
spark的機器學習庫,包含常見的學習演算法和工具如分類、回歸、聚類、協同過濾、降維等使用演算法時都需要指定相應的數據集,下麵為大家介紹常用的spark ml 數據類型。1.本地向量(Local Vector)存儲在單台機器上,索引採用0開始的整型表示,值採用Double類型的值表示。Spark MLl ...
spark的機器學習庫,包含常見的學習演算法和工具如分類、回歸、聚類、協同過濾、降維等
使用演算法時都需要指定相應的數據集,下麵為大家介紹常用的spark ml 數據類型。
1.本地向量(Local Vector)
存儲在單台機器上,索引採用0開始的整型表示,值採用Double類型的值表示。Spark MLlib中支持兩種類型的矩陣,分別是密度向量(Dense Vector)和稀疏向量(Spasre Vector),密度向量會存儲所有的值包括零值,而稀疏向量存儲的是索引位置及值,不存儲零值,在數據量比較大時,稀疏向量才能體現它的優勢和價值
scala> import org.apache.spark.mllib.linalg.{Vector, Vectors}
註意:scala預設會導入scala.collection.immutable.Vector,所以必須顯式導入org.apache.spark.mllib.linalg.Vector
1.1密度向量,零值也存儲
scala> val dv: Vector = Vectors.dense(1.0, 0.0, 3.0)
1.2.1創建稀疏向量,指定元素的個數、索引及非零值,數組方式
基於索引(0,2)和值(1,3)創建稀疏向量
scala> val sv1: Vector = Vectors.sparse(3, Array(0, 2), Array(1.0, 3.0))
1.2.2 創建稀疏向量,指定元素的個數、索引及非零值,採用序列方式
scala> val sv2: Vector = Vectors.sparse(3, Seq((0, 1.0), (2, 3.0)))
2.帶類標簽的特征向量(Labeled point)
Labeled point是Spark MLlib中最重要的數據結構之一,它在無監督學習演算法中使用十分廣泛,它也是一種本地向量,只不過它提供了類的標簽,對於二元分類,它的標簽數據為0和1,而對於多類分類,它的標簽數據為0,1,2,…。它同本地向量一樣,同時具有Sparse和Dense兩種實現方式
scala> import org.apache.spark.mllib.regression.LabeledPoint
2.1LabeledPoint第一個參數是類標簽數據,第二參數是對應的特征數據
//密度
scala> val pos = LabeledPoint(1.0, Vectors.dense(1.0, 0.0, 3.0))
scala> println(pos.features)
scala> println(pos.label)
//稀疏
scala> val neg = LabeledPoint(0.0, Vectors.sparse(3, Array(0, 2), Array(1.0, 3.0)))
註意:第2個特征值為0,從編程的角度來說,這樣做可以減少記憶體的使用,並提高做矩陣內積時的運算速度
3.本地矩陣(Local matrix)
本地向量是由從0開始的整數下標和Double類型的數值組成。它有稠密向量(dense vector)和稀疏向量(sparse vertor)兩種。在列的主要順序中,它的非零輸入值存儲在壓縮的稀疏列(CSC)格式中
在一維數組[1.0、3.0、5.0、2.0、4.0、6.0]中,對應的矩陣大小(3、2):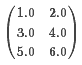
本地矩陣的基類是Matrix,提供了兩種實現 DenseMatrix和SparseMatrix. 推薦使用工廠方法實現的Matrices來創建本地矩陣.
