
一 對象的記憶體佈局: 在HotSpot虛擬機中,對象在記憶體中存儲的佈局可以分為3塊區域:對象頭(Header),實例數據(Instance Data)和對齊填充(Padding)。 HotSpot的對象頭包括兩部分信息,一部分存儲對象運轉時自身信息,例如hashCode,GC分代年齡,鎖狀態標誌,線 ...
一 對象的記憶體佈局:
在HotSpot虛擬機中,對象在記憶體中存儲的佈局可以分為3塊區域:對象頭(Header),實例數據(Instance Data)和對齊填充(Padding)。
HotSpot的對象頭包括兩部分信息,一部分存儲對象運轉時自身信息,例如hashCode,GC分代年齡,鎖狀態標誌,線程持有的鎖,偏向線程id,偏向時間戳等,這部分數據的長度在32和64位虛擬機中分別為32和64位,官方稱之為“Mark World”。對象在運行時產生的數據很多,其實早已經超出了32或64位BitMap結構能承載的限度,考慮到虛擬機的空間效率,MarkWord被設計為一個非固定的數據結構以便在極小的記憶體空間中儘可能多的存儲信息,他會根據對象的狀態復用自己的記憶體,例如:在32位虛擬機中,如果對象處於未被鎖定的狀態下時,那32bit中25bit用於存儲對象的哈希碼,4bit存儲對象分代年齡,2bit存儲鎖標誌位,1bit固定為0,而在其他狀態(輕量級鎖定,重量級鎖定,GC標記,可偏向)下存儲結構如下:
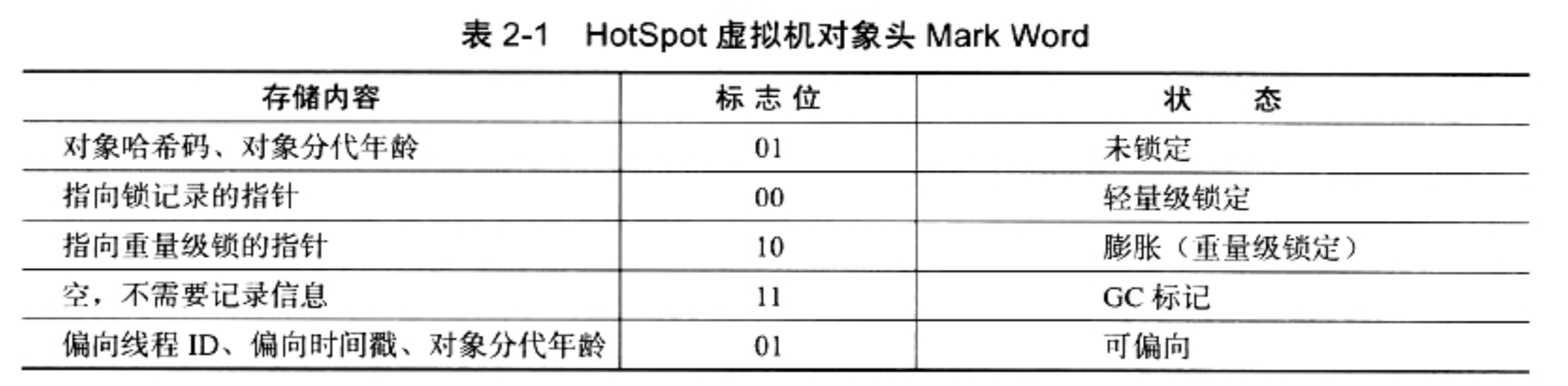
對象頭的另一部分是類型指針,即對象指向它類元數據的指針,虛擬機通過該指針來確定這個對象是哪個類的實例,但並不是所有的虛擬機都是這樣實現判斷類型的。另外,如果對象是一個數組,那頭對象中還需要有一塊記錄數組長度的數據,因為虛擬機可以通過普通對象的元數據確定對象的大小,但是從數組的元數據卻無法確定數組的大小。
接下來的實例數據部分存儲的是對象的有效信息,也就是在程式代碼中定義的各種類型的欄位內容,無論是在父類中繼承下來的還是在子類中定義的,都需要記錄起來,這部分的存儲順序會受到虛擬機分配策略參數和欄位在代碼中定義順序的影響。HotSpot定義的策略為long/doubles,ints,shorts/chars,bytes/booleans,oops,從分配策略看出,相同寬度的欄位總是被分配到一起,在滿足這個前提下,父類中定義的變數會出現在子類之前。
第三部分對齊填充並不是必須存在的,也沒有特殊的意義,但是由於HotSpot VM的自動記憶體管理系統要求對象的起始地址必須是8的整數倍,換句話說,每一個對象的大小都必須是8的整數倍,當對象所需要的記憶體不是8的整數倍時,才會使用對齊填充對齊來滿足這一要求。
二 對象的訪問定位
通過以上的步驟,一個對象就完成了記憶體分配和必要的初始化,那麼我們如何才能定位到我們需要使用的對象呢?
