
複製集 一、複製集概述: Mongodb複製集(replica set)由一組Mongod實例(進程)組成,包含一個Primary節點和多個Secondary節點,Mongodb Driver(客戶端)的所有數據都寫入Primary,Secondary通過oplog來同步Primary的數據,保證主 ...
----------------------------------------複製集----------------------------------------
一、複製集概述:
Mongodb複製集(replica set)由一組Mongod實例(進程)組成,包含一個Primary節點和多個Secondary節點,Mongodb Driver(客戶端)的所有數據都寫入Primary,Secondary通過oplog來同步Primary的數據,保證主從節點數據的一致性;複製集在完成主從複製的基礎上,通過心跳機制,一旦Primary節點出現宕機,則觸發選舉一個新的主節點,剩下的secondary節點指向新的Primary,時間應該在10-30s內完成感知Primary節點故障,實現高可用資料庫集群
特點:
Primary節點是唯一的,但不是固定的
由大多數據原則保證數據的一致性
Secondary節點無法寫入(預設情況下,不使用驅動連接時,也是不能查詢的)
相對於傳統的主從結構,複製集可以自動容災
二、複製集原理:
角色(按是否存儲數據劃分):
Primary:主節點,由選舉產生,負責客戶端的寫操作,產生oplog日誌文件
Secondary:從節點,負責客戶端的讀操作,提供數據的備份和故障的切換
Arbiter:仲裁節點,只參與選舉的投票,不會成為primary,也不向Primary同步數據,若部署了一個2個節點的複製集,1個Primary,1個Secondary,任意節點宕機,複製集將不能提供服務了(無法選出Primary),這時可以給複製集添加一個Arbiter節點,即使有節點宕機,仍能選出Primary
角色(按類型區分):
Standard(標準):這種是常規節點,它存儲一份完整的數據副本,參與投票選舉,有可能成為主節點
Passive(被動):存儲完整的數據副本,參與投票,不能成為活躍節點
Arbiter(投票):仲裁節點只參與投票,不接收複製的數據,也不能成為活躍節點
註:每個參與節點(非仲裁者)有個優先權(0-1000),優先權(priority)為0則是被動的,不能成為活躍節點,優先權不為0的,按照由大到小選出活躍節點,優先值一樣的則看誰的數據比較新
註:Mongodb 3.0里,複製集成員最多50個,參與Primary選舉投票的成員最多7個
選舉:
每個節點通過優先順序定義出節點的類型(標準、被動、投票)
標準節點通過對比自身數據進行選舉出primary節點或者secondary節點
影響選舉的因素:
1.心跳檢測:複製集內成員每隔兩秒向其他成員發送心跳檢測信息,若10秒內無響應,則標記其為不可用
2.連接:在多個節點中,最少保證兩個節點為活躍狀態,如果集群中共三個節點,掛掉兩個節點,那麼剩餘的節點無論狀態是primary還是處於選舉過程中,都會直接被降權為secondary
觸發選舉的情況:
1.初始化狀態
2.從節點們無法與主節點進行通信
3.主節點辭職
主節點辭職的情況:
1.在接收到replSetStepDown命令後
2.在現有的環境中,其他secondary節點的數據落後於本身10s內,且擁有更高優先順序
3.當主節點無法與群集中多數節點通信
註:當主節點辭職後,主節點將關閉自身所有的連接,避免出現客戶端在從節點進行寫入操作
----------------------------------------分片----------------------------------------
一、分片概述:
