
概述 資料庫相對於其它存儲軟體一個核心的特征是它支持事務,所謂事務的ACID就是原子性,一致性,隔離性和持久性。其中原子性,一致性,持久性更多是關註單個事務本身,比如,原子性要求事務中的操作要麼都提交,要麼都不提交;一致性要求事務的操作必須滿足定義的約束,包括觸發器,外鍵約束等;持久性則要求如果事務 ...
概述
資料庫相對於其它存儲軟體一個核心的特征是它支持事務,所謂事務的ACID就是原子性,一致性,隔離性和持久性。其中原子性,一致性,持久性更多是關註單個事務本身,比如,原子性要求事務中的操作要麼都提交,要麼都不提交;一致性要求事務的操作必須滿足定義的約束,包括觸發器,外鍵約束等;持久性則要求如果事務成功提交了,無論發生什麼異常,包括進程crash,主機掉電等,都應該確保事務不會丟失。而隔離性,則關註的是多個事務之間的併發。
如果所有的事務都串列執行,相互不影響,不會有隔離的級別的問題。但是,串列無法充分發揮多核的優勢,因此需要併發執行多個事務,並且“儘量”做到併發執行的事務與串列執行等價。為什麼是“儘量”?是因為資料庫中實際上不只有一種隔離級別,可串列化,所以才有必要討論資料庫中的隔離級別。比如拿MySQL舉例,隔離級別包括,讀未提交,讀提交,可重覆讀,和串列化4種,其中可串列化是最嚴格的隔離級別,意味著事務之間產生衝突的概率最高。理論上,只有“可串列化”的事務序列才是“正確的”,但是,由於資料庫系統需要追求更好的性能,更高的系統吞吐,所以系統中會定義另外“比較弱”的隔離級別。每種“弱”的隔離級別定義,都會明確說明它會產生哪些“異常”,如果用戶能容忍這些“異常”,很好,那麼我們不用將資料庫設置為最嚴的併發控制模式。所以,簡單來說,通過隔離級別的設置,用戶可以在“異常”和資料庫性能之間做一個權衡。
資料庫中異常
本文討論的隔離級別主要源於論文A Critique of ANSI SQL Isolation Levels,論文中定義了一系列“異常”,並且說明瞭不同的隔離級別分別解決了哪些“異常”。說明下文中,w[n]表示事務n寫,r[n]表示事務n讀,a[n]表示事務n-abort,c[n]表示事務n-commit。A0,P1,P2,P3,A4,A5等異常命名編號均來源於論文。
1.臟寫
A0,dirty-write(WW),臟寫
訪問模式:w1[x], w2[x],c1,c2
兩個事務先後寫x,這種會導致w2事務覆蓋w1的寫。
2.臟讀
P1,dirty-read(WR),臟讀
訪問模式:w1[x], r2[x],a1,c2
事務2讀到的x值,而最終事務1 abort了,這個x值根本不應該存在。
P1是區分Read Uncommitted和Read Committed隔離級別
3.不可重覆讀
P2,Non-repeatable Read【Fuzzy Read】
訪問模式,r1[x],w2[x],w2[commit],r1[x]
事務r1兩次訪問x,返回的結果不一樣。比如x=10,
r1[x=10],w2(x=50),w2[commit],r1[x=50]
事務r1兩次讀取x,讀到了不同的值。
P2用於區分ReadCommitted和RepeatableRead隔離級別。
4.幻讀
P3,Phantom
異常:同一個事務,兩次讀返回的結果集不一樣,
這裡主要是說的幻讀,幻讀比不可重覆讀要求更嚴格,即事務內的任何一個查詢,都不應該受其他事務的更新操作影響(insert,update,delete),而出現結果不一致的現象。比如說,第一個查詢select... where x>1 返回了3條記錄(3,4,5);在這個時候,有另外的一個事務insert x=6;當再次查詢時,發現x>1返回了(3,4,5,6)4條記錄,這個就是幻讀現象的一種。
