
眾所周知,在sqlserver中,表變數最大的特性之一就是沒有統計信息,無法較為準備預估其數據分佈情況,因此不適合參與較為複雜的SQL運算。當SQL相對簡單的時候,使用表變數,在某些場景下,即便是對錶變數的預估沒有產生偏差的情況下,仍舊會有問題。sqlserver的優化引擎對於表變數的支持十分不友好 ...
眾所周知,在sqlserver中,表變數最大的特性之一就是沒有統計信息,無法較為準備預估其數據分佈情況,因此不適合參與較為複雜的SQL運算。
當SQL相對簡單的時候,使用表變數,在某些場景下,即便是對錶變數的預估沒有產生偏差的情況下,仍舊會有問題。
sqlserver的優化引擎對於表變數的支持十分不友好,再次對錶變數的使用產生了警惕。
測試環境搭建
理搭建一個簡單的測試環境,來驗證本文的想要表達的主題,
測試表TestTableVariable 上有KeyCode1 ~KeyCode5 5個欄位,分別創建非聚集索引,
對於數據分佈,刻意設計出當前這種場景:KeyCode1 ~KeyCode5的欄位值,分別趨於稀疏(非空值的越來越少,null值越來越多)
如下,寫入100W行數據,就可以出來下麵要表達的效果了。
create table TestTableVariable ( Id int identity(1,1), KeyCode1 varchar(10), KeyCode2 varchar(10), KeyCode3 varchar(10), KeyCode4 varchar(10), KeyCode5 varchar(10), CreateDate datetime ) alter table TestTableVariable add constraint pk_TestTableVariable