
1.什麼是Hadoop 管理網路中跨多台電腦存儲的文件系統稱為分散式文件系統面臨的挑戰:使文件系統能容忍節點故障且不丟失任何數據不適合的特點:低時間延遲的數據訪問&大量的小文件&多用戶寫入,任意修改文件 2. HDFS的概念元數據hdfs的目錄結構及每一個文件的塊信息(塊的ID,塊的副本數量,塊的 ...
1.什麼是Hadoop
管理網路中跨多台電腦存儲的文件系統稱為分散式文件系統
面臨的挑戰:使文件系統能容忍節點故障且不丟失任何數據
不適合的特點:低時間延遲的數據訪問&大量的小文件&多用戶寫入,任意修改文件
2. HDFS的概念
元數據
hdfs的目錄結構及每一個文件的塊信息(塊的ID,塊的副本數量,塊的存放位置)
由namenode負責
數據塊
預設為64MB,最小化定址開銷
#分塊的好處:
1. 一個文件的大小可以大於網路中任意一個磁碟的容量
2. 使用塊抽象而非整個文件作為存儲單元,大大簡化了存儲子系統的設計。
3. 適用於數據備份,提供數據容錯能力和可用性。將每個塊複製到少數幾個獨立的機器上,預設為3個。
namenode和datanode
管理者-工作者模式運行
namenode:
管理文件系統的命名空間,(永久)命名空間鏡像文件和編輯日誌文件
(不永久,系統啟動時由數據節點重建)記錄每個文件中各個塊所在的數據節點信息
datanode:
存儲並檢索數據塊,定期向namenode發送它們所存儲的塊的列表。
如何對namenode進行容錯:
1. 備份那些組成文件系統元數據持久狀態的文件。將持久狀態寫入本地磁碟的同時,寫入一個遠程掛載的網路文件系統(NFS)。
2. 輔助namenode,定期通過編輯日誌合併命名空間鏡像,防止編輯日誌過大。
#節點全部失效,怎麼辦?
一般把NFS上的namenode元數據複製到輔助namenode並作為新的主namenode運行。
3.namenode元數據管理機制示意圖
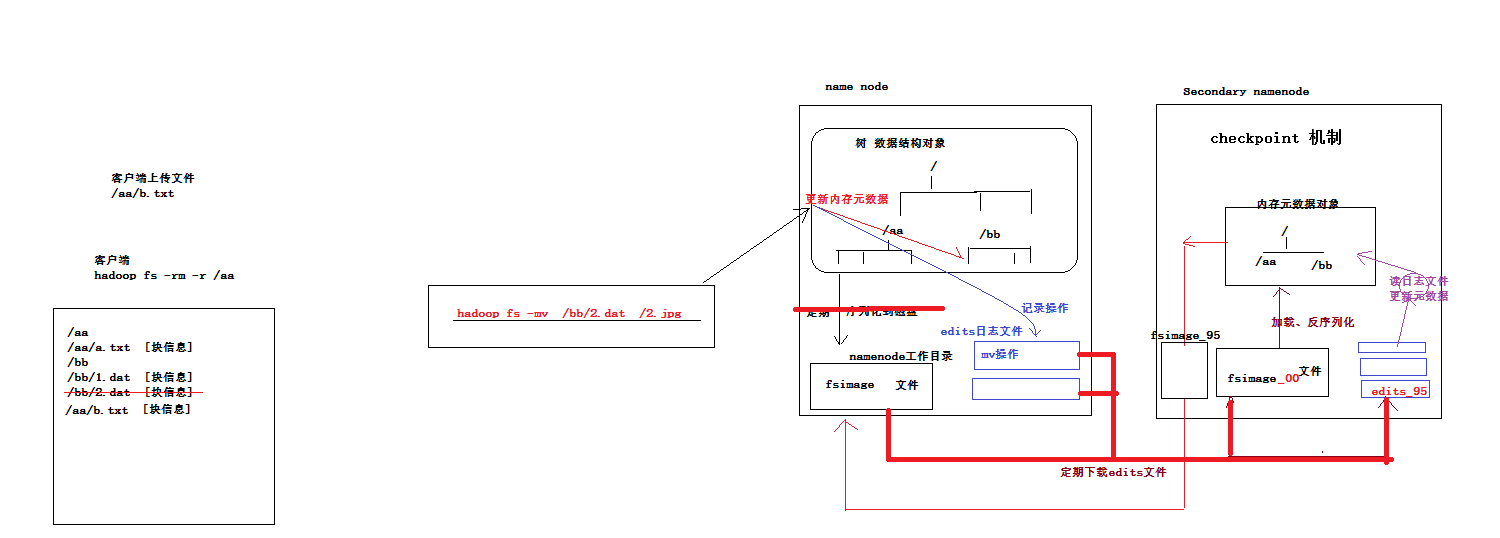
記憶體中有一份完整的元數據(記憶體meta data)
磁碟有一個“準完整”的元數據鏡像(fsimage)文件(在namenode的工作目錄中)
用於銜接記憶體meta data和持久化元數據鏡像fsimage之間的操作日誌(edits文件)註:當客戶端對hdfs中的文件進行新增或者修改操作,操作記錄首先被記入edits日誌文件中,當客戶端操作成功後,相應的元數據會更新到記憶體meta data中
每隔一段時間,會由secondary namenode將namenode上積累的所有edits和一個最新的fsimage(只有第一次需要下載)下載到本地,並載入到記憶體進行merge(這個過程稱為checkpoint)。
4.向HDFS寫入數據時的流程
