側的過濾條件,任何一個滿足條件即可以返回TRUE,那麼對於"LT.value = 'two' OR RT.value = 'two' "這個查詢條件,如果使用LT.value='two'把只有LT.value為'two'的左表記錄過濾出來,那麼對於左表中LT.value不為two的行,他們可能在跟右表使用id欄位連接上之後,右表的RT.value恰好為two,也滿足"LT.value = 'two' OR RT.value = 'two' ",但是可惜呀可惜,這行記錄因為之前的粗暴處理,已經被過濾掉,結果就是得到了錯誤的查詢結果。所以這種情況下謂詞是不能下推的。
但是OR連接兩表join後條件也有兩個例外,這裡順便分析第一個例外。第一個例外是過濾條件欄位恰好為Join欄位,比如如下的查詢:

在這個查詢中,join後條件依然是使用OR連接兩表的過濾條件,不同的是,join中條件不再是id相等,而是value欄位相等,也就是說過濾條件欄位恰好就是join條件欄位。大家可以自行採用上邊的分步法分析謂詞下推和不下推時的查詢結果,得到的結果是相同的。
我們來看看上邊不能下推時出現的情況在這種查詢里會不會出現。對於左表,如果使用LT.value='two'過濾掉不符合條件的其他行,那麼因為join條件欄位也是value欄位,說明在左表中LT.value不等於two的行,在右表中也不能等於two,否則就不滿足"LT.value=RT.value"了。這裡其實有一個條件傳遞的過程,通過join中條件,已經在邏輯上提前把兩表整合成了一張表。
至於第二個例外,則涉及了SparkSql中的一個優化,所以需要單獨介紹。
4.3.分區表使用OR連接過濾條件
如果兩個表都是分區表,會出現什麼情況呢?我們先來看如下的查詢:

此時左表和右表都不再是普通的表,而是分區表,分區欄位是pt,按照日期進行數據分區。同時兩表查詢條件依然使用OR進行連接。試想,如果不能提前對兩表進行過濾,那麼會有非常巨量的數據要首先進行連接處理,這個代價是非常大的。但是如果按照我們在2中的分析,使用OR連接兩表的過濾條件,又不能隨意的進行謂詞下推,那要如何處理呢?SparkSql在這裡使用了一種叫做“分區裁剪”的優化手段,即把分區並不看做普通的過濾條件,而是使用了“一刀切”的方法,把不符合查詢分區條件的目錄直接排除在待掃描的目錄之外。
我們知道分區表在HDFS上是按照目錄來存儲一個分區的數據的,那麼在進行分區裁剪時,直接把要掃描的HDFS目錄通知Spark的Scan操作符,這樣,Spark在進行掃描時,就可以直接咔嚓掉其他的分區數據了。但是,要完成這種優化,需要SparkSql的語義分析邏輯能夠正確的分析出Sql語句所要表達的精確目的,所以分區欄位在SparkSql的元數據中也是獨立於其他普通欄位,進行了單獨的標示,就是為了方便語義分析邏輯能區別處理Sql語句中where條件里的這種特殊情況。
更多內容敬請關註 vivo 互聯網技術 微信公眾號

註:轉載文章請先與微信號:labs2020 聯繫。