primary key(Id) create index idx_KeyCode1 on TestTableVariable(KeyCode1) create index idx_KeyCode2 on TestTableVariable(KeyCode2) create index idx_KeyCode3 on TestTableVariable(KeyCode3) create index idx_KeyCode4 on TestTableVariable(KeyCode4) create index idx_KeyCode5 on TestTableVariable(KeyCode5) insert into TestTableVariable(KeyCode1,CreateDate) values (CONCAT('XX',CAST(RAND()*1000000 AS INT)),GETDATE()) GO 1000000 update TestTableVariable set KeyCode2 = KeyCode1 where Id%10 = 0 update TestTableVariable set KeyCode3 = KeyCode1 where Id%1000 = 0 update TestTableVariable set KeyCode4 = KeyCode1 where Id%10000= 0 update TestTableVariable set KeyCode5 = KeyCode1 where Id%100000 = 0 GO
問題重現
對於普通的查詢,找一個KeyCode1 ~KeyCode5均有值的條件進行查詢,執行計劃都在預期之中,均可以用到索引,不過多表述
select * from TestTableVariable where KeyCode1 = 'XX156876' select * from TestTableVariable where KeyCode2 = 'XX156876' select * from TestTableVariable where KeyCode3 = 'XX156876' select * from TestTableVariable where KeyCode4 = 'XX156876' select * from TestTableVariable where KeyCode5 = 'XX156876'
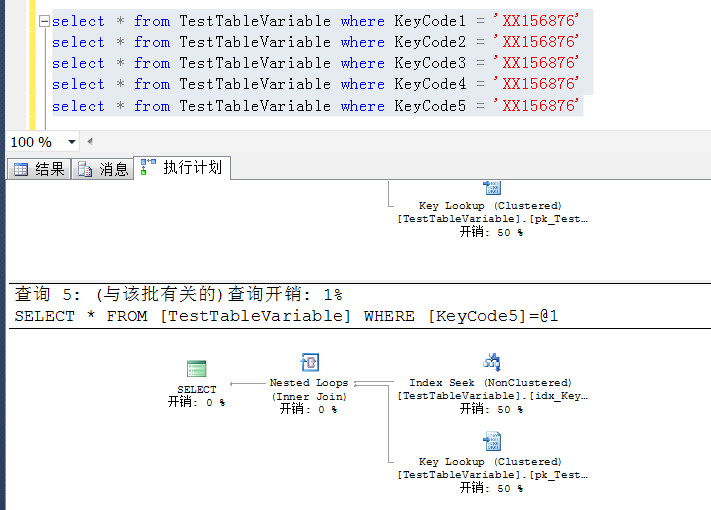
下麵將查詢條件寫入一張表變,讓表變數與物理表TestTableVariable進行join
如下語句,分別用KeyCode1 ~KeyCode5進行查詢,對於非空值分佈相對較多的KeyCode1 ~KeyCode3,做查詢的時候,執行計劃也在預期之中(索引查找)
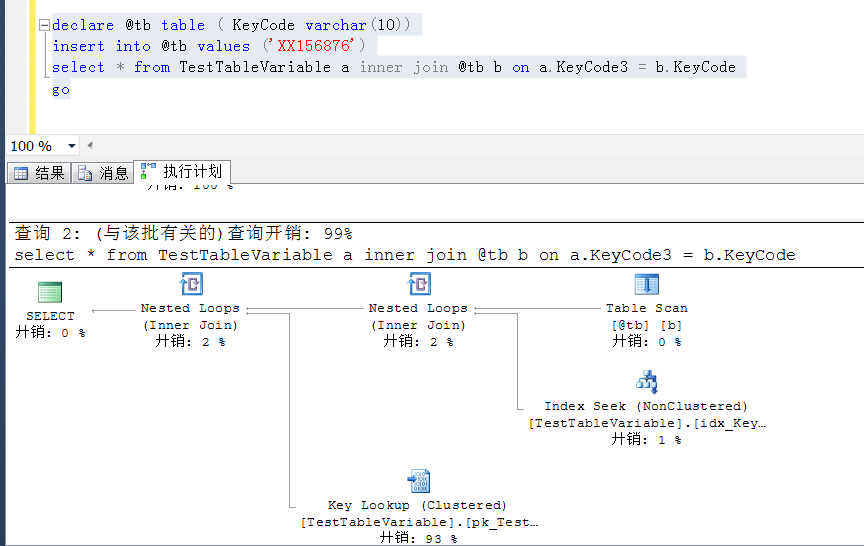
從非空值分佈越來越少的KeyCode4開始,執行計劃開始變成非預期的索引查找,變成了表掃描
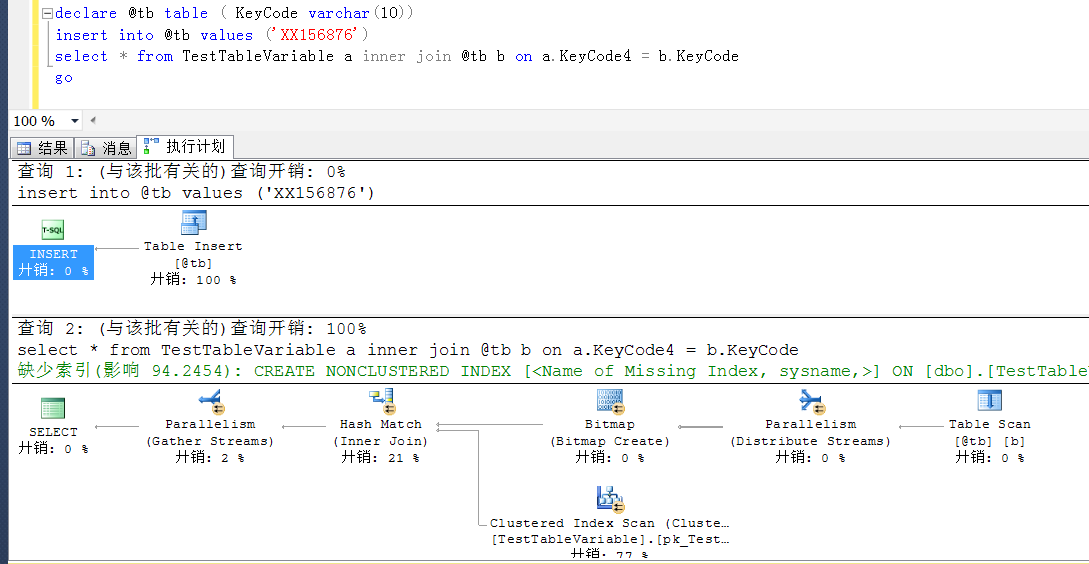
KeyCode5依舊是非預期的索引查找,也是表掃描
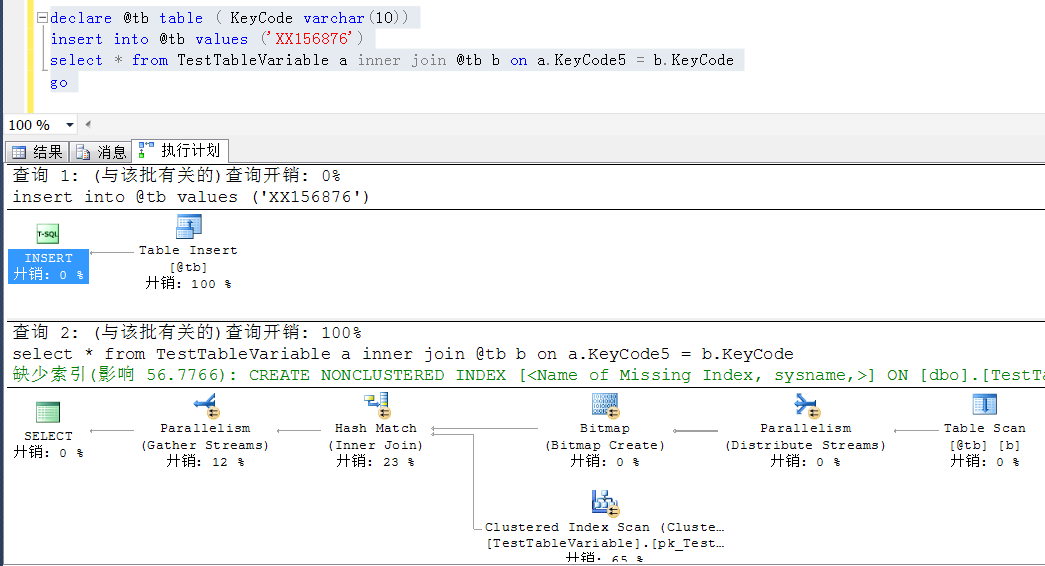
這裡不是提出類似問題的解決辦法的,當然解決辦法也比較簡單,
1,添加一個不影響邏輯的條件,相當於簡單地改寫SQL,如下增加where a.KeyCode5 is not null 篩選條件,因為null值不等於任何值,包括null值,因此增加這個條件不會影響這個SQL的邏輯