分片(sharding)是指將資料庫拆分,將其分散在不同的機器上的過程。分片集群(sharded cluster)是一種水平擴展資料庫系統性能的方法,能夠將數據集分散式存儲在不同的分片(shard)上,每個分片只保存數據集的一部分,MongoDB保證各個分片之間不會有重覆的數據,所有分片保存的數據之和就是完整的數據集。分片集群將數據集分散式存儲,能夠將負載分攤到多個分片上,每個分片只負責讀寫一部分數據,充分利用了各個shard的系統資源,提高資料庫系統的吞吐量
註:mongodb3.2版本後,分片技術必須結合複製集完成
應用場景:
1.單台機器的磁碟不夠用了,使用分片解決磁碟空間的問題
2.單個mongod已經不能滿足寫數據的性能要求。通過分片讓寫壓力分散到各個分片上面,使用分片伺服器自身的資源
3.想把大量數據放到記憶體里提高性能。和上面一樣,通過分片使用分片伺服器自身的資源
二、分片存儲原理:
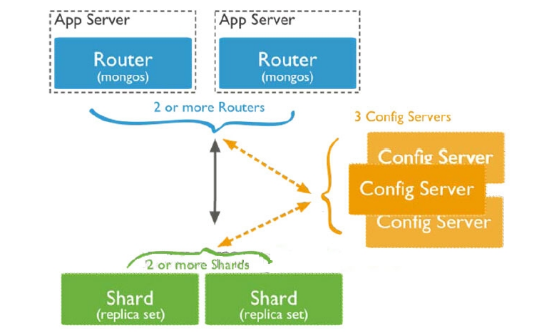
存儲方式:
數據集被拆分成數據塊(chunk),每個數據塊包含多個doc,數據塊分散式存儲在分片集群中
角色:
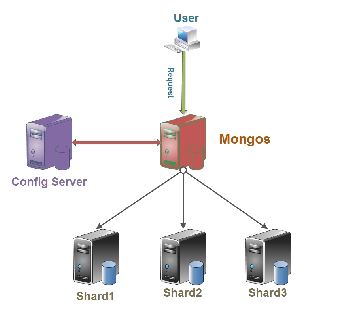
Config server:MongoDB負責追蹤數據塊在shard上的分佈信息,每個分片存儲哪些數據塊,叫做分片的元數據,保存在config server上的資料庫 config中,一般使用3台config server,所有config server中的config資料庫必須完全相同(建議將config server部署在不同的伺服器,以保證穩定性)
Shard server:將數據進行分片,拆分成數據塊(chunk),數據塊真正存放的單位
Mongos server:資料庫集群請求的入口,所有的請求都通過mongos進行協調,查看分片的元數據,查找chunk存放位置,mongos自己就是一個請求分發中心,在生產環境通常有多mongos作為請求的入口,防止其中一個掛掉所有的mongodb請求都沒有辦法操作
總結:
應用請求mongos來操作mongodb的增刪改查,配置伺服器存儲資料庫元信息,並且和mongos做同步,數據最終存入在shard(分片)上,為了防止數據丟失,同步在副本集中存儲了一份,仲裁節點在數據存儲到分片的時候決定存儲到哪個節點
三、分片的片鍵
片鍵是文檔的一個屬性欄位或是一個複合索引欄位,一旦建立後則不可改變,片鍵是拆分數據的關鍵的依據,如若在數據極為龐大的場景下,片鍵決定了數據在分片的過程中數據的存儲位置,直接會影響集群的性能
註:創建片鍵時,需要有一個支撐片鍵運行的索引
片鍵分類:
1.遞增片鍵:使用時間戳,日期,自增的主鍵,ObjectId,_id等,此類片鍵的寫入操作集中在一個分片伺服器上,寫入不具有分散性,這會導致單台伺服器壓力較大,但分割比較容易,這台伺服器可能會成為性能瓶頸

語法解析: mongos> use 庫名 mongos> db.集合名.ensureIndex({"鍵名":1}) ##創建索引 mongos> sh.enableSharding("庫名") ##開啟庫的分片 mongos> sh.shardCollection("庫名.集合名",{"鍵名":1}) ##開啟集合的分片並指定片鍵
2.哈希片鍵:也稱之為散列索引,使用一個哈希索引欄位作為片鍵,優點是使數據在各節點分佈比較均勻,數據寫入可隨機分發到每個分片伺服器上,把寫入的壓力分散到了各個伺服器上。但是讀也是隨機的,可能會命中更多的分片,但是缺點是無法實現範圍區分

3.組合片鍵: 資料庫中沒有比較合適的鍵值供片鍵選擇,或者是打算使用的片鍵基數太小(即變化少如星期只有7天可變化),可以選另一個欄位使用組合片鍵,甚至可以添加冗餘欄位來組合

4.標簽片鍵:數據存儲在指定的分片伺服器上,可以為分片添加tag標簽,然後指定相應的tag,比如讓10.*.*.*(T)出現在shard0000上,11.*.*.*(Q)出現在shard0001或shard0002上,就可以使用tag讓均衡器指定分發



