
一、XML: 1、基本瞭解: xml,Extensible markup language可擴展標記語言,用於數據的傳輸或保存,特點,格式非常整齊數據清晰明瞭,並且任何語言都內置了xml分析引擎, 不需要再單獨寫引擎,但是相較於json解析較慢,現在很多項目任然有廣泛的應用。 2、幾種解析和生成xm ...
一、XML:
1、基本瞭解:
xml,Extensible markup language可擴展標記語言,用於數據的傳輸或保存,特點,格式非常整齊數據清晰明瞭,並且任何語言都內置了xml分析引擎,
不需要再單獨寫引擎,但是相較於json解析較慢,現在很多項目任然有廣泛的應用。
2、幾種解析和生成xml的方式:這裡,為了最後我們比較幾種xml的解析以及生成速度,我們使用一個同一的xml進行生成以及解析:
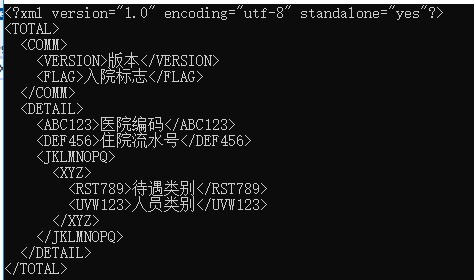
<?xml version="1.0" encoding="utf-8" standalone="yes"?> <TOTAL> <COMM> <VERSION>版本</VERSION> <FLAG>入院標誌</FLAG> </COMM> <DETAIL> <ABC123>醫院編碼</ABC123> <DEF456>住院流水號</DEF456> <JKLMNOPQ> <XYZ> <RST789>待遇類別</RST789> <UVW123>人員類別</UVW123> </XYZ> </JKLMNOPQ> </DETAIL> </TOTAL>
這是一個簡單自己加的醫院用的部分數據,可以使用自己覺的好用的xml,這裡生成全部,獲取數據我們全部取待遇類別這一項。
A、XmlReader和XmlWriter類:
public static string CreateXml() { //Indent屬性設置或獲取是否縮進的值 var xws = new XmlWriterSettings() {Indent=true,Encoding = Encoding.UTF8 }; StringBuilder sb = new StringBuilder(); //調用XmlWriter的靜態生成方法Create,需要2個參數或者一個參數,一個作為輸出 //另一個設置xml的格式 using (XmlWriter xw = XmlWriter.Create(sb,xws)) { //這裡括弧里的屬性用來設置standalone的值 xw.WriteStartDocument(true); xw.WriteStartElement("TOTAL"); xw.WriteStartElement("COMM"); xw.WriteElementString("VERSION", "版本"); xw.WriteElementString("FLAG", "入院標誌"); xw.WriteEndElement(); xw.WriteStartElement("DETAIL"); xw.WriteElementString("ABC123", "醫院編碼"); xw.WriteElementString("DEF456", "住院流水號"); xw.WriteStartElement("JKLMNOPQ"); xw.WriteStartElement("XYZ"); xw.WriteElementString("RST789", "待遇類別"); xw.WriteElementString("UVW123", "人員類別"); xw.WriteEndElement(); xw.WriteEndElement(); xw.WriteEndElement(); xw.WriteEndDocument(); } //這裡因為字元串的格式是utf-16,通過最簡單的方式調用Replace方法即可。如果是stringwriter,則使用派生類重寫Encoding方法即可。 return sb.ToString().Replace("utf-16","utf-8"); }
這裡我們先來簡單解釋一下standalone的意思,這個表示你所寫的xml是否是獨立的,如果為yes則表示它是獨立的不能引用任何的DTD文件,
如果是no則表示它不是獨立的,可以用外部的DTD文件,DTD文件:Document Type Definition文檔類型定義,它是一套語法規則,用來檢驗你所寫的
標準通用標記語言或者可擴展標記語言是否符合規則。
這裡可以看到這個創建還是很簡單的,WriteStartDocument創建文檔,WriteEndDocument結束文檔,WriteStartElement創建標簽,WriteEndElement
創建結束標簽,如果有具體值的使用WriteElementString(),接受2個參數:標簽名和具體的值,同樣的如果此標簽有屬性,使用WriteAttributeString()方法
即可。上面是書寫xml的過程,現在開始獲取xml的值:
public static string GetXmlInnerValue() { string result = string.Empty; //仍然調用XmlReader的Create靜態方法生成 using (XmlReader reader = XmlReader.Create("Hospital.xml")) { while (reader.Read()) { try { //Read()方法會連xml的空白一起讀,所以要加上XmlNodeType.Element來讀元素 if (reader.MoveToContent() == XmlNodeType.Element && reader.Name == "RST789") { //這裡微軟建議儘量使用ReadElementContentAsString()方法,速度更快 //因為某些元素會比較複雜,所以使用ReadAsString方法要捕獲異常,在異常中繼續調用Read()方法就行了 result = reader.ReadElementContentAsString(); } else { reader.Read(); } } catch (Exception ex) { reader.Read(); } } } return result; }