Java需要通過棧上的reference數據來操作堆上的具體對象,reference類型在Java虛擬機規範中只定義了一個指向對象的引用,但並沒有規定以那種方式去定位和訪問堆中對象的具體位置,所以對象的訪問方式也是取決於虛擬機的實現方式,目前主流的實現方式有使用句柄和直接指針兩種。
句柄:
如果使用這種實現方式,那麼堆中就需要劃分出一片記憶體來作為句柄池,reference中存儲的就是對象的句柄地址,而在句柄中包含了對象的實例數據與類型數據各自的地址信息,如下圖: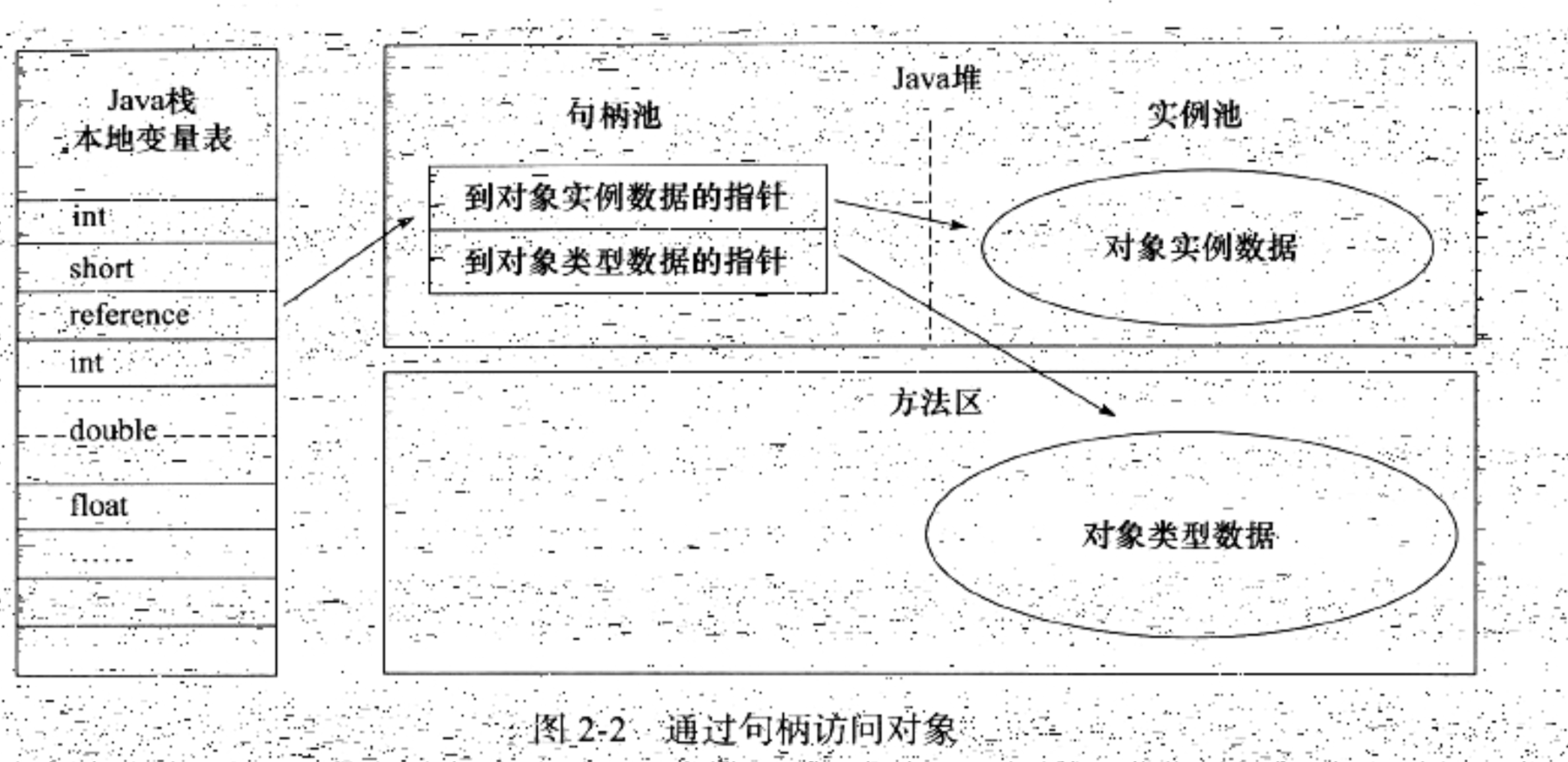
使用直接指針進行訪問,則reference中直接存儲的就是對象地址,但是Java堆對象的佈局中就必須考慮如何放置訪問類型數據的相關信息,如下圖所示:

這兩種方式各有好處,使用直接指針的好處就是更快,節省了一次指針定位的時間開銷,而使用句柄的方式,在對象被移動(垃圾回收)時,不需要修改reference中的地址數據,只需修改句柄池中的數據。
HotSpot當前採用的是直接指針的方式來訪問對象。


