
一. 基於度量的程式結構分析 1. 第一次作業 這次作業是我上手的第一個java程式,使用了4個類來實現功能。多項式採用兩個arraylist來存,繫數和冪指數一一對應。 四個類分別為 Poly類,代表表達式; PolyDiff類,代表求導運算; PolyParse類,封裝了格式檢查,encodin ...
一. 基於度量的程式結構分析
1. 第一次作業
這次作業是我上手的第一個java程式,使用了4個類來實現功能。多項式採用兩個arraylist來存,繫數和冪指數一一對應。
1 private ArrayList<BigInteger> coefs; 2 private ArrayList<BigInteger> degrees;
四個類分別為
- Poly類,代表表達式;
- PolyDiff類,代表求導運算;
- PolyParse類,封裝了格式檢查,encoding(輸入的多項式轉為內部存儲形式),優化,decoing(內部存儲形式轉為輸出的多項式)方法;
- PolyDiffTest類,入口類
整個程式既有面向對象的味道(封裝),但不那麼純,也有面向過程的寫法。
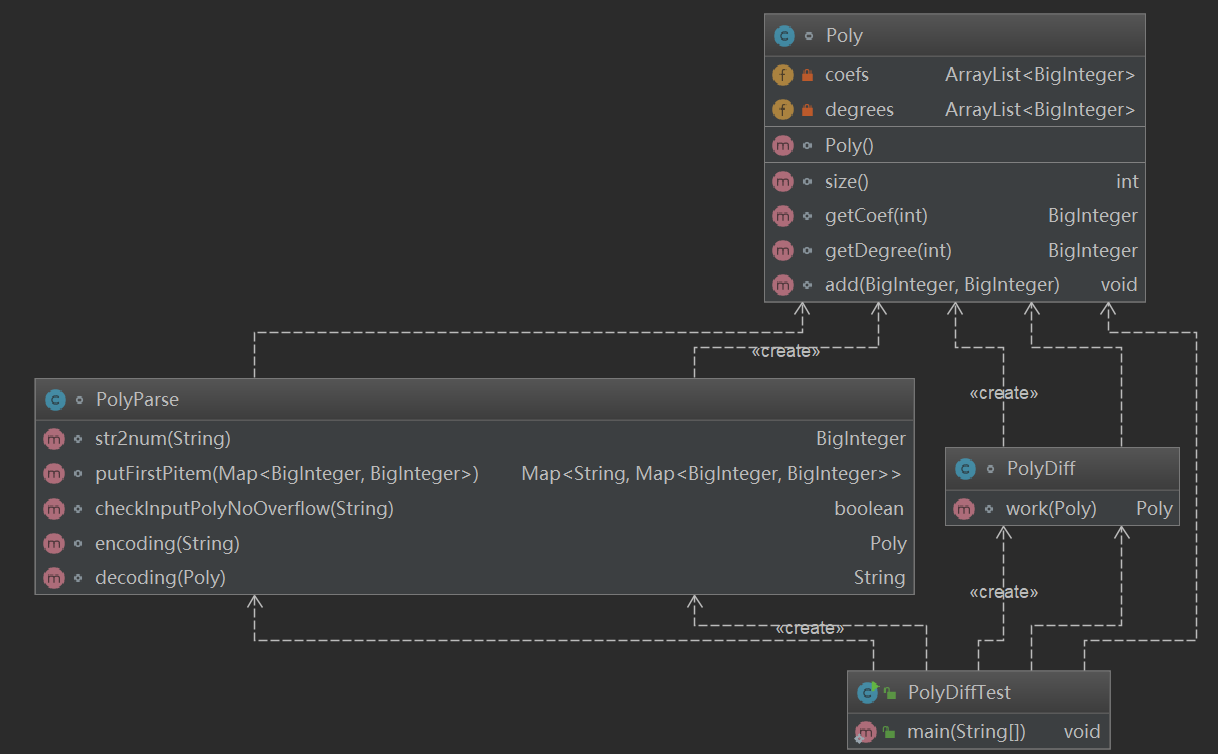
類圖如下:
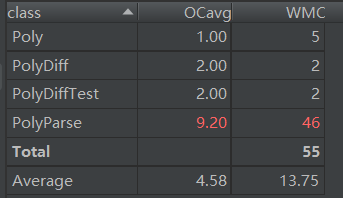
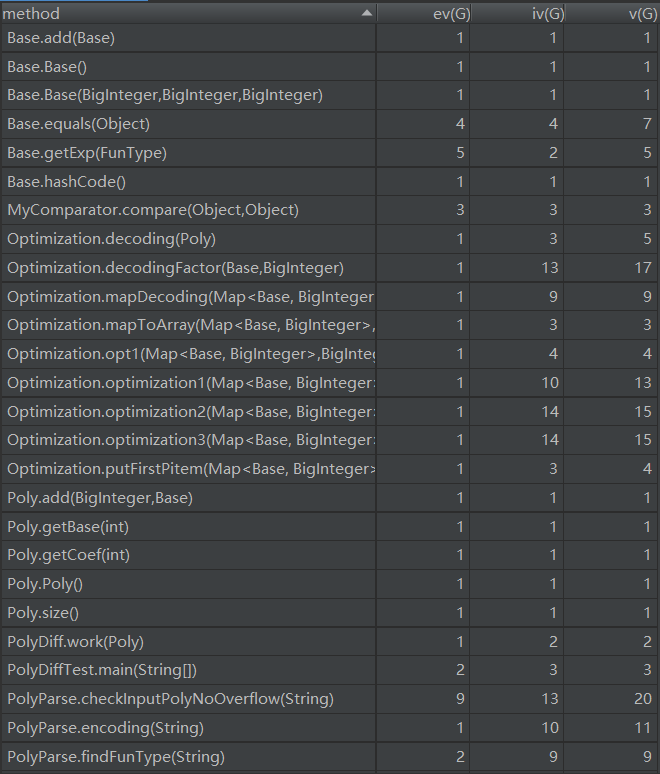
類複雜度分析如下:

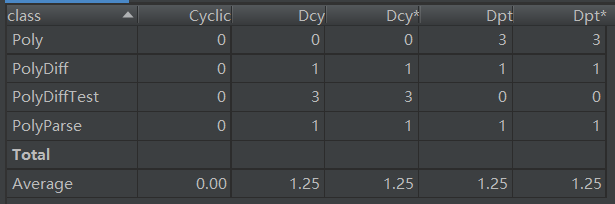
優缺點分析:
這裡PolyParse類的代碼尤其多,在整個設計中,PolyParse類是主類,完成了大多數功能,其他類是輔助類。這樣的寫法犯了面向對象的一個大忌:類失衡。究其原因,還是受到了面向過程思想的影響。其次可以直接用Hashmap而不是arraylist來存表達式。
對於第二次作業而言,本次作業的擴展性還行,給出了整個求導的框架。
2. 第二次作業
本次作業最重要的變化是加入了三角函數。為了使用上次作業的架構,我只改變了表達式的存儲形式。對於求導,採用的方式還是和上次作業一樣,直接帶公式。關鍵是項的表示形式。
以 x, sin(x), cos(x) 做為基函數,對於任何項 kxasin(x)bcos(x)c 都可以表示為 (k,(a,b,c))(k,(a,b,c)),
採用複合函數求導公式 (uvw)' = (uvw)′=u′vw+uv′w+uvw′ 得到的結果為3個項,具體形式可以拿公式直接得出來。
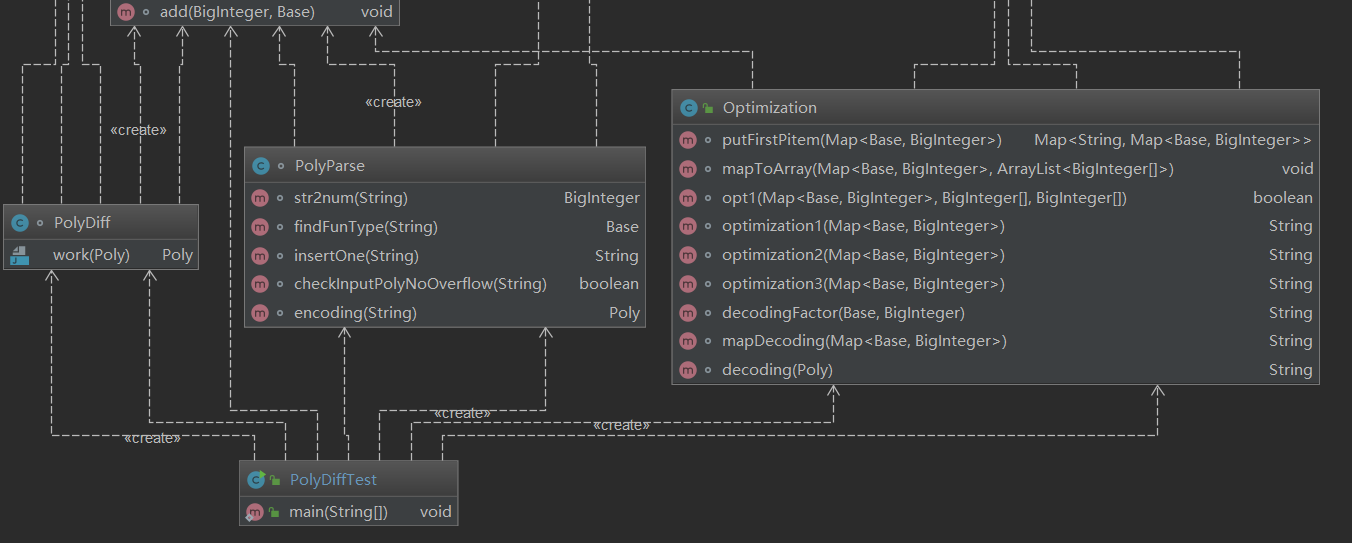
類圖如下:

類複雜度分析如下:

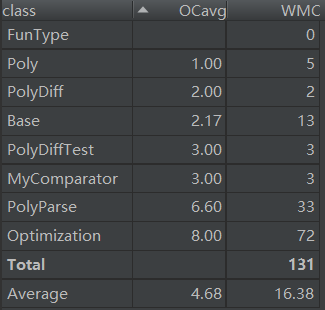
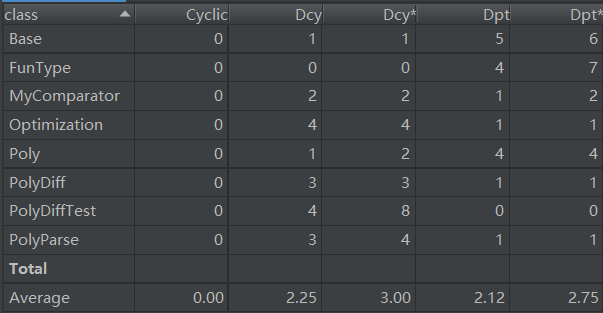
優缺點分析:
這裡優化的類裡面的代碼尤其多,為了保證每個方法的行數小於限制行數,只能強行將優化函數拆成3個不同功能的優化,但裡面有很多冗餘的代碼。
對於第三次作業而言,本次作業不具任何的擴展性,這種求導的框架走到了盡頭。
3. 第三次作業