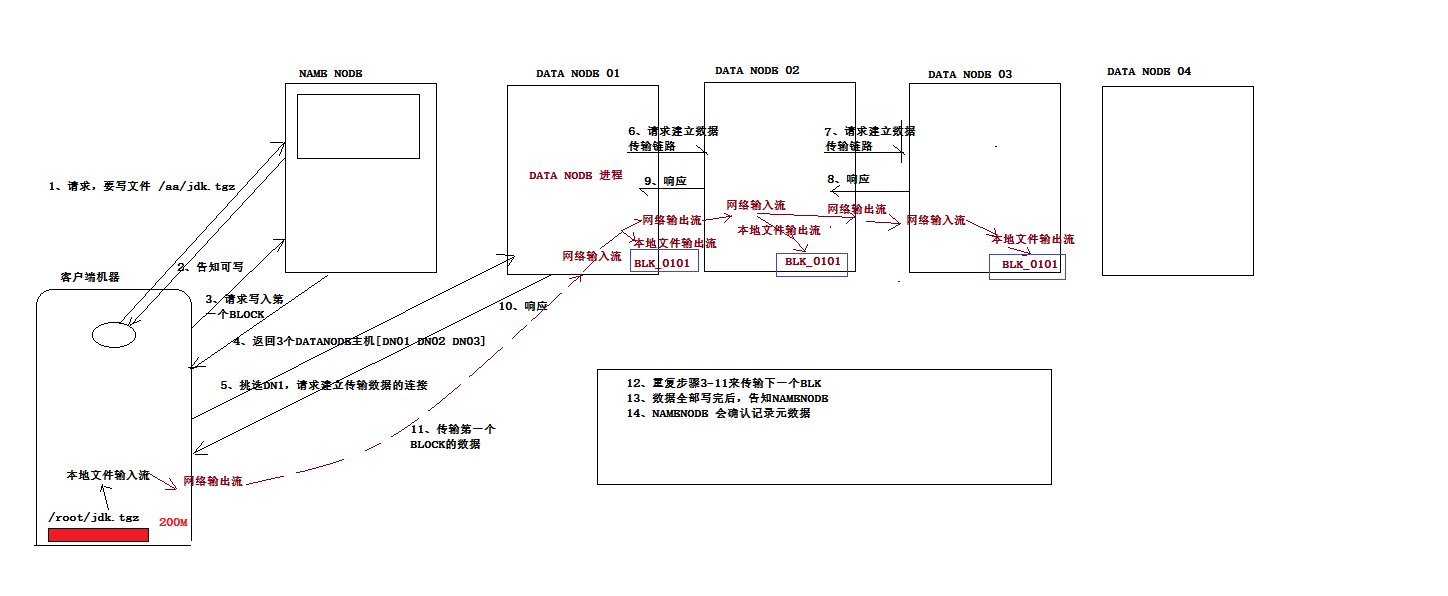
寫入期間如果發生故障,則執行:
(1)關閉管線,確認把隊列中的任何數據包都添加回數據隊列的最前端,以確保故障節點下游的節點不會漏掉數據包。
(2)為存儲在另一正常節點的當前數據塊指定一個新的標識,並將該標識傳送給namenode,以便故障節點在恢復後可以刪除存儲的部分數據包。
(3)從管線中刪除故障節點,並把餘下的數據塊寫入管線中的兩個正常的節點。namenode註意到複本量不足時,會在另一個節點上創建一個新的複本。
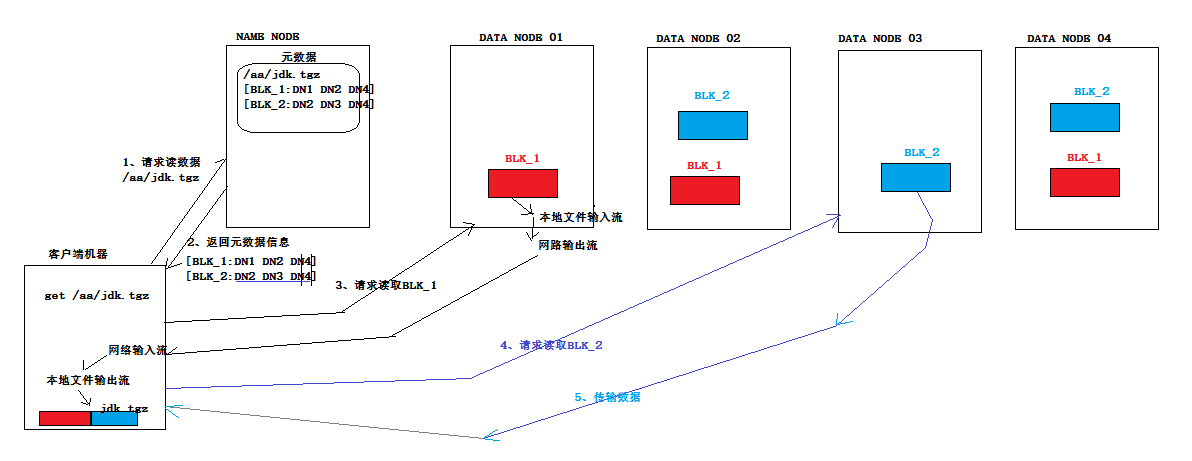
5.從HDFS讀取數據時的流程
6.網路拓補和Hadoop
如何計算兩個節點間的距離?
同一節點中的進程<同一機架上的不同節點<同一數據中心中不同機架上的節點<不同數據中心中的節點
7.複本的佈局
可靠性、寫入帶寬和讀取帶寬
預設的策略:
在運行客戶端的節點/隨機選一個節點 作為第一個
和第一個不同的機架中的節點 作為第二個
和第二個相同的機架,不同節點 作為第三個
一旦選定後,會根據網路拓補創建一個管線。
穩定性:兩個機架
寫入帶寬:寫入操作只需要遍歷一個交換機
讀取性能:可以從兩個機架中進行選擇讀取
集群中塊的均勻分佈:客戶端只在本地機架寫入一個塊
8.數據完整性
檢測數據是否損壞的常見措施:
在數據第一次引入系統時計算校驗和,併在數據通過一個不可靠通道進行傳輸時再次計算校驗和,如果不匹配,則說明有損壞,但不能修複數據,常用的錯誤檢測碼為CRC-32.
HDFS的數據完整性
對寫入和讀取的數據分別計算與驗證校驗和
數據校驗的幾種場景:
(1)客戶端向datanode發送數據,最後一個datanode收到數據後,驗證數據的驗證和與客戶端的是否一致。
(2)客戶端從datanode讀取數據時,也會驗證校驗和,並記錄在datanode上。(這些對檢測損壞的磁碟很有價值)
(3)datanode會在後臺線程中運行一個datablockscanner,從而定期驗證存儲在這個datanode上的所有數據塊。
HDFS常見面試題:
1. HDFS 中的 block 預設保存3份
2. HDFS 預設 BlockSize 是 64MB(2.7.2版本,本地模式)128MB(2.7.2版本,分散式模式)
3. Client 端上傳文件的時候下列哪項正確:
- Client端將文件切分為Block,依次上傳
- Client只上傳數據到一臺DataNode,然後由NameNode負責Block複製工作
4.DataNode負責 HDFS 數據存儲
5.關於SecondaryNameNode 哪項是正確的?(C)
A.它是NameNode的熱備
B.它對記憶體沒有要求
