
在面試中被問到這樣的題目,當時被問蒙了,後來查閱了一下相關資料搞懂了一些,記錄一下。 題目:有一堆的用戶消費數據,欄位為id、城市、性別、消費總額等,要求選取每個城市消費總額的Top N。面試官提示,可以用python,也可以用任何sql語言。 這裡記錄的是Oracle的做法。查看表的信息: sel ...
在面試中被問到這樣的題目,當時被問蒙了,後來查閱了一下相關資料搞懂了一些,記錄一下。
題目:有一堆的用戶消費數據,欄位為id、城市、性別、消費總額等,要求選取每個城市消費總額的Top N。面試官提示,可以用python,也可以用任何sql語言。
這裡記錄的是Oracle的做法。查看表的信息:
select * from table;

選取單個城市的消費總額 Top N
選取gz城市的消費總額Top 2:
select * from (select * from table where city='gz' order by amount desc) where rownum<3;

選取bj城市的消費總額Top 2:
select * from (select * from table where city='bj' order by amount desc) where rownum<3;
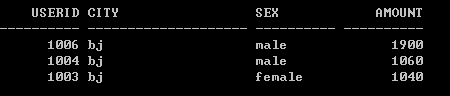
選取所有城市的消費總額 Top N
使用rank() over 函數,這個函數可以為每個元組定一個“排名”,所以可以作為一個屬性(rank() over as num)。
非rank over方法
select userid,city,amount from table a where( select count(*) from table b where a.city = b.city and b.amount > a.amount) <4 order by a.city,a.amount desc;
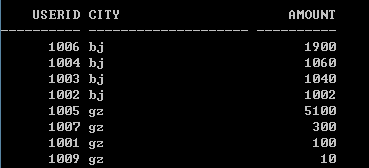
如果要最少的Top4 則改成 b.amount <a.amount 註意這裡的符號是 <,下一節rank() over方法對應的符號則是 <=。
如果是有消費總額重覆的情況呢?我們增加兩條來自廣州的土豪的記錄,這樣廣州的前3名的消費總額都是5100。為了驗證這種方法能不能處理總額重覆的情況,我們選取Top2:
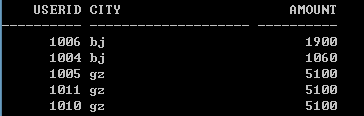
rank() over方法
rank() over(partition by 按什麼劃分 order by 按什麼排序)
我們按city劃分,按amount排序,所以我們通過以下語句獲取Top 4:
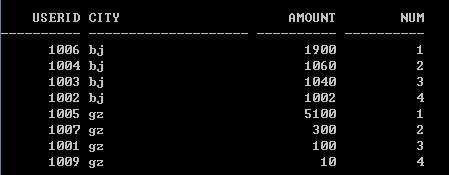
SQL> select * from (select userid, city, amount, rank() over(partition by city order by amount desc) as num from table) where num<=4;
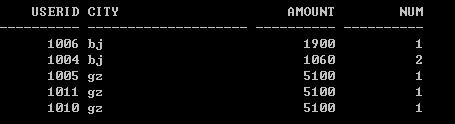
如果是有消費總額重覆的情況呢?
我們同樣通過rank() over函數來獲取Top 2看看:
select * from (select userid, city, amount, rank() over(partition by city order by amount desc) as num from table) where num<=2;
dense_rank() over
用rank() over獲取Top4,可以得到這樣的結果:
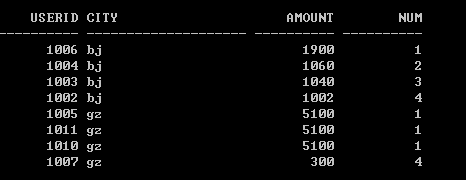
可以看到,此時前三名是併列第一,所以他們的排名都是1,而第四名的排名為4。若使用dense_rank() over(稠密的排名):
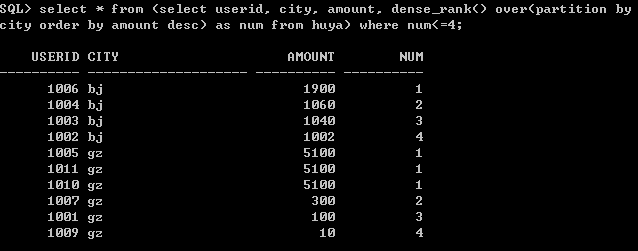
可以看到,前三名依然是併列第一,而第四名的排名為2,也就是說,他們的排名是稠密的(連續)。
一些錯誤做法
這樣只能返回全局的排名,不能在城市內排名
select userid,city,amount from table where city in (select distinct city from table) group by city,amount,userid order by amount desc;

select 的屬性要在group by中,也不能select *

sex不在group by中,會報錯

order by的屬性要在group by中,不然會報錯,而且order by要放在group by的後面‘’
python 做法
假設已經用pandas處理好數據了,現在得到一個list叫data
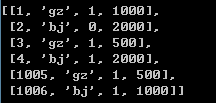
對於語句for x in data,x表示數據表中的一個元組(即一行記錄),x[0]為userid,x[1]為city,x[2]為sex,x[3]為amount。
我們可以通過如下的排序語句,可以排出'gz'和'bj'城市各自的Top2:
l = sorted([x for x in data if x[1] == 'gz'],key=lambda x:x[-1],reverse=True)[0:2]
# output: [[1, 'gz', 1, 1000], [3, 'gz', 1, 500]]
l = sorted([x for x in data if x[1] == 'bj'],key=lambda x:x[-1],reverse=True)[0:2]
# output: [[2, 'bj', 0, 2000], [4, 'bj', 1, 2000]]我們可以通過如下的排序語句,在每個城市內按消費數目排列:
d = sorted(sorted(data, key=lambda x:x[-1], reverse=True), key=lambda x:x[1])
# output:
# [[2, 'bj', 0, 2000],
# [4, 'bj', 1, 2000],
# [1006, 'bj', 1, 1000],
# [1, 'gz', 1, 1000],
# [3, 'gz', 1, 500],
# [1005, 'gz', 1, 500]]為了輸出每個城市的Top2,我們先要獲取城市列表(需要去重操作):
citys = list(set([x[1] for x in data]))
# output: ['gz', 'bj']
for city in citys:
print [x for x in d if x[1]==city][:2]
# output: [[1, 'gz', 1, 1000], [3, 'gz', 1, 500]]
# [[2, 'bj', 0, 2000], [4, 'bj', 1, 2000]]為了方便敘述,我們不妨設上述“Top2列表”為\(T\),按每個城市內按消費數目排列的列表為\(D\)
考慮併列的情況,其實就是檢查在列表\(D-T\)中是否存在元素\(\bar{x}\),其消費金額與列表\(T\)中任意一個元素\(x\)的消費金額相等的情況
我們容易看出,\(x\)有兩個特點:
- \(x\)的userid還未在T中出現
- \(x\)的消費金額與\(T\)中最後一個元素\(x_2\)的消費金額相等(因為\(D\)是遞減的)
故我們可以寫出這樣的語句:
citys = list(set([x[1] for x in data]))
for city in citys:
res = [x for x in d if x[1]==city][:2]
uids = [x[0] for x in res]
tied = [x for x in d if x[1]==city and x[-1]==res[-1][-1] and not x[0] in uids]
if tied: # 有可能不存在這樣的x,那麼tied為空
res.append(tied)
print res
# output:
# [[1, 'gz', 1, 1000], [3, 'gz', 1, 500], [[1005, 'gz', 1, 500]]]
# [[2, 'bj', 0, 2000], [4, 'bj', 1, 2000]]
