
前言 Linux上提供了兩款工具用於查找文件,一款是locate,另一款是find。 locate的特點是根據已生成的資料庫查找,速度較快,但是查找的是快照數據,不准確。 因此在日常使用中,為了準確性,使用find的情況比較常見。並且find可自定義查找條件,十分靈活。 locate Linux上有 ...
前言
Linux上提供了兩款工具用於查找文件,一款是locate,另一款是find。
locate的特點是根據已生成的資料庫查找,速度較快,但是查找的是快照數據,不准確。
因此在日常使用中,為了準確性,使用find的情況比較常見。並且find可自定義查找條件,十分靈活。
locate
Linux上有一個RPM包,名為mlocate,它是locate/updatedb的一種實現。
mlocate前面的m代表的意思是merging,它表示updatedb會重覆使用已存在的資料庫,從而避免讀取整個文件系統,這樣就加快了updatedb的速度。
mlocate包中主要有2個命令,一個是locate,另一個是updatedb。
updatedb用於檢索Linux的文件系統並生成/更新資料庫文件,該資料庫記錄了系統上每個文件的位置。
它會結合crontab每日更新,相關的文件是:/etc/cron.daily/mlocate。
locate根據用戶所輸入的關鍵詞(pattern)讀取updatedb所維護的資料庫,並將結果輸出在STDOUT上。
locate [OPTION]... PATTERN...
如果沒有使用--regex正則選項的話,那麼PATTERN可以包含globbing字元。
如果PATTERN沒有包含globbing字元的話,那麼locate預設會在PATTERN前後加上“*”,即“*PATTERN*”。
看一個簡單的示例。該命令的輸出很多,我做了剔除操作。
[root@C7 ~]# locate passwd /etc/passwd /etc/passwd- /etc/security/opasswd /usr/share/doc/passwd-0.79/AUTHORS /usr/share/doc/passwd-0.79/COPYING
可以看到,locate的查找機制,並不是精確查找passwd這個文件名,而是通過前文所說的“*PATTERN*”機制實現了模糊查找。
並且locate所查找的是整個路徑,而不僅僅是文件名。
如果希望locate只根據基名(basename)來查找的話,則使用-b選項。
[root@C7 ~]# locate passwd | wc -l 147 [root@C7 ~]# locate -b passwd | wc -l 143
pattern可以有多個。多個pattern之間是或關係,只要滿足某一個,就將其顯示出來。
# locate PATTERN1 PATTERN2 PATTERN3
[root@C7 ~]# locate passwd | wc -l 147 [root@C7 ~]# locate passwd vim | wc -l 1863 [root@C7 ~]# locate passwd vim shadow | wc -l 1945
如果希望查找的文件路徑滿足所有的pattern,則使用-A選項。
[root@C7 ~]# locate -A passwd vim shadow | wc -l 0
-c選項可用於統計相關pattern的條目數。
[root@C7 ~]# locate passwd | wc -l 147 [root@C7 ~]# locate -c passwd 147
關於locate,瞭解到這裡即可。
find
推薦閱讀駿馬金龍的兩篇博文,難度比較大,適合深入瞭解。
本文則比較適合日常使用以及新手入門。
find是一款文件實時查找工具。它的語法如下。
find [-H] [-L] [-P] [-D debugopts] [-Olevel] [path...] [expression]
語法比較複雜,我們來簡化一下。
-H、-L和-P:用於決定find是如何對待字元鏈接文件。預設find採取-P選項,不追蹤字元鏈接文件。
-D debugoptions:這個是find的調試模式,當我們執行find後的命令輸出,與我們所期望的不同時,使用該選項。
-Olevel:啟用查詢優化(query optimization)。
上述三種選項,新手都可以忽略,保持其預設即可。簡化後的結果為。
find [-H] [-L] [-P] [-D debugopts] [-Olevel] [path...] [expression]
path:表示find查找文件的搜索目錄。find只會在給出的目錄下查找。可以有多個。
expression:表達式,這個是重點,下文詳述。
表達式(expression)
[options...] [tests...] [actions...]