C.他的目的使幫助NameNode合併編輯日誌,減少NameNode 啟動時間
6.下列哪個程式通常與 NameNode 在一個節點啟動?(D)
A.SecondaryNameNode
B.DataNode
C.TaskTracker
D.JobTracker
*****
hadoop的集群是基於master/slave模式,namenode和jobtracker屬於master,datanode和tasktracker屬於slave,master只有一個,而slave有多個。
SecondaryNameNode記憶體需求和NameNode在一個數量級上,所以通常secondary NameNode(運行在單獨的物理機器上)和 NameNode 運行在不同的機器上。
JobTracker對應於NameNode,TaskTracker對應於DataNode。
DataNode和NameNode是針對數據存放來而言的。JobTracker和TaskTracker是對於MapReduce執行而言的。
mapreduce中幾個主要概念,mapreduce 整體上可以分為這麼幾條執行線索:
jobclient,JobTracker與TaskTracker。
1)JobClient會在用戶端通過JobClient類將已經配置參數打包成jar文件的應用存儲到hdfs,並把路徑提交到Jobtracker,然後由JobTracker創建每一個Task(即 MapTask 和 ReduceTask)並將它們分發到各個TaskTracker服務中去執行。
2)JobTracker是一master服務,軟體啟動之後JobTracker接收Job,負責調度Job的每一個子任務。task運行於TaskTracker上,並監控它們,如果發現有失敗的task就重新運行它。一般情況應該把JobTracker 部署在單獨的機器上。
3)TaskTracker是運行在多個節點上的slaver服務。TaskTracker主動與JobTracker通信,接收作業,並負責直接執行每一個任務。TaskTracker 都需要運行在HDFS的DataNode上。
*****
7.文件大小預設為 64M,改為 128M 有啥影響?
增加文件塊大小,需要增加磁碟的傳輸速率。
8.HDFS的存儲機制(讀取和寫入)
9.secondarynamenode工作機制
1)第一階段:namenode啟動
(1)第一次啟動namenode格式化後,創建fsimage和edits文件。如果不是第一次啟動,直接載入編輯日誌和鏡像文件到記憶體。
(2)客戶端對元數據進行增刪改的請求
(3)namenode記錄操作日誌,更新滾動日誌。
(4)namenode在記憶體中對數據進行增刪改查
2)第二階段:Secondary NameNode工作