scala> import org.apache.spark.mllib.linalg.{Matrix, Matrices}
3.1 創建稠密矩陣
scala> val dm: Matrix = Matrices.dense(3, 2, Array(1.0, 3.0, 5.0, 2.0, 4.0, 6.0))
3.2 創建稀疏矩陣
scala> val sm: Matrix = Matrices.sparse(3, 2, Array(0, 1, 3), Array(0, 2, 1), Array(9, 6, 8))
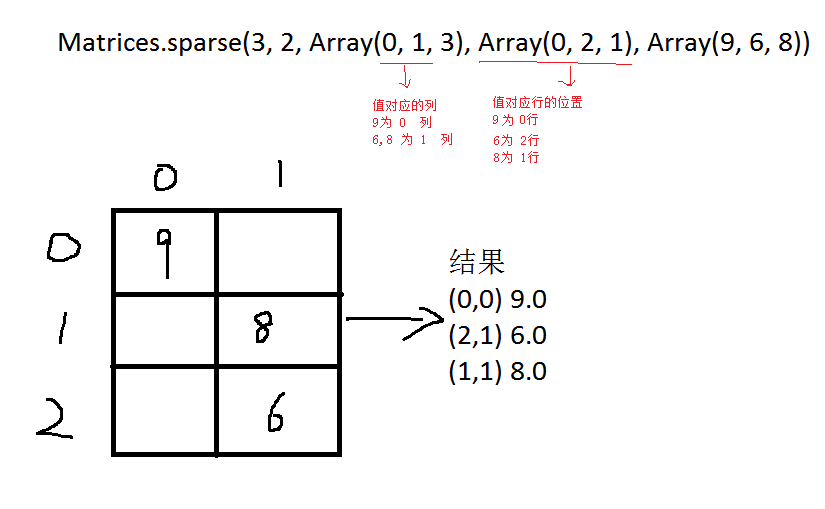
4.分散式矩陣(Distributed matrix)
分散式矩陣有Long類型的行列數據和Double類型值,存儲在一個或多個RDDs中
4.1. 行矩陣(RowMatrix)
行矩陣是一個沒有行索引的,以行為導向(row-oriented )的分散式矩陣,它的行只支持RDD格式,每一行都是一個本地向量。由於每一行都由一個局部向量表示,所以列的數量是由整數範圍所限制的,但是在實際操作中應該要小得多
scala> import org.apache.spark.mllib.linalg.Vector
scala> import org.apache.spark.mllib.linalg.distributed.RowMatrix
scala> import org.apache.spark.mllib.linalg.{Vector, Vectors}
4.1.1 生成DataFrame
scala> val df1 = Seq(
(1.0, 2.0, 3.0),
(1.1, 2.1, 3.1),
(1.2, 2.2, 3.2)).toDF("c1", "c2", "c3")
scala> df1.show
c1 c2 c3
1.0 2.0 3.0
1.1 2.1 3.1
1.2 2.2 3.2
4.1.2 DataFrame轉換成RDD[Vector]
scala> val rv1= df1.rdd.map {
x =>Vectors.dense(
x(0).toString().toDouble,
x(1).toString().toDouble,
x(2).toString().toDouble)
}
scala> rv1.collect()
4.1.3 創建行矩陣
scala> val mt1: RowMatrix = new RowMatrix(rv1)
scala> val m = mt1.numRows()
scala> val n = mt1.numCols()
查看:
scala> mt1.rows.collect()
或
scala>mt1.rows.map { x =>
(x(0).toDouble,
x(1).toDouble,
x(2).toDouble)
}.collect()
4.2 CoordinateMatrix坐標矩陣
CoordinateMatrix是一個分散式矩陣,每行數據格式為三元組(i: Long, j: Long, value: Double), i表示行索引,j表示列索引,value表示數值。只有當矩陣的兩個維度都很大且矩陣非常稀疏時,才應該使用坐標矩陣。可以通過RDD[MatrixEntry]實例來創建一個CoordinateMatrix。MatrixEntry包裝類型(Long, Long, Double)
scala> import org.apache.spark.mllib.linalg.distributed.CoordinateMatrix
scala> import org.apache.spark.mllib.linalg.distributed.MatrixEntry
4.2.1 生成df(行坐標,列坐標,值)
scala> val df = Seq(
(0, 0, 1.1), (0, 1, 1.2), (0, 2, 1.3),
(1, 0, 2.1), (1, 1, 2.2), (1, 2, 2.3),
(2, 0, 3.1), (2, 1, 3.2), (2, 2, 3.3)).toDF("row", "col", "value")
4.2.2 生成入口矩陣
scala> val m1 = df.rdd.map { x =>
val a = x(0).toString().toLong
val b = x(1).toString().toLong
val c = x(2).toString().toDouble
MatrixEntry(a, b, c)
}
scala> m1.collect()
4.2.3 生成坐標矩陣
scala> val m2 = new CoordinateMatrix(m1)
scala> m2.numRows()
scala> m2.numCols()
查看
scala> m2.entries.collect().take(10)