2,將表變數的數據寫入臨時表,讓臨時表與測試表JOIN,其他不做任何修改
兩種方式都可以達到index seek的效果。
declare @tb table ( KeyCode varchar(10)) insert into @tb values ('XX156876') select * from TestTableVariable a inner join @tb b on a.KeyCode5 = b.KeyCode where a.KeyCode5 is not null go declare @tb table ( KeyCode varchar(10)) insert into @tb values ('XX156876') select * into #t from @tb select * from TestTableVariable a inner join #t b on a.KeyCode5 = b.KeyCode go
以下是兩者的執行計劃,都是index seek
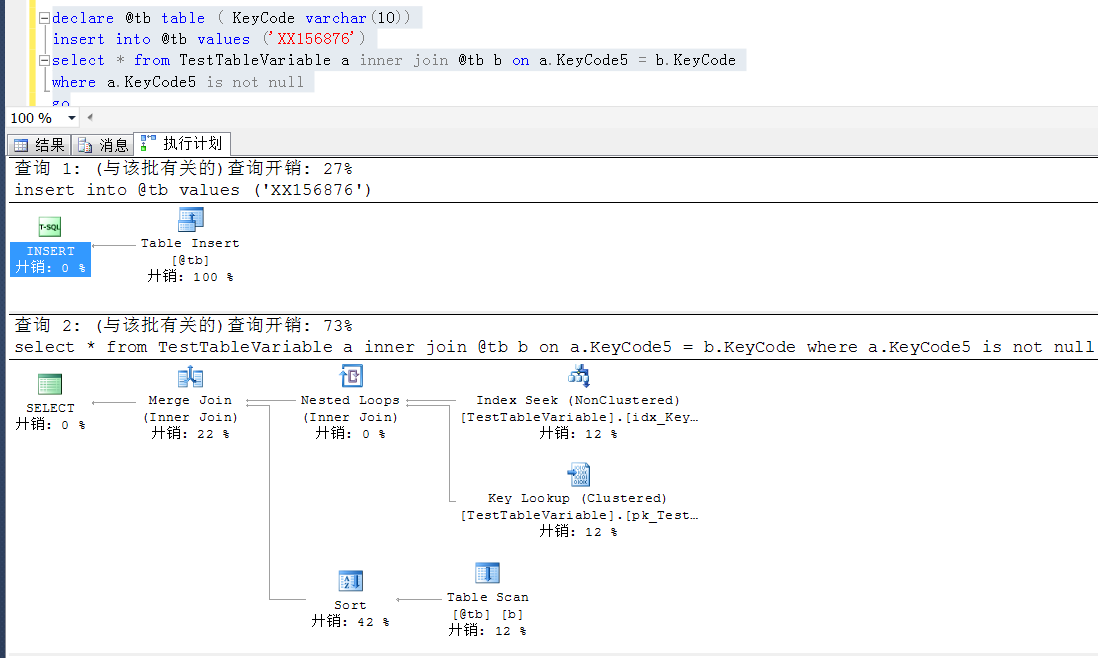
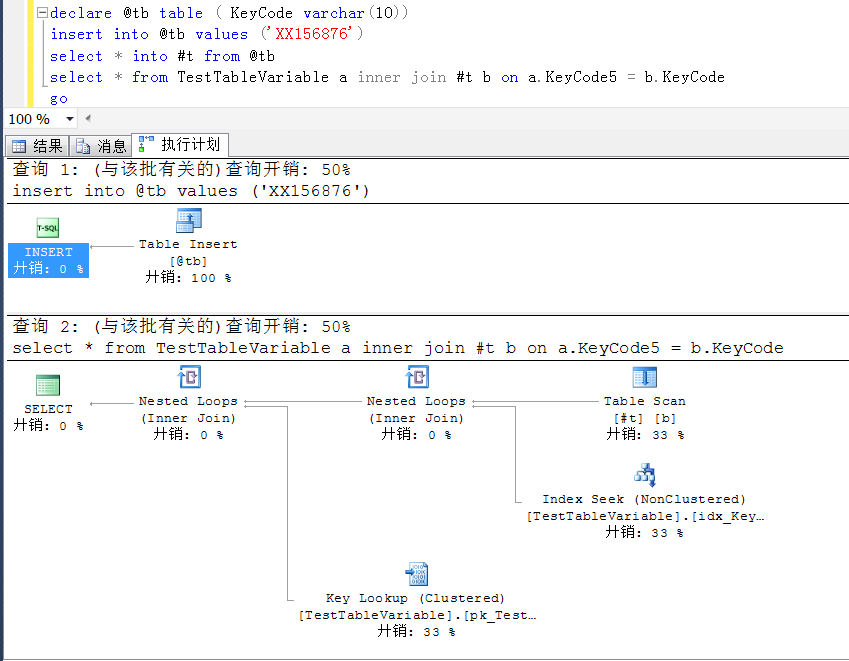
以上是解決辦法,暫不過多表述。
存在的疑問
問題就在於:
即便是表變數沒有統計信息,sqlserver預設情況下總是會預估為1行(不加任何查詢提示),既然預估為1行,在當前情況下也是準確的,不認為是預估出現偏差導致執行計划出現非最優。
對於臨時表,同樣是1行數據,來驅動物理表TestTableVariable,就可以正常使用到index seek,而表變數不行?