這裡也比較簡單,通過調用Read()方法,在通過Name屬性值,就可以確定我們要找的值。如果是要找屬性值,調用
Reader的GetAttribute()方法即可,參數是屬性的名稱。
B、XmlSerializer類,通過序列化的手段操作xml,當然,用了序列化,那麼相對的時間也會多一點,後面來證明,先建對象:
public class XYZ { [XmlElement("RST789")] public string Treatment { get; set; } [XmlElement("UVW123")] public string Personnel{ get; set; } }
public class JKLMNOPQ { [XmlElement] public XYZ XYZ { get; set; } }
public class DETAIL { [XmlElement("ABC123")] public string HospitalId { get; set; } [XmlElement("DEF456")] public string ResidentId { get; set; } [XmlElement] public JKLMNOPQ JKLMNOPQ { get; set; } }
public class COMM { [XmlElement] public string VERSION { get; set; } [XmlElement] public string FLAG { get; set; } }
[XmlRoot] public class TOTAL { [XmlElement] public COMM COMM { get; set; } [XmlElement] public DETAIL DETAIL { get; set; } }
這裡我在項目里新建了個Model文件夾,然後添加了這5個類,可以看到這些類或者屬性上面都有特性,特性是個常用也比較好用的東西,
可以暫時理解為註釋這樣一種東西對它所描述的東西的一個註解,後面詳細會說,XmlRoot代表是xml中的根元素,XmlElement代表元素,
XmlAttribute代表屬性,XmlIgnore則表示不序列化,後面如果有參數,則參數值表示在Xml中真實的值,比如類XYZ中,Treatment待遇類別,
但是xml中當然不能用Treatment顯示,要用RST789顯示,放在特性中就可以了,現在生成xml:
public static TOTAL GetTotal() => new TOTAL { COMM = new COMM { VERSION = "版本", FLAG = "入院標誌" }, DETAIL = new DETAIL { HospitalId = "醫院編碼", ResidentId = "住院流水號", JKLMNOPQ = new JKLMNOPQ { XYZ = new XYZ { Treatment = "待遇類別", Personnel = "人員類別" } } } }; public static string CreateXml() { string xml = string.Empty; using (StringWriter sw = new StringWriter()) { XmlSerializerNamespaces xsn = new XmlSerializerNamespaces(); xsn.Add(string.Empty,string.Empty); XmlSerializer serializer = new XmlSerializer(typeof(TOTAL)); serializer.Serialize(sw,GetTotal(),xsn); xml = sw.ToString().Replace("utf-16","utf-8"); } return xml; }
先說明下第一個方法,這裡用了C#6.0的新特性,如果表達式體方法只有一個,可以通過lambda語法來書寫。
第二個方法裡面直接調用XmlSerializer的Serialize方法進行序列化就可以了,那麼反序列化用DeSerialize方法就可以了,這裡的Serialize方法
有多鐘參數,筆者可根據需要做相應調整,這裡xml聲明中的standalone不能做對應的書寫,查了半天沒有查到,如果再用XmlWriter或者DOM
做的話就用到了那這種方法的結合,如果有更好的方法可以留言,感激感激。
public static string GetXmlInnerValue() { TOTAL total = null; using (FileStream fs = new FileStream("Hospital.xml",FileMode.Open)) { XmlSerializer serializer = new XmlSerializer(typeof(TOTAL)); total = serializer.Deserialize(fs) as TOTAL; } return total.DETAIL.JKLMNOPQ.XYZ.Treatment; }

這裡我儘量不適用XmlReader之類的轉換xml方法,反序列化將xml轉換為類,然後通過屬性取到所需要的值。
C、DOM:現在說明很常見的一種解析xml方式DOM ,Document Obejct Model文檔對象模型。說明一下DOM的工作方式,先將xml文檔裝入到記憶體,
然後根據xml中的元素屬性創建一個樹形結構,也就是文檔對象模型,將文檔對象化。那麼優勢顯而易見,我麽可以直接更新記憶體中的樹形結構,因此