(1)SecondaryNameNode詢問namenode是否需要checkpoint。直接帶回namenode是否檢查結果。
(2)SecondaryNameNode請求執行checkpoint。
(3)namenode滾動正在寫的edits日誌
(4)將滾動前的編輯日誌和鏡像文件拷貝到Secondary NameNode
(5)SecondaryNameNode載入編輯日誌和鏡像文件到記憶體,併合並。
(6)生成新的鏡像文件fsimage.chkpoint
(7)拷貝fsimage.chkpoint到namenode
(8)namenode將fsimage.chkpoint重新命名成fsimage
10. NameNode與SecondaryNameNode 的區別與聯繫?
1)機制流程同上;
2)區別
(1)NameNode負責管理整個文件系統的元數據,以及每一個路徑(文件)所對應的數據塊信息。
(2)SecondaryNameNode主要用於定期合併命名空間鏡像和命名空間鏡像的編輯日誌。
3)聯繫:
(1)SecondaryNameNode中保存了一份和namenode一致的鏡像文件(fsimage)和編輯日誌(edits)。
(2)在主namenode發生故障時(假設沒有及時備份數據),可以從SecondaryNameNode恢複數據。
11. namenode記憶體包含哪些,具體如何分配
NameNode整個記憶體結構大致可以分成四大部分:Namespace、BlocksMap、NetworkTopology及其它。
1)Namespace:維護整個文件系統的目錄樹結構及目錄樹上的狀態變化;
2)BlockManager:維護整個文件系統中與數據塊相關的信息及數據塊的狀態變化;
3)NetworkTopology:維護機架拓撲及DataNode信息,機架感知的基礎;
4)其它:
LeaseManager:讀寫的互斥同步就是靠Lease實現,支持HDFS的Write-Once-Read-Many的核心數據結構;
CacheManager:Hadoop 2.3.0引入的集中式緩存新特性,支持集中式緩存的管理,實現memory-locality提升讀性能;
SnapshotManager:Hadoop 2.1.0引入的Snapshot新特性,用於數據備份、回滾,以防止因用戶誤操作導致集群出現數據問題;
DelegationTokenSecretManager:管理HDFS的安全訪問;
另外還有臨時數據信息、統計信息metrics等等。
NameNode常駐記憶體主要被Namespace和BlockManager使用,二者使用占比分別接近50%。其它部分記憶體開銷較小且相對固定,與Namespace和BlockManager相比基本可以忽略。