find查找文件的機制,主要是根據表達式的評估值來決定的。表達式會自左而右進行評估求值。只有當最終評估值為true的時候,才會輸出文件完整路徑(預設action)。
表達式由三部分構成:選項(option)、測試(test)和動作(action)。
選項(option)
所有的選項,總是會返回true。
選項所影響範圍是全局的,而不僅僅是找到的某些特定文件。
-daystart:隻影響這些測試(-amin、-atime、-cmin、-ctime、-mmin和-mtime),在測量時間的時候,從今天的起始開始計算,而不是24小時之前。
-maxdepth levels:最大深度。0表示只查找目錄自身,1表示最多至一級子目錄,以此類推。
[root@C7 ~]# find /etc/ -maxdepth 0 /etc/ [root@C7 ~]# find /etc/ -maxdepth 1 /etc/ /etc/fstab ... /etc/cupshelpers /etc/pinforc
-mindepth levels:最小深度。1表示從1級子文件開始處理(即不處理目錄自身),以此類推。
測試(test)
測試,其實就是查找的條件,可以根據文件名、路徑名、大小、類型、所有權和許可權等條件來查找。
創建示例文件層級結構。
[root@C7 ~]# tree -F /tmp/test_find/ /tmp/test_find/ ├── 1.log ├── 2.log ├── 3.log ├── 4.log ├── 5.log ├── a.txt ├── b.txt ├── c.txt ├── dir1/ │ └── test.sh ├── dir2/ │ └── test.xlsx ├── dir3/ │ └── work.doc ├── empty_dir/ └── zwl.log 4 directories, 12 files
根據名稱查找
-name "PATTERN":根據文件名來查找文件,pattern支持globbing字元。
[root@C7 ~]# find /tmp/test_find/ -name "*.log" /tmp/test_find/1.log /tmp/test_find/2.log /tmp/test_find/3.log /tmp/test_find/4.log /tmp/test_find/5.log /tmp/test_find/zwl.log
註意,find的查找,是根據文件名的精確查找,而不是locate的模糊查找。例如:
[root@C7 ~]# find /tmp/test_find/ -name "zwl"
這個實例,是無法找出“zwl.log”文件的。
-iname "PATTERN":類似-name,區別在於該選項是忽略字母大小寫。
[root@C7 ~]# touch /tmp/test_find/{alongdidi,ALongDiDi,ALONGDIDI}.log [root@C7 ~]# find /tmp/test_find/ -name "alongdidi.log" /tmp/test_find/alongdidi.log [root@C7 ~]# find /tmp/test_find/ -iname "alongdidi.log" /tmp/test_find/alongdidi.log /tmp/test_find/ALongDiDi.log /tmp/test_find/ALONGDIDI.log
-name和-iname都是基於文件的名稱(基名,basename)來查找,而不是像locate那樣可以基於整個路徑名。想實現的話,可以通過-path。
-path "PATTERN"
[root@C7 ~]# find /tmp/test_find/ -path "*test*/dir*/test*" /tmp/test_find/dir1/test.sh /tmp/test_find/dir2/test.xlsx
匹配整個路徑的時候,還可以基於正則表達式。
-regex "PATTERN":基於正則匹配完整路徑。
-iregex "PATTERN":等同於-regex,但是忽略字母大小寫。
-regextype type:預設支持Emacs正則,想調整正則類型的話,通過該選項。
一般我們基於名稱匹配的時候,常用的是基於文件的名稱,而不會基於整個路徑名稱!