再就是,對於TestTableVariable表上的統計信息,經過幾個SQL查詢過後,觸發了統計信息的更新,統計信息也相對準確地預估到了999999行為null,1行是一個特定的值XX156876)
1,對於物理表TestTableVariable與表變數的join,由於NULL值跟任何值對比都是沒有結果的,換句話說就是,不管表變數里的數據量有多少,按照統計信息中的預估,這個查詢對於TestTableVariable這個表來說,最多只有1行數據(統計信息中的那個非NULL)的數據參與查詢運算
2,對於表變數,既然預估為1行,哪有為什麼不使用索引查找的方式,就算是用不到索引查找,join雙方,按照預估,都只有一行數據參與運算的情況下,為什麼竟然要選擇HASH JOIN?
表變數參數join的時候,優化器為什麼連這麼一個簡單的推斷邏輯都做不到,並沒有非常複雜的邏輯,或者說數據分佈異常的情況在裡面,最終選擇了最差的執行計划進行運算。
反觀臨時表,用臨時表join的情況下,一切都回歸到預期的索引查找,可否認為,sqlserver對錶變數的join或者說運算,支持的非常不友好(2014~2016均沒有改善)。
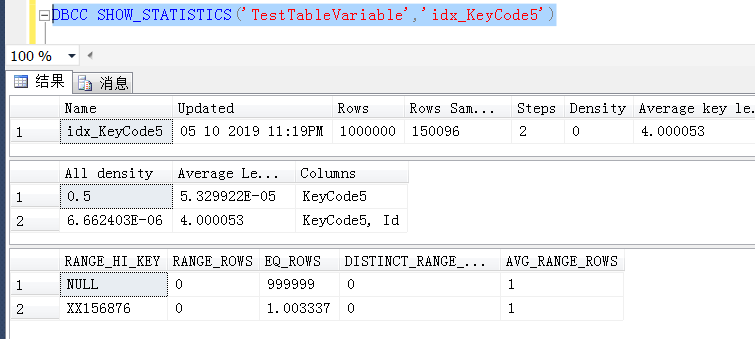
後面懷疑是不是KeyCode5上的統計信息取樣百分比不夠大,造成的執行計劃錯誤,嘗試100%取樣
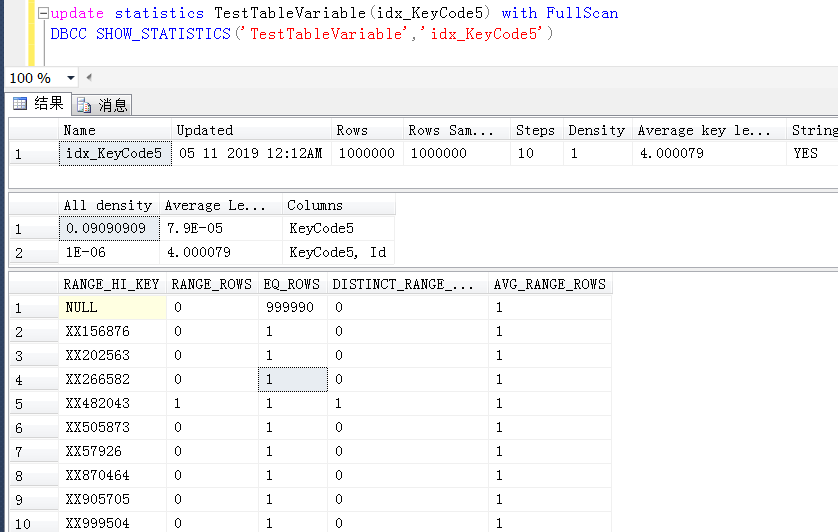
繼續測試,問題依舊

當前這個case,並不是那種經典的,因為對錶變數預估偏差造成的執行計劃錯誤,暫時也無法理解,sqlserver為什麼會對錶變數參數參與的join,在當前這種case中,採用如此保守的執行方式。
越來越多的case證明,在sqlserver中使用表變數參與join,就好比是一顆定時炸彈,隨時可以引爆你的系統,看來要慎重。