對於xml的插入修改刪除效率更高。先看xml的書寫:
public static string CreateXml() { XmlDocument doc = new XmlDocument(); XmlElement total = doc.CreateElement("TOTAL"); XmlElement comm = doc.CreateElement("COMM"); total.AppendChild(comm); XmlElement version = doc.CreateElement("VERSION"); version.InnerXml = "版本"; comm.AppendChild(version); XmlElement flag = doc.CreateElement("FLAG"); flag.InnerXml = "入院標誌"; comm.AppendChild(flag); XmlElement detail = doc.CreateElement("DETAIL"); total.AppendChild(detail); XmlElement abc123 = doc.CreateElement("ABC123"); abc123.InnerXml = "醫院編碼"; detail.AppendChild(abc123); XmlElement def456 = doc.CreateElement("DEF456"); def456.InnerXml = "住院流水號"; detail.AppendChild(def456); XmlElement JKLMNOPQ = doc.CreateElement("JKLMNOPQ"); detail.AppendChild(JKLMNOPQ); XmlElement XYZ = doc.CreateElement("XYZ"); JKLMNOPQ.AppendChild(XYZ); XmlElement RST789 = doc.CreateElement("RST789"); RST789.InnerXml = "待遇類別"; XmlElement UVW123 = doc.CreateElement("UVW123"); UVW123.InnerXml = "人員類別"; XYZ.AppendChild(RST789); XYZ.AppendChild(UVW123); XmlDeclaration declaration = doc.CreateXmlDeclaration("1.0","utf-8","yes"); doc.AppendChild(declaration); doc.AppendChild(total); //XmlDocument的InnerXml屬性只有元素內的內容,OuterXml則包含整個元素 return doc.OuterXml; }

這裡的創建Xml還是比較簡單的,document create一個XmlElement,Append一下,最後全部append到document上就可以了。
說明一下innerXml和innerText,這個學過html的人應該都懂,innertext和innerhtml區別一樣,如果是純字元,則兩者通用,如果是
帶有標簽這種的<>,這樣innerText則會將其翻譯為<和>這樣,而innerXml則不會翻譯。另外如果是獲取xml的內容,innerText
會獲取所有的值,而innerXml則會將節點一起返回,現在獲取xml的值:
public static string GetXmlInnerValue() { string result = string.Empty; XmlDocument doc = new XmlDocument(); doc.Load("Hospital.xml"); XmlNode xn = doc.SelectSingleNode("/TOTAL/DETAIL/JKLMNOPQ/XYZ/RST789"); result = xn.InnerXml; return result; }

這裡經常用的就是XmlNode類,所有節點的抽象基類,提供了對節點的操作方法和屬性,XmlNodeList類XmlNode的一組,如果有重覆的節點
則使用XmlNodeList通過doc的GetElementsByTagName()獲取,然後通過index獲取需要的具體節點。還有這裡SelectSingleNode()方法的參數
是這個節點的具體位置,而非節點名稱,不然會報NullReferenceException。再說一下常用的屬性,有HasChildNodes是否有子節點,ChildNodes
所有子節點,FirstChild第一個子節點,ParentChild父節點,NextSibling下一個兄弟節點,PreviousSibling 上一個兄弟節點。
D、使用LINQ解析:簡單說下linq是什麼,語言集成查詢C#裡面linq提供了不同數據的抽象層,所以可以使用相同的語法訪問不同的數據源,簡單來說
就是可以查詢出一系列的數據不僅僅是從資料庫查詢,後面的篇章會進行詳細說明。
public static string CreateXml() { string xml = string.Empty; XDocument doc = new XDocument( new XDeclaration("1.0","utf-8","yes"), new XElement("TOTAL", new XElement("COMM", new XElement("VERSION","版本"), new XElement("FLAG","入院標誌")), new XElement("DETAIL", new XElement("ABC123","醫院編碼"), new XElement("DEF456","住院流水號"), new XElement("JKLMNOPQ", new XElement("XYZ", new XElement("RST789","待遇類別"), new XElement("UVW123","人員類別")))))); StringBuilder sb = new StringBuilder(); using (XmlWriter xw = XmlWriter.Create(sb)) { doc.WriteTo(xw); } xml = sb.ToString().Replace("utf-16","utf-8"); return xml; }