根據文件所有權查找
-user NAME:根據文件的所有者查找,可以是username,也可以是UID。
-group NAME:根據文件的所有組查找,可以是groupname,也可以是GID。
“/tmp/test_find/”目錄下的所有文件的所有者和所有組都是root,我們有意修改幾個。
[root@C7 ~]# chown zwl:zwl /tmp/test_find/{alongdidi,ALongDiDi,ALONGDIDI}.log [root@C7 ~]# find /tmp/test_find/ -user zwl -group zwl -ls 17662805 0 -rw-r--r-- 1 zwl zwl 0 Mar 14 17:21 /tmp/test_find/alongdidi.log 17662807 0 -rw-r--r-- 1 zwl zwl 0 Mar 14 17:21 /tmp/test_find/ALongDiDi.log 17662808 0 -rw-r--r-- 1 zwl zwl 0 Mar 14 17:21 /tmp/test_find/ALONGDIDI.log [root@C7 ~]# find /tmp/test_find/ -user 1000 -group 1000 -ls 17662805 0 -rw-r--r-- 1 zwl zwl 0 Mar 14 17:21 /tmp/test_find/alongdidi.log 17662807 0 -rw-r--r-- 1 zwl zwl 0 Mar 14 17:21 /tmp/test_find/ALongDiDi.log 17662808 0 -rw-r--r-- 1 zwl zwl 0 Mar 14 17:21 /tmp/test_find/ALONGDIDI.log
命令結尾的“-ls”是動作的一種,輸出類似於“ls -l”。
一般都是通過用戶/組的名稱來查找,如果用戶/組被刪除了,那麼就只能通過UID/GID了。
[root@C7 ~]# chown haimianbb:haimianbb /tmp/test_find/{a,b,c}.txt [root@C7 ~]# find /tmp/test_find/ -user haimianbb -group haimianbb -ls 17662775 0 -rw-r--r-- 1 haimianbb haimianbb 0 Mar 14 17:06 /tmp/test_find/a.txt 17662778 0 -rw-r--r-- 1 haimianbb haimianbb 0 Mar 14 17:06 /tmp/test_find/b.txt 17662793 0 -rw-r--r-- 1 haimianbb haimianbb 0 Mar 14 17:06 /tmp/test_find/c.txt [root@C7 ~]# userdel -r haimianbb [root@C7 ~]# find /tmp/test_find/ -user haimianbb -group haimianbb -ls find: ‘haimianbb’ is not the name of a known user [root@C7 ~]# find /tmp/test_find/ -user 1004 -group 1005 -ls 17662775 0 -rw-r--r-- 1 1004 1005 0 Mar 14 17:06 /tmp/test_find/a.txt 17662778 0 -rw-r--r-- 1 1004 1005 0 Mar 14 17:06 /tmp/test_find/b.txt 17662793 0 -rw-r--r-- 1 1004 1005 0 Mar 14 17:06 /tmp/test_find/c.txt
或者通過-nouser和-nogroup也可以查找得到。
-nouser:查找沒有所有者的文件。
-nogroup:查找沒有所有組的文件。
[root@C7 ~]# find /tmp/test_find/ -nouser -nogroup -ls 17662775 0 -rw-r--r-- 1 1004 1005 0 Mar 14 17:06 /tmp/test_find/a.txt 17662778 0 -rw-r--r-- 1 1004 1005 0 Mar 14 17:06 /tmp/test_find/b.txt 17662793 0 -rw-r--r-- 1 1004 1005 0 Mar 14 17:06 /tmp/test_find/c.txt
根據文件的類型查找
-type TYPE:
f:普通文件;
d:目錄文件;
l:字元鏈接文件;
b:塊設備文件;
c:字元設備文件;
p:管道文件;
s:套接字文件。
