
首先, 還是以天氣為例, 準備如下數據: 輸出: 上面的例子就是以 'city' 為基準對兩個 dataframe 進行合併, 但是兩組數據都是高度一致, 下麵調整一下: 輸出:從輸出我們看出, 通過 merge 合併, 會取兩個數據的交集. 那麼, 我們應該可以設想到, 可以通過調整參數, 來達到 ...
首先, 還是以天氣為例, 準備如下數據:
df1 = pd.DataFrame({
'city': ['newyork', 'chicago', 'orlando'],
'temperature': [21, 24, 32],
})
df2 = pd.DataFrame({
'city': ['newyork', 'chicago', 'orlando'],
'humidity': [89, 79, 80],
})
df = pd.merge(df1, df2, on='city')
輸出: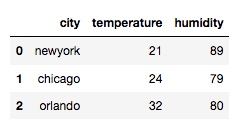
上面的例子就是以 'city' 為基準對兩個 dataframe 進行合併, 但是兩組數據都是高度一致, 下麵調整一下:
df1 = pd.DataFrame({
'city': ['newyork', 'chicago', 'orlando', 'baltimore'],
'temperature': [21, 24, 32, 29],
})
df2 = pd.DataFrame({
'city': ['newyork', 'chicago', 'san francisco'],
'humidity': [89, 79, 80],
})
df = pd.merge(df1, df2, on='city')
輸出: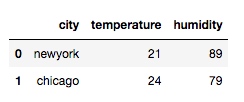
從輸出我們看出, 通過 merge 合併, 會取兩個數據的交集.
那麼, 我們應該可以設想到, 可以通過調整參數, 來達到不同的取值範圍.
取並集:
df = pd.merge(df1, df2, on='city', how='outer')
輸出: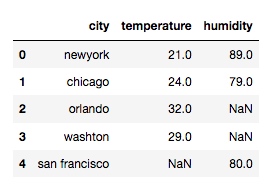
左對齊:
df = pd.merge(df1, df2, on='city', how='left')
輸出:
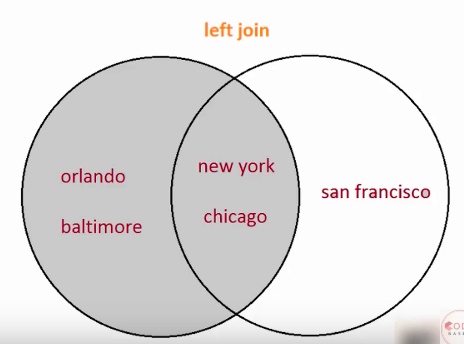
右對齊:
df = pd.merge(df1, df2, on='city', how='right')


另外, 在我們取並集的時候, 我們有時可能會想要知道, 某個數據是來自哪邊, 可以通過 indicator 參數來獲取:
df = pd.merge(df1, df2, on='city', how='outer', indicator=True)
輸出:
在上面的例子中, 被合併的數據的列名是沒有衝突的, 所以合併的很順利, 那麼如果兩組數據有相同的列名, 又會是什麼樣呢? 看下麵的例子:
df1 = pd.DataFrame({
'city': ['newyork', 'chicago', 'orlando', 'baltimore'],
'temperature': [21, 24, 32, 29],
'humidity': [89, 79, 80, 69],
})
df2 = pd.DataFrame({
'city': ['newyork', 'chicago', 'san francisco'],
'temperature': [30, 32, 28],
'humidity': [80, 60, 70],
})
df = pd.merge(df1, df2, on='city')
輸出:
我們發現, 相同的列名被自動加上了 'x', 'y' 作為區分, 為了更直觀地觀察數據, 我們也可以自定義這個區分的標誌:
df3 = pd.merge(df1, df2, on='city', suffixes=['_left', '_right'])
輸出:
好了, 以上, 就是關於 merge 合併的相關內容, enjoy~~~


