
一、創建項目 1.創建一個.netframework的控制台項目命名為Crawler 2.安裝nuget包搜索名稱Ivony.Html.AIO,使用該類庫什麼方便類似jqury的選擇器可以根據類名或者元素類型來匹配元素,無需要寫正則表達式。 3.創建一個圖片類Image 一、抓取頁面圖片 1.拿到所 ...
一、創建項目
1.創建一個.netframework的控制台項目命名為Crawler
2.安裝nuget包搜索名稱Ivony.Html.AIO,使用該類庫什麼方便類似jqury的選擇器可以根據類名或者元素類型來匹配元素,無需要寫正則表達式。
3.創建一個圖片類Image

一、抓取頁面圖片
1.拿到所有圖片頁面的地址
本次爬取的網站為https://www.mntup.com/,打開頁面進入二級目錄https://www.mntup.com/SiWa.html,並查頁面看源代碼,如下圖:

圖片頁都在class=“dana”的div下麵,我們要拿去div中超鏈接的href,如下格式:
<div class="dana"><a href=/Rosimm/liantiyimeizi_4f4d781d.html title=[Rosi寫真]NO.2637_紅色吊帶高叉連體衣妹子床上狗爬式秀渾圓翹臀撩人誘惑寫真38P target=_blank>
[Rosi寫真]NO.2637_紅色吊帶高叉連體衣妹子床上狗爬式秀渾圓翹臀撩人誘惑寫真38P <b> <font color=ff0000>2019-02-26</b></font>
</a></div>
首先考慮要拿到所有圖片頁面的超鏈接,c#代碼下:
//需要定義一個list用來存放所有的頁面鏈接
static List<string> categoryUrl = new List<string>();
//載入url到文檔
IHtmlDocument source = new JumonyParser().LoadDocument("https://www.mntup.com/XiuRen.html", System.Text.Encoding.GetEncoding("utf-8"));
//獲取所有class=dana的的a標簽
var divLinks = source.Find(".dana a");
foreach (var aLink in divLinks)
{
var categoryName = aLink.Attribute("href").Value(); //獲取a中的鏈接
categoryUrl.Add(categoryName);
}
2.打開圖片頁,發現是帶有分頁的,那就要獲取所有的分頁的鏈接了。分頁的地址都在頁面當中,所以我們直接匹配就好。
由於每個圖片頁都有分頁地址,所以直接匹配分頁地址,C#代碼如下:
foreach (var url in categoryUrl)
{
//獲取圖片也的的文檔
IHtmlDocument html = new JumonyParser().LoadDocument($"{address}{url}", System.Text.Encoding.GetEncoding("utf-8"));
//獲取每個分頁面並下載
var pageLink = html.Find(".page a");
foreach (var alingk in pageLink)
{
string href = alingk.Attribute("href").Value();
Console.WriteLine($"獲取分頁地址{href}");
}
}
3.所有分頁都獲取到了,接下來就是要獲取頁面中的每張圖片了,打開頁面查看源代碼:

觀察發現,所有的圖片都在class=img的div下麵,那就可以從每個分頁中直接下載所有的圖片了,代碼如下:
//獲取每一個分頁的文檔模型
IHtmlDocument htm2 = new JumonyParser().LoadDocument($"{address}{href}", System.Text.Encoding.GetEncoding("utf-8"));
//獲取class=img的div下的img標簽
var aLink = htm2.Find(".img img");
foreach (var link in aLink)
{
var imgsrc = link.Attribute("src").Value();
Console.WriteLine("獲取到圖片路徑" + imgsrc);
Console.WriteLine($"開始下載圖片{imgsrc}>>>>>>>");
DownLoadImg(new Image { Address = address + imgsrc, Title = url });
}
}
圖片下載方法如下,為防止下載的時候阻塞主進程,下載採用非同步:
/// <summary>
/// 異不下載圖片
/// </summary>
/// <param name="image"></param>
async static void DownLoadImg(Image image)
{
using (WebClient client = new WebClient())
{
try
{
int start = image.Address.LastIndexOf("/") + 1;
string fileName = image.Address.Substring(start, image.Address.Length - start);
//圖片目錄採用頁面地址作為文件名
string directory = "c:/images/" + image.Title.Replace("/", "-").Replace("html", "") + "/";
if (!Directory.Exists(directory))
{
Directory.CreateDirectory(directory);
}
await client.DownloadFileTaskAsync(new Uri(image.Address), directory + fileName);
}
catch (Exception)
{
Console.WriteLine($"{image.Address}下載失敗");
File.AppendText(@"c:/log.txt");
}
Console.WriteLine($"{image.Address}下載成功");
}
}
三、抓取圖片
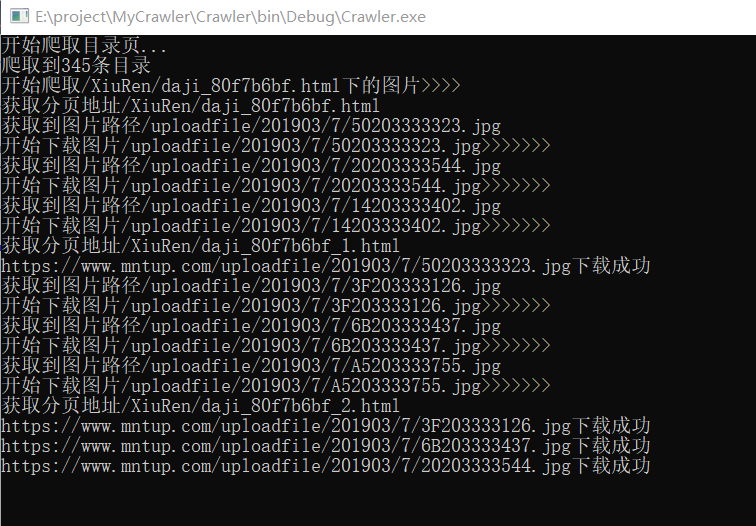
由於編碼格式的問題,無法獲取到中文標題,所有就採取了頁面鏈接作為目錄名稱,下麵是一張我抓取圖片的截圖:
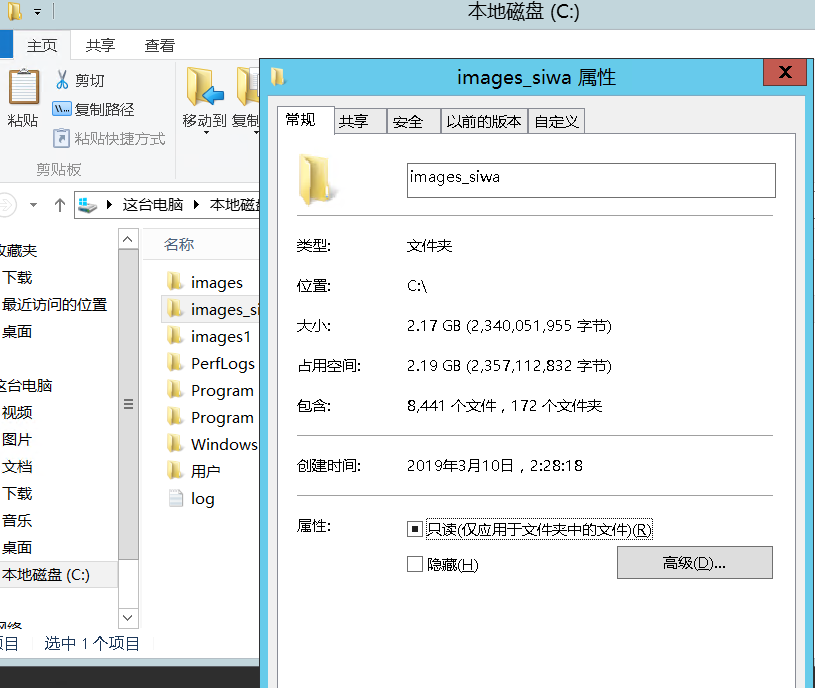
最後的戰果:
最後奉上代碼如下:https://github.com/peijianmin/MyCrawler.git