[root@C7 ~]# find /tmp/test_find/ -type f -name "*.txt" /tmp/test_find/a.txt /tmp/test_find/b.txt /tmp/test_find/c.txt [root@C7 ~]# find /tmp/test_find/ -type d /tmp/test_find/ /tmp/test_find/dir1 /tmp/test_find/dir2 /tmp/test_find/dir3 /tmp/test_find/empty_dir
根據文件的大小查找
-size [+|-]#UNIT:“#”表示具體的數值大小,是一個正整數。
可以帶上正負符號,也可以不帶,其含義各不相同。正號表示大於,負號表示小於。
UNIT表示size的單位。單位:k=1024B(註意,這裡是小寫字母的k),M=1024KB,G=1024GB。
首先我們先使用dd命令創造一些指定大小的測試文件。
# dd if=/tmp/messages of=/tmp/test_find/size1.txt bs=1K count=10 # dd if=/tmp/messages of=/tmp/test_find/size2.txt bs=1K count=20 # dd if=/tmp/messages of=/tmp/test_find/size3.txt bs=1K count=30
[root@C7 ~]# ls -lh /tmp/test_find/size*.txt -rw-r--r-- 1 root root 10K Mar 15 14:15 /tmp/test_find/size1.txt -rw-r--r-- 1 root root 20K Mar 15 14:16 /tmp/test_find/size2.txt -rw-r--r-- 1 root root 30K Mar 15 14:16 /tmp/test_find/size3.txt
簡單測試。
[root@C7 ~]# find /tmp/test_find/ -size 20k -name "size*.txt" -ls 17662782 20 -rw-r--r-- 1 root root 20480 Mar 15 14:16 /tmp/test_find/size2.txt [root@C7 ~]# find /tmp/test_find/ -size +20k -name "size*.txt" -ls 17662798 32 -rw-r--r-- 1 root root 30720 Mar 15 14:16 /tmp/test_find/size3.txt [root@C7 ~]# find /tmp/test_find/ -size -20k -name "size*.txt" -ls 17662753 12 -rw-r--r-- 1 root root 10240 Mar 15 14:15 /tmp/test_find/size1.txt
但是,如果一個文件的大小是19.xKB或者20.xKB呢?
複製size2.txt,創建出2個文件,並且在size4.txt上刪除5行,在size5.txt上複製粘貼5行。
使得19KB<size4.txt<20KB;20KB<size5.txt<21KB。
-rw-r--r-- 1 root root 20086 Mar 15 14:37 /tmp/test_find/size4.txt -rw-r--r-- 1 root root 20786 Mar 15 14:38 /tmp/test_find/size5.txt
再次查找。
[root@C7 ~]# find /tmp/test_find/ -size 20k -name "size*.txt" -ls 17662782 20 -rw-r--r-- 1 root root 20480 Mar 15 14:32 /tmp/test_find/size2.txt 17662804 20 -rw-r--r-- 1 root root 20086 Mar 15 14:37 /tmp/test_find/size4.txt [root@C7 ~]# find /tmp/test_find/ -size -20k -name "size*.txt" -ls 17662753 12 -rw-r--r-- 1 root root 10240 Mar 15 14:15 /tmp/test_find/size1.txt [root@C7 ~]# find /tmp/test_find/ -size +20k -name "size*.txt" -ls 17662798 32 -rw-r--r-- 1 root root 30720 Mar 15 14:16 /tmp/test_find/size3.txt 17662811 24 -rw-r--r-- 1 root root 20786 Mar 15 14:38 /tmp/test_find/size5.txt
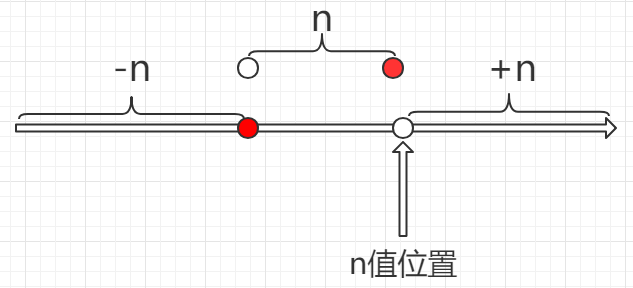
結論:
-size -n ≤ (n-1) (n-1) < -size n ≤ n -size +n > n
根據時間戳查找
-atime n:文件在n天前訪問過。在計算的時候,n天應該換算成(n*24)小時。計算的結果,是可以出現小數的,但是小數會被丟棄,從而取整。