P3用於區別Repeatable Read和Serializable。
P1--P3是傳統的根據異常區分而定義的隔離級別,讀提交,可重覆讀,串列化。但這種分法描述的異常可能還不夠多和完整,特別是對於普遍廣泛流行的MVCC併發控制,於是論文中在標準隔離級別基礎上將“異常”定義地更豐富,並且詳細介紹了目前Snapshot-Isolation。
5.Lost Update(寫覆蓋)
A4, Lost Update
A4的訪問模式r1[x], w2[x], w2[commit], w1[x], w1[commit]
這種訪問模式下,w2的更新可能會丟失。因為w1可能基於一個比較old-x來做更新x的操作。
6.Read&Write Skew
A5, (Constraint Violation),考慮到兩個相關聯記錄x,y,滿足x+y=100,根據讀寫可以分為兩種
A5A, Read Skew
r1[x]...w2[x]...w2[y]...c2...r1[y]...(c1 or a1)
事務1讀取x後,事務2同時更新了x,y然後commit,那麼事務1再讀取y。
x=50, y=50
r1[x=50]...w2[x=20]...w2[y=80]...c2...r1[y=80]...(c1 or a1)
那麼對於事務1,x+y=130
A5B, Write Skew(讀後寫)
A5B: r1[x]...r2[y]...w1[y]...w2[x]...(c1 and c2 occur)
C(x,y)滿足x+y >= 0, x=10, y=0
r1[x=10,y=0],r2[x=10,y=0],w1[y=-10],w2[x=0],w1(commit),w2(commit)
最終結果是x=0,y=-10,導致不滿足x+y>=0的約束
資料庫的隔離級別
我們談隔離級別,實際上是在談併發控制。通常資料庫實現併發控制主要有兩類,基於鎖的悲觀併發控制(2PL)和樂觀併發控制(OCC)。前者在操作數據的過程中加鎖,直到事務提交時才釋放。後者在事務讀寫的過程中不加鎖,而是在提交的時候通過對比操作的readset和writeset來判斷事務是否存在衝突,來決定是否提交。原始的基於鎖的悲觀併發控制,讀和寫都加鎖,併發度比較低,因此目前主流的資料庫系統都引入了多版本併發控制機制(MVCC),所謂MVCC,簡單來說,通過冗餘歷史版本,達到讀不加鎖,讀寫不互斥的目的,這種讀就是快照讀,區別於加鎖模式的當前讀。這一改進大大提交的整個資料庫系統的併發度,當然,如果要實現可串列化隔離級別,需要做額外的工作來保證。下麵簡單討論下不同隔離級別下,分別有哪些異常,以及主流資料庫的實現方式。
1.READ UNCOMMITTED
讀寫都不加鎖,資料庫完全不做併發控制,基本上沒什麼實用價值。
2.READ COMMITTED
寫記錄加鎖,讀基於快照讀,並且事務中每個語句有獨立的快照,確保讀到最新的事務提交,解決了臟讀的問題,但不解決可重覆讀問題,當然也無法避免幻讀,ReadSkew&WriteSkew等問題。
3.REPEATABLE READ
提到REPEATABLE READ隔離級別,不得不提到SNAPSHOT,一般主流資料庫裡面都不提SNAPSHOT隔離級別,但是實際實現的時候又都是基於SNAPSHOT來做的,但這裡又有一些細微的區別。對於MySQL(InnoDB)而言,讀的時候仍然是快照讀,相對於READ-COMMITED隔離級別,是一個事務一個快照,確保可重覆讀,也不存在幻讀問題;但是寫的時候,採用的當前讀,也就是更新的時候,不再考慮快照,而是基於最新的版本來更新,這樣就可能會造成LostUpdate問題。當然,解決辦法也很簡單,事務內的讀也採用當前讀,這樣也就避免了LostUpdate問題。這裡舉個例子:假設t是一張庫存表,pk='iphone'是主鍵,賣出一部iphone就減去一個庫存,count=count-1;假設有兩種寫法