這裡使用了XDocument這個類創建xml也是很簡單的,主要註意一下括弧別多別少就行了,同樣需要編碼轉換不然仍然出來的是utf-16。
public static string GetXmlInnerValue() { string result = string.Empty; XDocument doc = XDocument.Load("Hospital.xml"); var query = from r in doc.Descendants("RST789") select r; foreach (var item in query) { result = item.Value; } return result; }

這裡Linq同樣也是使用以操作記憶體的方式操作xml,和DOM的方式比較類似,也是比較快速的方法。
E、XPathNavigator類:System.Xml.XPath下的一個抽象類,它根據實現IXPathNavigable的介面的類創建,如XPathDocument,XPathNavigator。由XPathDocument創建的XPathNavigator是只讀對象,對於.net framework由XmlDocument創建的XPathNavigator可以進行修改,它的CanEdit屬性為true,必須要在4.6版本以上,可以使用#if進行判斷。對於.net core沒有提供CreateNavigator這個方法所以它始終是可讀的。這個類可以理解為一個游標搜索,一個Navigator對數據進行導航,它不是一個流模型,對於xml只分析和讀取一次。
public static string GetXmlInnerValue() { string str = string.Empty; XPathDocument doc = new XPathDocument("Hospital.xml"); XPathNavigator navigator = doc.CreateNavigator(); XPathNodeIterator iterator = navigator.Select("/TOTAL/DETAIL/JKLMNOPQ/XYZ/RST789"); while (iterator.MoveNext()) { if (iterator.Current.Name == "RST789") { str = iterator.Current.Value; } } return str; }
public static string GetValue() { string result = string.Empty; XPathDocument doc = new XPathDocument("Hospital.xml"); XPathNavigator navigator = doc.CreateNavigator(); XPathNodeIterator iterator = navigator.Select("/TOTAL"); while (iterator.MoveNext()) { XPathNodeIterator iteratorNew = iterator.Current.SelectDescendants(XPathNodeType.Element, false); while (iteratorNew.MoveNext()) { if (iteratorNew.Current.Name== "RST789") { result = iteratorNew.Current.Value; } } } return result; }
如果沒有重覆節點的情況下直接用第一種寫好路徑就行了,如果有重覆節點就要用第二種進行多次迴圈了。現在我們用StopWatch進行時間監測。
static void Main(string[] args) { Console.WriteLine("生成xml的時間:"); Stopwatch sw = new Stopwatch(); sw.Start(); XmlReaderAndXmlWriter.CreateXml(); sw.Stop(); Console.WriteLine($"XmlReaderAndXmlWriter生成時間:{sw.Elapsed}"); sw.Reset(); sw.Restart(); XmlSerializerSample.CreateXml(); sw.Stop(); Console.WriteLine($"XmlSerializerSample生成時間:{sw.Elapsed}"); sw.Reset(); sw.Restart(); DomSample.CreateXml(); sw.Stop(); Console.WriteLine($"DomSample生成時間:{sw.Elapsed}"); sw.Reset(); sw.Restart(); LinqSample.CreateXml(); sw.Stop(); Console.WriteLine($"LinqSample生成時間:{sw.Elapsed}"); sw.Reset(); Console.WriteLine("====================================================="); Console.WriteLine("查詢xml的時間:"); sw.Restart(); XmlReaderAndXmlWriter.GetXmlInnerValue(); sw.Stop(); Console.WriteLine($"XmlReaderAndXmlWriter查詢時間:{sw.Elapsed}"); sw.Reset(); sw.Restart(); XmlSerializerSample.GetXmlInnerValue(); sw.Stop(); Console.WriteLine($"XmlSerializerSample查詢時間:{sw.Elapsed}"); sw.Reset(); sw.Restart(); DomSample.GetXmlInnerValue(); sw.Stop(); Console.WriteLine($"DomSample查詢時間:{sw.Elapsed}"); sw.Reset(); sw.Restart(); LinqSample.GetXmlInnerValue(); sw.Stop(); Console.WriteLine($"LinqSample查詢時間:{sw.Elapsed}"); sw.Reset(); sw.Restart(); XPathNavigatorSample.GetXmlInnerValue(); sw.Stop(); Console.WriteLine($"XPathNavigatorSample查詢時間:{sw.Elapsed}"); }

這裡我們可以看到無論是生成還是查詢都是DOM的操作更為快速一點,序列化相比就慢很多了,另外比較新的技術XPathNavigator也很快了,
再綜合代碼的精簡程度,選擇合適的方法進行傳輸數據就可以了。現在開始總結JSON的2種常用用法。
二、JSON:
1、簡介:Javascript Object Notation是一種輕量級的數據交互格式,採用完全獨立於語言的格式傳輸和存儲數據,語法簡介,相較於xml解析速度更快。
2、介紹2種常用的解析方式。
先設定一個json做比較對象:
{ "code": "001", "feedBackMsg": "輸出結算錯誤原因", "messages": [ { "uuid": "550e8400-e29b-41d4-a716-446655440000", "ruleId": "a0001", "triggerLevel": "1", "involvedCost": 6, "content": "病人住院his金額與社保金額不相等", "comments": "", "feedBackMsg": "his結算金額應與社保金額相等", "encounterResults": [ { "encounterId": "1", "orderIds": [] } ] }, { "uuid": "550e8400-e19b-41d4-a716-446655440000", "ruleId": "b0001", "triggerLevel": "2", "involvedCost": 9, "content": "患者處方中存在配伍禁忌的中藥【烏頭】、【貝母】。", "comments": "", "feedBackMsg": "該病人這兩種藥品非同時使用", "encounterResults": [ { "encounterId": "1", "orderIds": [ "cf01", "cf02" ] } ] } ] }
然後用2種方式分別生成:
第一種:
public static string CreateJson1() { string json = string.Empty; Dictionary<string, object> data = new Dictionary<string, object> { {"code" ,"001" }, {"feedBackMsg" ,"輸出結算錯誤原因" }, {"messages" ,new List<object>{ new Dictionary<string,object> { {"uuid" ,"550e8400-e29b-41d4-a716-446655440000"}, {"ruleId" ,"a0001"}, {"triggerLevel" ,"1"}, {"involvedCost" ,6}, {"content" ,"病人住院his金額與社保金額不相等"}, {"comments","" }, {"feedBackMsg" ,"his結算金額應與社保金額相等"}, {"encounterResults" ,new List<object> { new Dictionary<string,object>{ {"encounterId","1" }, {"orderIds" ,new List<object> { } } } } } }, new Dictionary<string, object> { {"uuid" ,"550e8400-e19b-41d4-a716-446655440000"}, {"ruleId" ,"b0001"}, {"triggerLevel" ,"2"}, {"involvedCost" ,9}, {"content" ,"患者處方中存在配伍禁忌的中藥【烏頭】、【貝母】。"}, {"comments" ,""}, {"feedBackMsg" ,"該病人這兩種藥品非同時使用"}, {"encounterResults" ,new List<object> { new Dictionary<string,object> { {"encounterId","1" }, {"orderIds" ,new List<object> { "cf01","cf02" } } } } } } } } }; json = JsonConvert.SerializeObject(data,Formatting.Indented);


