
超詳細官方教程解析 https://blog.csdn.net/fly_yr/article/details/51540269 實戰過程: 【1】創建Scrapy項目 scrapy startproject TestDemo 若進入到相應的文件目錄下,在地址欄輸入cmd進入命令行界面,輸入以上命令, ...
超詳細官方教程解析
https://blog.csdn.net/fly_yr/article/details/51540269
實戰過程:
- 創建一個Scrapy項目
- 定義提取的Item
- 編寫爬取網站的 spider 並提取 Item
- 編寫 Item Pipeline 來存儲提取到的Item(即數據)
【1】創建Scrapy項目
scrapy startproject TestDemo
若進入到相應的文件目錄下,在地址欄輸入cmd進入命令行界面,輸入以上命令,則會在相應的文件目錄下建立一個項目

創建spider.py命令:scrapy genspider -t basic 名字 網址
也可以手動創建
運行爬蟲時,在項目所在目錄的地址欄cmd,進入,輸入 scrapy crawl 爬蟲名字;
否則可能會提示沒找到該命令
其他相關命令

【2】定義Item容器

添加欄位位置
先建模 //左是名字 右邊是 占位符

【3】編寫爬蟲:

實現爬蟲的python文件應該在spiders文件夾下

#def parse是回調函數,從Downloader返回response後,接受response而執行的方法;分別裁剪xx作為文件名,將網頁的<body>內容保存至兩個文件;
【3-1】爬“取”: ---------利用Xpath


XPath舉例:

【3-2】重寫spider的分析方法 【原方法是為了保存,驗證用】

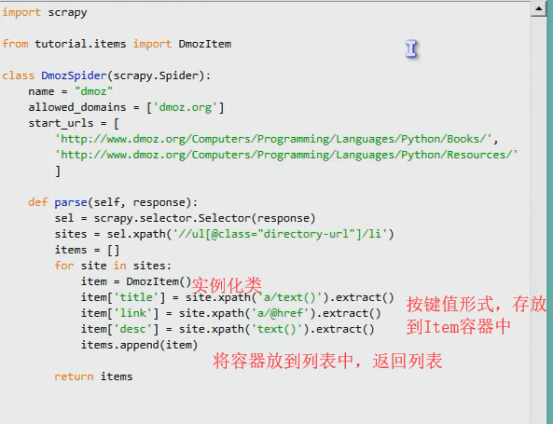
【4】將數據存放到Item容器中
【5】導出保存
scrapy crawl domz -o items.json -t json
#-o 指導出 後跟文件名字【需要尾碼】
#-t 表示導出的格式,此處用json
#此處代碼意思是,運行爬蟲domz,並以json格式導出保存為items.json
實戰中註意點:
1. 剛開始入門的時候,要爬取能爬的網站。。。有些是有反爬蟲機制的,不然還會以為是代碼錯了導致沒爬到數據
2. xpath() 中:
比如爬<html><head><title>xxx 的內容,
如果已經sites = sel.xpath('/html/head/title')
接下來用site = sites.xpath('text()').extract() 即可獲取Selector對象的列表字元串化後的unicode字元串
而不是site = sites.xpath('/text()').extract() 或者 site = sites.xpath('title/text()').extract()
3.定義Item容器 中, 要和存放容器時使用的一致,不可無中生有