因此無論是1.1天還是1.9天,都是會被認為是1天。假設現在的時間是“3月15日16:00:00”,那麼從“3月13日16:01:00”到“3月14日16:00:00”,都理解為1天。
n也支持正負號。
-1天:從“3月14日16:01:00”到“3月15日16:00:00”。
+1天:“3月13日16:00:00”之前。
-atime [+|-]n
-mtime [+|-]n
-ctime [+|-]n
time的單位是24小時,此外還有min,單位是分鐘,機制是類似的。
-amin [+|-]n
-mmin [+|-]n
-cmin [+|-]n
find根據時間查找,應該至少是基於分鐘的,至於是否基於秒,我不確定,也不太知道如何去測試。除非對時間的精度有較高的要求,否則就不深究了。
根據文件許可權查找
-perm [/|-] mode
-perm mode:精確許可權匹配,即文件的所有者、所有組和其他人的許可權都必須剛好符合mode。許可權不能比mode多,也不能比mode少。
[root@C7 ~]# find /tmp/test_find/ -name "*.log" -ls 17662763 0 -rwxrwxrwx 1 root root 0 Mar 13 16:18 /tmp/test_find/1.log 17662766 0 -rwxr-xr-x 1 root root 0 Mar 13 16:18 /tmp/test_find/2.log 17662767 0 -rw-rw-rw- 1 root root 0 Mar 13 16:18 /tmp/test_find/3.log 17662768 0 -rw-r--r-- 1 root root 0 Mar 13 16:18 /tmp/test_find/4.log 17662771 0 -rw-r--r-- 1 root root 0 Mar 13 16:18 /tmp/test_find/5.log 17662772 0 -rw-r--r-- 1 root root 0 Mar 13 16:46 /tmp/test_find/zwl.log 17662805 0 -rw-r--r-- 1 zwl zwl 0 Mar 14 17:21 /tmp/test_find/alongdidi.log 17662807 0 -rw-r--r-- 1 zwl zwl 0 Mar 14 17:21 /tmp/test_find/ALongDiDi.log 17662808 0 -rw-r--r-- 1 zwl zwl 0 Mar 14 17:21 /tmp/test_find/ALONGDIDI.log [root@C7 ~]# find /tmp/test_find/ -name "*.log" -perm 777 -ls 17662763 0 -rwxrwxrwx 1 root root 0 Mar 13 16:18 /tmp/test_find/1.log [root@C7 ~]# find /tmp/test_find/ -name "*.log" -perm 755 -ls 17662766 0 -rwxr-xr-x 1 root root 0 Mar 13 16:18 /tmp/test_find/2.log [root@C7 ~]# find /tmp/test_find/ -name "*.log" -perm 666 -ls 17662767 0 -rw-rw-rw- 1 root root 0 Mar 13 16:18 /tmp/test_find/3.log
-perm g=w:表示文件的許可權必須得是0020,除了組有寫許可權,其他的許可權位都為0。
-perm -mode:給出的許可權位之間的關係是邏輯與關係。例如:
[root@C7 ~]# find /tmp/test_find/ -name "*.log" -perm -422 -ls 17662763 0 -rwxrwxrwx 1 root root 0 Mar 13 16:18 /tmp/test_find/1.log 17662767 0 -rw-rw-rw- 1 root root 0 Mar 13 16:18 /tmp/test_find/3.log
查找至少所有者具有讀寫許可權並且(邏輯與)所有組具有寫許可權並且其他人具有寫許可權的log文件。不考慮其他額外的許可權。意思是如果在此基礎之上,還有執行許可權,那麼也會被找到。
-perm /mode:給出的許可權位之間的關係是邏輯或關係。例如:
find . -perm /222
查找那些可以被寫入的文件(無論是被所有者還是所有組還是其他人)。
find . -perm /111
查找可以被執行的文件。
find . -perm /220 find . -perm /u+w,g+w find . -perm /u=w,g=w
查找可以被用戶或者組寫入的文件。
操作符(operator)
操作符可用於組合表達式,用來決定表達式的處理優先順序。這裡按照優先順序從高到低說明一下。
\( expr \):優先順序最高。
! expr:取反。