本次作業加入了嵌套因數和表達式因數,由於前兩次作業不能擴展以及之前寫過編譯器的經驗,這一次我是推倒重來,從頭開始寫了小型編譯器。
求導過程可看作是一個翻譯過程:源語言:原表達式,目標語言:求導後的表達式。指導書上對於item的要求看起來複雜,但拆成一個個小單元後,很容易就能寫出item的文法,之後採用遞歸下降分析法,一次掃描,同時完成了格式檢查和求導的工作。
我d得這次作業最精彩的是我的求導都是形式求導,實質是字元串的拼接。
比如a=b*c 有了b和c本身以及b和c求導後的表達式b',c'的string形式,套公式(字元串拼接)就可以得到c'=b'c+bc'的string形式。整個過程非常簡單。不論是乘法,加法還是嵌套,都可以用這種方式解決。
類圖如下:
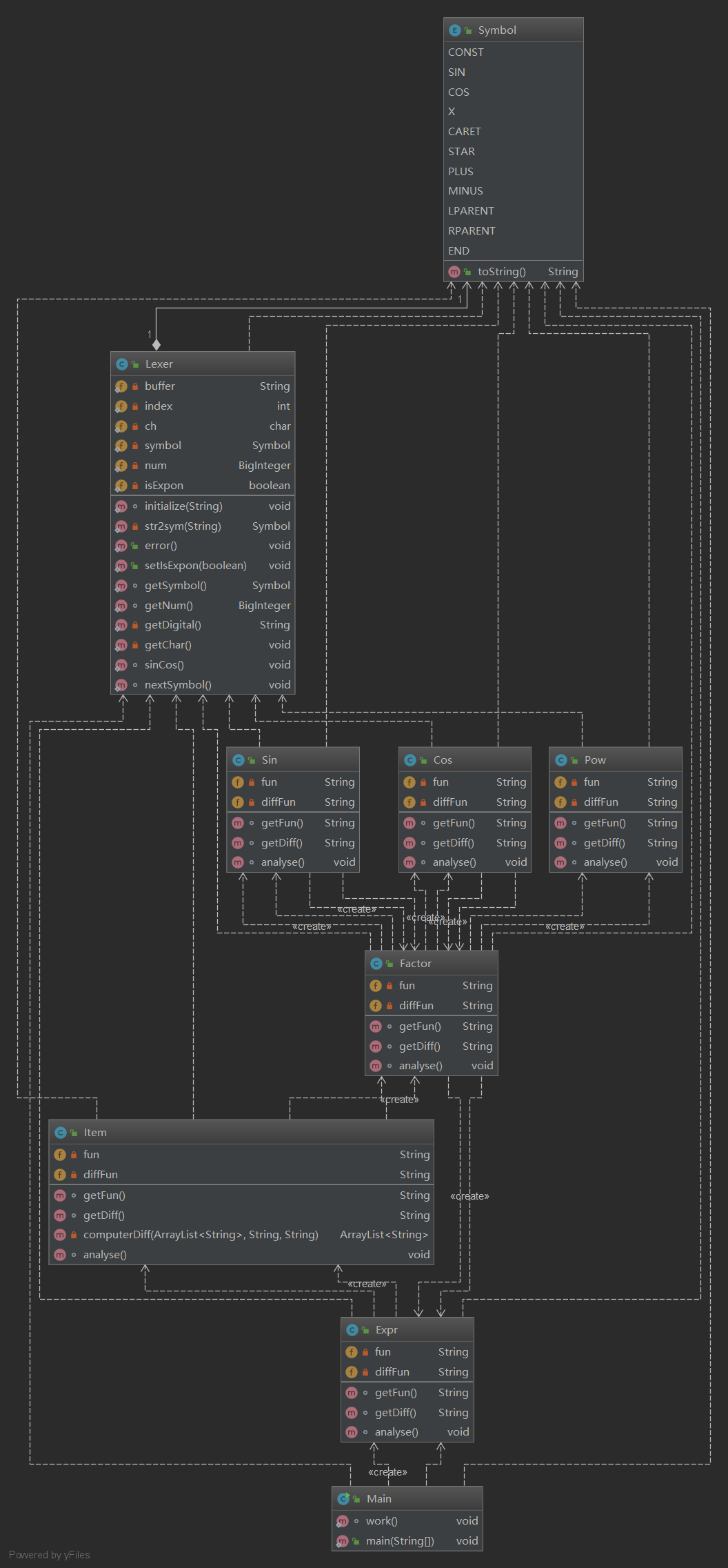
類複雜度分析如下:
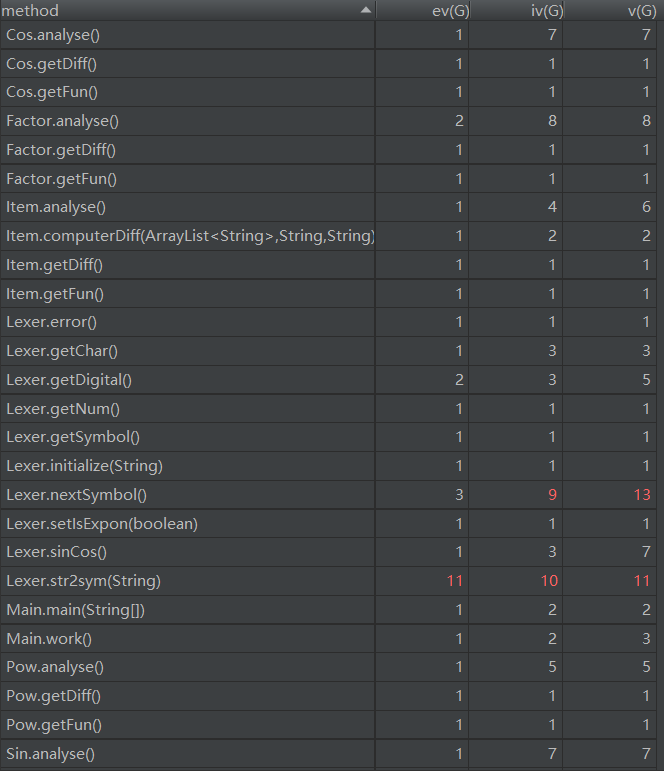
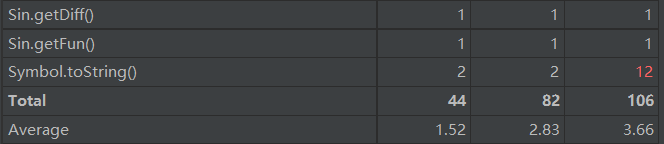


優缺點分析:
採用了編譯器的經典架構:Expr,Item,Factor,Lexer,Symbol,Pow,Sin,Cos類的劃分明確,職責清晰。類複雜度分析圖中標紅的地方是由於使用了大量的if,else或者switch,但這個也必須用,不知道有沒有更好的對於if,else的改寫方法。
還是只用了封裝,繼承,多態,介面一個都沒用上。註意之後的重構部分會給出一些修改方法。
二. bug分析
第一次作業:
較為簡單,暫無bug發現
第二次作業:
這次作業的bug出在了優化部分,可謂是畫蛇添足。
測試用例:3*x + sin(x)^5*cos(x) - sin (x)^3*cos(x) - sin(x)*cos(x)^5 + sin(x)*cos(x)^3
錯誤輸出:7*sin(x)^2*cos(x)^2-4+7*cos(x)^2
特征:向map中添加元素的時候,沒有先調用get()來得到原來的key之後再累加上去,而是直接調用put()方法覆蓋了原來的key。導致程式中如果有一個以上sinx^2+cosx^2=1或1-sinx^2=cosx^2或1-cosx^2=sinx^2的合併時出現錯誤。
問題所在的類和方法:Optimization類的opt1,optimization1,optimization2方法。
bug位置與設計結構之間的相關性:優化類的結構一開始每個方法寫的很長,超出了最大行數的限制,之後強行拆成了幾個方法,導致方法的功能有些混亂,在測試時沒有找到bug。
分類樹角度分析程式在設計上的問題:分類樹是一種使用樹狀結構來構造測試用例的方法,避免了測試用例的冗餘。我在本次作業中構建的測試用例只針對了正確性,對於能夠優化的用例,我只構造了幾個,沒有完全覆蓋優化的函數。
第三次作業:
暫無bug發現,為了防止錯誤出現,沒有做過多優化。
三. 測試方法
雖然我們沒有互測,但自動測試可以顯著提高測試效率,很有必要實現對拍程式。
1. 構建測試用例
對於第三次作業,情況較為複雜,採用隨機生成大量用例的方法易生成大量類似測試用例,不能保證全覆蓋。我依照指導書精心設計了30多個用例,保證了測試的全覆蓋。
2. 測試方法
稍微修改java程式的Main方法,使其從文件讀表達式,將結果輸出到文件。使用python的sympy庫編寫對拍程式,符號求導,代入隨機數運算後比對,實現了正確格式用例的測試。對於Wrong Format的測試,直接看java程式是否輸出WF。
四. Applying Creational Pattern
第三次作業依舊沒有使用繼承和介面,但每個類的形式都是一樣的。
1 private String fun = ""; 2 private String diffFun = ""; 3 4 String getFun() { 5 return fun; 6 } 7 8 String getDiff() { 9 return diffFun; 10 } 11 12 void analyse() { 13 ...... 14 }
重構:
新建一個父類對象Expression包含fun和diffFun變數成員,getFun()和getDiff()函數成員。由於每個子類的analyse()行為不一樣,無法使用父類的getFun()和getDiff()完成功能,因此直接將analyse定義為一個介面。每一個子類需要繼承父類Expression並且實現介面analyse。
我的設計思路中也體現出Factory Pattern的思想。因為語法分析的結果實質是構建了一個語法樹,每一個父節點都會創建兩個子節點,並且調用子節點的getFun()和getDiff()函數,整個過程是一個遞歸過程,最終從樹的根節點上拿到結果。