case1: begin: select var = count from t where pk = 'iphone'; var = var - 1; update count = var from t where pk = 'iphone'; commit; case2: begin: update count = count - 1 from t where pk = 'iphone'; commit;
對於case1,就會發生LostUpdate,試想下如果兩個同類型的事務併發,快照讀讀到的是old count,就可能出現覆蓋寫的問題,導致庫存少減了。
對於case2,則不會有LostUpdate問題,update場景下,讀都是當前讀,在RR隔離級別下,會加寫鎖,確保能讀到最新的count。
對於MySQL(RocksDB)而言,讀一樣是基於同一個快照;寫的時候,仍然是基於快照讀(這個與RocksDB的LSM存儲結構有關,只能基於一個快照去讀取多版本數據),那麼要更新記錄時候,會判斷記錄中的版本是否比事務的快照版本新(ValidateSnapshot),如果是,說明在事務獲取快照後,有其它事務執行了更新操作,這個時候事務會回滾,也就不會發生LostUpdate問題。PG也是採用類似的機制,與MySQL(InnoDB)的本質區別在於,寫的時候,是基於快照讀去寫,而還是基於當前讀去寫。最終的效果是,MySQL(InnoDB)在RR隔離級別下,也會存在LostUpdate問題,同時因為快照讀和當前讀混用(select, select ... for update),實際上嚴格來說,也就沒有解決幻讀和可重覆讀的問題。Oracle沒有實現RR隔離級別,只提供RC和SERIALIZABLE隔離級別。無論是MySQL(InnoDB,RocksDB),PG都沒有解決WriteSkew問題。
4.SERIALIZABLE
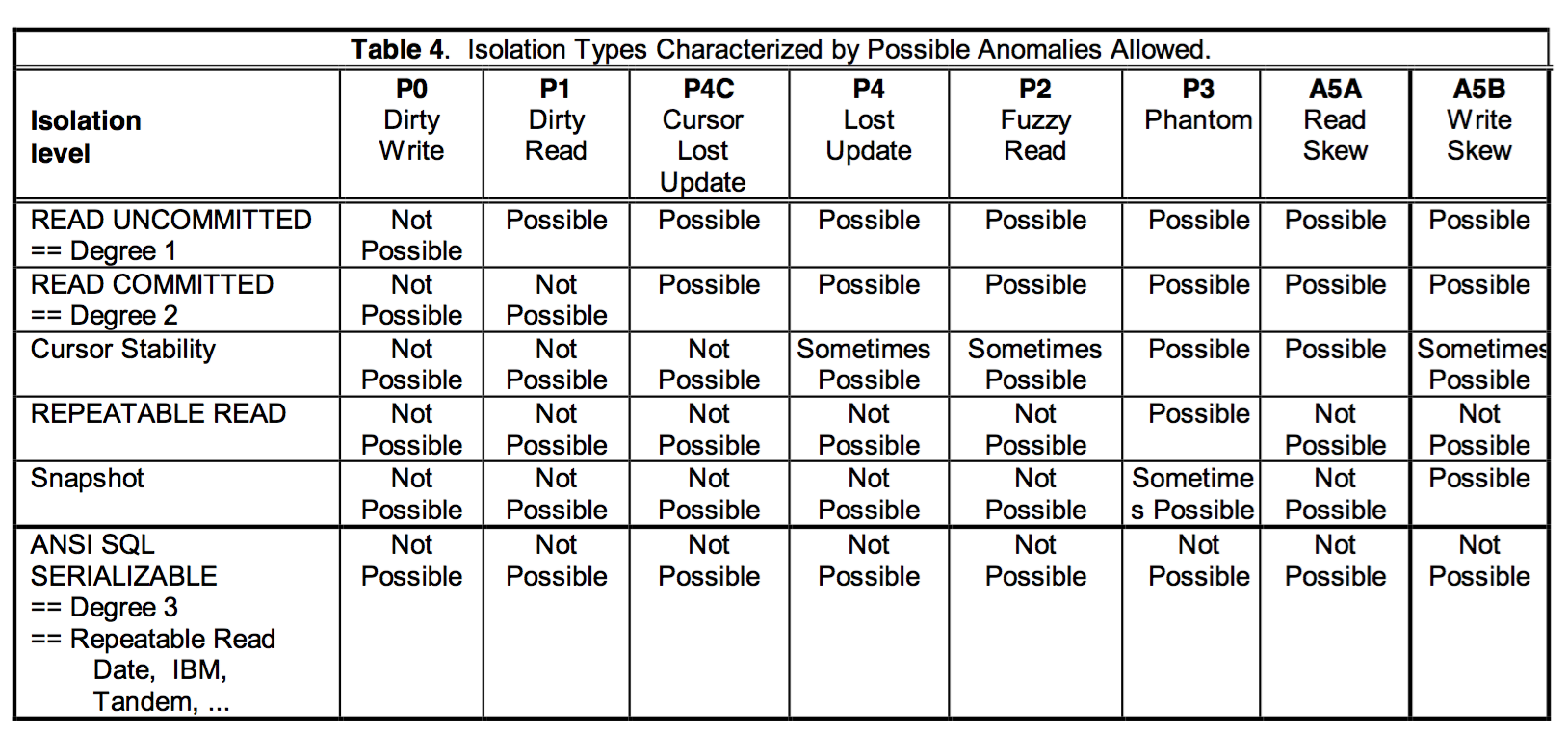
最嚴格的隔離級別,自然是沒有“異常”的,我們前面也說到,為了提供系統的併發度,才選擇通過降低資料庫的隔離級別,但必需要容忍部分“異常”。串列化解決了臟讀/寫,丟失更新,幻讀,不可重覆讀,以及ReadSkew&WriteSkew等問題。MySQL(Innodb)通過將所有所有讀都變為當前讀,並結合(GAP,Next-Key,InsertIntention)lock來實現串列化隔離,PG則是事務提交時,根據readset和writeset檢查是否與其它事務之間有讀寫依賴成環,最終確定事務能否提交。MySQL(Rocksdb)只支持RC和RR,不支持串列化隔離級別。下圖來源於論文,整理了不同隔離級別對應的異常。
總結
本文結合論文和主流的資料庫系統討論了資料庫的隔離級別。一般來說,生產環境中設置ReadCommit的居多,文章中也提到了,在讀提交隔離級別下,會存在有不可重覆讀,幻讀以及Read/Write Skew等問題。說明,生產環境是可以“容忍”這些“異常”的。當然,這不能說明隔離級別不重要,如果某些業務場景,不能容忍“異常”,就比如我文章中提到的減庫存的例子,如果業務代碼寫法不正確,就可能導致問題。總之,我們需要在系統的併發度和隔離級別做一個權衡,確保業務正確的前提下,得到最好的性能。
參考文檔
A Critique of ANSI SQL Isolation Levels