expr1 expr2:省略-a或者-and,邏輯與。
expr1 -o expr2:等同-or,邏輯或。
expr1, expr2:列表;2個表達式都會被評估,expr1的評估值被忽略,列表的評估值取決於expr2。
表達式我們在書寫的時候,一般只會有一個option和action,或者沒有。操作符一般用於組合測試。
# find /tmp/test_find/ -name "*.log" -perm -422 -ls # find /tmp/test_find/ -name "*.txt" -o -perm /222
德摩爾定律
非(p且q)=(非p)或(非q)
非(p或q)=(非p)且(非q)
動作(action)
動作決定了對於查找到的文件要執行的操作。省略的話,預設是-print。
[root@C7 ~]# find /tmp/test_find/ -name "alongdidi.log" /tmp/test_find/alongdidi.log
-ls:列印類似“ls -l”的詳細信息。
-fls /PATH/TO/FILE:類似於-ls,區別在於多一步重定向輸出至文件。等同於“-ls > /PATH/TO/FILE”
-delete:將找到的文件刪除,不會有任何提示。無法用於刪除非空目錄。
find: cannot delete ‘/tmp/test_find/dir1’: Directory not empty
-ok COMMAND {} \;:對查找到的每個文件執行COMMAND指定的命令,每次執行COMMAND需要用戶確認。
{},即表示所查找到的文件。
[root@C7 ~]# find /tmp/test_find/ -type f -name "1.log" -ok stat {} \; < stat ... /tmp/test_find/1.log > ? y File: ‘/tmp/test_find/1.log’ Size: 0 Blocks: 0 IO Block: 4096 regular empty file Device: fd00h/64768d Inode: 17662763 Links: 1 Access: (0777/-rwxrwxrwx) Uid: ( 0/ root) Gid: ( 0/ root) Access: 2019-03-13 16:18:56.737451749 +0800 Modify: 2019-03-13 16:18:56.737451749 +0800 Change: 2019-03-15 16:14:53.413515181 +0800 Birth: -
-exec COMMAND {} \;:對查找到的每個文件執行COMMAND指定的命令,每次執行COMMAND不不不需要用戶確認!!!
在使用-ok或者-exec的時候,find先查找符合條件的文件,再將這些文件一次性全部交給後面的COMMAND處理,如果文件量比較大,則會報錯。
error: too many arguments
此時可以使用exargs命令解決。
find ... | xargs COMMAND
練習
1、查找/var目錄下屬主為root,且屬組為mail的所有文件或目錄。
~]# find /var -user root -group mail -ls
2、查找/usr目錄下不屬於root、bin或者hadoop的所有文件或目錄,請使用兩種方法。
~]# find /usr ! -user root ! -user bin ! -user hadoop -ls ~]# find /usr ! \( -user root -o -user bin -o -user hadoop \) -ls
3、查找/etc目錄下最近一周內其內容修改過,且屬主不是root用戶也不是hadoop用戶的文件或目錄。
~]# find /etc -mtime -7 ! -user root ! -user hadoop -ls ~]# find /etc -mtime -7 !\( -user root -o -user hadoop \) -ls
4、查找當前系統上沒有屬主或屬組,且最近一周內曾被訪問過的文件或目錄。
~]# find / \( -nouser -o -nogroup \) -atime -7 -ls
5、查找/etc目錄下大於1M且類型為普通文件的所有文件。
~]# find /etc -size +1M -type f -exec ls -lh {} \;
6、查找/etc目錄下所有用戶都沒有寫許可權的文件。
~]# find /etc ! -perm /222 -type f -ls
7、查找/etc目錄下至少有一類用戶沒有執行許可權的文件。
~]# find /etc ! -perm -111 -type f -ls
8、查找/etc/init.d目錄下,所有用戶都有執行許可權,且其他用戶有寫許可權的所有文件。
~]# find /etc/init.d -perm -111 -perm -002 -type f -ls ~]# find /etc/init.d -perm -113 -type f -ls


