
我們知道一般圖書館都會建書目索引,可以提高數據檢索的效率,降低資料庫的IO成本。MySQL在300萬條記錄左右性能開始逐漸下降,雖然官方文檔說500~800w記錄,所以大數據量建立索引是非常有必要的。MySQL提供了Explain,用於顯示SQL執行的詳細信息,可以進行索引的優化。 一、導致SQL執 ...
我們知道一般圖書館都會建書目索引,可以提高數據檢索的效率,降低資料庫的IO成本。MySQL在300萬條記錄左右性能開始逐漸下降,雖然官方文檔說500~800w記錄,所以大數據量建立索引是非常有必要的。MySQL提供了Explain,用於顯示SQL執行的詳細信息,可以進行索引的優化。
一、導致SQL執行慢的原因:
1.硬體問題。如網路速度慢,記憶體不足,I/O吞吐量小,磁碟空間滿了等。
2.沒有索引或者索引失效。(一般在互聯網公司,DBA會在半夜把表鎖了,重新建立一遍索引,因為當你刪除某個數據的時候,索引的樹結構就不完整了。所以互聯網公司的數據做的是假刪除.一是為了做數據分析,二是為了不破壞索引 )
3.數據過多(分庫分表)
4.伺服器調優及各個參數設置(調整my.cnf)
二、分析原因時,一定要找切入點:
1.先觀察,開啟慢查詢日誌,設置相應的閾值(比如超過3秒就是慢SQL),在生產環境跑上個一天過後,看看哪些SQL比較慢。
2.Explain和慢SQL分析。比如SQL語句寫的爛,索引沒有或失效,關聯查詢太多(有時候是設計缺陷或者不得以的需求)等等。
3.Show Profile是比Explain更近一步的執行細節,可以查詢到執行每一個SQL都幹了什麼事,這些事分別花了多少秒。
4.找DBA或者運維對MySQL進行伺服器的參數調優。
三、什麼是索引?
MySQL官方對索引的定義為:索引(Index)是幫助MySQL高效獲取數據的數據結構。我們可以簡單理解為:快速查找排好序的一種數據結構。Mysql索引主要有兩種結構:B+Tree索引和Hash索引。我們平常所說的索引,如果沒有特別指明,一般都是指B樹結構組織的索引(B+Tree索引)。索引如圖所示:
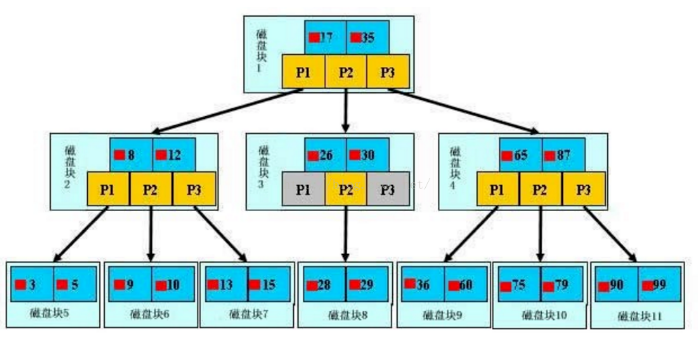
最外層淺藍色磁碟塊1里有數據17、35(深藍色)和指針P1、P2、P3(黃色)。P1指針表示小於17的磁碟塊,P2是在17-35之間,P3指向大於35的磁碟塊。真實數據存在於子葉節點也就是最底下的一層3、5、9、10、13......非葉子節點不存儲真實的數據,只存儲指引搜索方向的數據項,如17、35。
查找過程:例如搜索28數據項,首先載入磁碟塊1到記憶體中,發生一次I/O,用二分查找確定在P2指針。接著發現28在26和30之間,通過P2指針的地址載入磁碟塊3到記憶體,發生第二次I/O。用同樣的方式找到磁碟塊8,發生第三次I/O。
真實的情況是,上面3層的B+Tree可以表示上百萬的數據,上百萬的數據只發生了三次I/O而不是上百萬次I/O,時間提升是巨大的。
四、Explain分析
前文鋪墊完成,進入實操部分,先來插入測試需要的數據:
CREATE TABLE `user_info` ( `id` BIGINT(20) NOT NULL AUTO_INCREMENT, `name` VARCHAR(50) NOT NULL DEFAULT '', `age` INT(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `name_index` (`name`) )ENGINE = InnoDB DEFAULT CHARSET = utf8; INSERT INTO user_info (name, age) VALUES ('xys', 20); INSERT INTO user_info (name, age) VALUES ('a', 21); INSERT INTO user_info (name, age) VALUES ('b', 23); INSERT INTO user_info (name, age) VALUES ('c', 50); INSERT INTO user_info (name, age) VALUES ('d', 15); INSERT INTO user_info (name, age) VALUES ('e', 20); INSERT INTO user_info (name, age) VALUES ('f', 21); INSERT INTO user_info (name, age) VALUES ('g', 23); INSERT INTO user_info (name, age) VALUES ('h', 50); INSERT INTO user_info (name, age) VALUES ('i', 15); CREATE TABLE `order_info` ( `id` BIGINT(20) NOT NULL AUTO_INCREMENT, `user_id` BIGINT(20) DEFAULT NULL, `product_name` VARCHAR(50) NOT NULL DEFAULT '', `productor` VARCHAR(30) DEFAULT NULL, PRIMARY KEY (`id`), KEY `user_product_detail_index` (`user_id`, `product_name`, `productor`) )ENGINE = InnoDB DEFAULT CHARSET = utf8; INSERT INTO order_info (user_id, product_name, productor) VALUES (1, 'p1', 'WHH'); INSERT INTO order_info (user_id, product_name, productor) VALUES (1, 'p2', 'WL'); INSERT INTO order_info (user_id, product_name, productor) VALUES (1, 'p1', 'DX'); INSERT INTO order_info (user_id, product_name, productor) VALUES (2, 'p1', 'WHH'); INSERT INTO order_info (user_id, product_name, productor) VALUES (2, 'p5', 'WL'); INSERT INTO order_info (user_id, product_name, productor) VALUES (3, 'p3', 'MA'); INSERT INTO order_info (user_id, product_name, productor) VALUES (4, 'p1', 'WHH'); INSERT INTO order_info (user_id, product_name, productor) VALUES (6, 'p1', 'WHH'); INSERT INTO order_info (user_id, product_name, productor) VALUES (9, 'p8', 'TE');
初體驗,執行Explain的效果:

1.id
--id相同,執行順序由上而下 explain select u.*,o.* from user_info u,order_info o where u.id=o.user_id;

--id不同,值越大越先被執行 explain select * from user_info where id=(select user_id from order_info where product_name ='p8');

2.select_type
可以看id的執行實例,總共有以下幾種類型:
- SIMPLE: 表示此查詢不包含 UNION 查詢或子查詢
- PRIMARY: 表示此查詢是最外層的查詢
- SUBQUERY: 子查詢中的第一個 SELECT
- UNION: 表示此查詢是 UNION 的第二或隨後的查詢
- DEPENDENT UNION: UNION 中的第二個或後面的查詢語句, 取決於外面的查詢
- UNION RESULT, UNION 的結果
- DEPENDENT SUBQUERY: 子查詢中的第一個 SELECT, 取決於外面的查詢. 即子查詢依賴於外層查詢的結果.
- DERIVED:衍生,表示導出表的SELECT(FROM子句的子查詢)
3.table
table表示查詢涉及的表或衍生的表:
explain select tt.* from (select u.* from user_info u,order_info o where u.id=o.user_id and u.id=1) tt
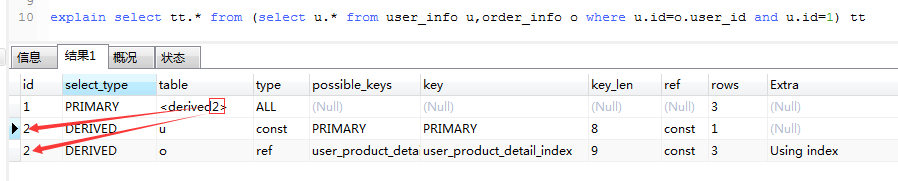
id為1的<derived2>的表示id為2的u和o表衍生出來的。
4.type
type 欄位比較重要,它提供了判斷查詢是否高效的重要依據依據。 通過 type 欄位,我們判斷此次查詢是 全表掃描 還是 索引掃描等。

type 常用的取值有:
- system: 表中只有一條數據, 這個類型是特殊的 const 類型。
- const: 針對主鍵或唯一索引的等值查詢掃描,最多只返回一行數據。 const 查詢速度非常快, 因為它僅僅讀取一次即可。例如下麵的這個查詢,它使用了主鍵索引,因此 type 就是 const 類型的:explain select * from user_info where id = 2;
- eq_ref: 此類型通常出現在多表的 join 查詢,表示對於前表的每一個結果,都只能匹配到後表的一行結果。並且查詢的比較操作通常是 =,查詢效率較高。例如:explain select * from user_info, order_info where user_info.id = order_info.user_id;
- ref: 此類型通常出現在多表的 join 查詢,針對於非唯一或非主鍵索引,或者是使用了 最左首碼 規則索引的查詢。例如下麵這個例子中, 就使用到了 ref 類型的查詢:explain select * from user_info, order_info where user_info.id = order_info.user_id AND order_info.user_id = 5
- range: 表示使用索引範圍查詢,通過索引欄位範圍獲取表中部分數據記錄。這個類型通常出現在 =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, IN() 操作中。例如下麵的例子就是一個範圍查詢:explain select * from user_info where id between 2 and 8;
- index: 表示全索引掃描(full index scan),和 ALL 類型類似,只不過 ALL 類型是全表掃描,而 index 類型則僅僅掃描所有的索引, 而不掃描數據。index 類型通常出現在:所要查詢的數據直接在索引樹中就可以獲取到, 而不需要掃描數據。當是這種情況時,Extra 欄位 會顯示 Using index。
- ALL: 表示全表掃描,這個類型的查詢是性能最差的查詢之一。通常來說, 我們的查詢不應該出現 ALL 類型的查詢,因為這樣的查詢在數據量大的情況下,對資料庫的性能是巨大的災難。 如一個查詢是 ALL 類型查詢, 那麼一般來說可以對相應的欄位添加索引來避免。
通常來說, 不同的 type 類型的性能關係如下:
ALL < index < range ~ index_merge < ref < eq_ref < const < system
ALL 類型因為是全表掃描, 因此在相同的查詢條件下,它是速度最慢的。而 index 類型的查詢雖然不是全表掃描,但是它掃描了所有的索引,因此比 ALL 類型的稍快.後面的幾種類型都是利用了索引來查詢數據,因此可以過濾部分或大部分數據,因此查詢效率就比較高了。
5.possible_keys
它表示 mysql 在查詢時,可能使用到的索引。 註意,即使有些索引在 possible_keys 中出現,但是並不表示此索引會真正地被 mysql 使用到。 mysql 在查詢時具體使用了哪些索引,由 key 欄位決定。
6.key
此欄位是 mysql 在當前查詢時所真正使用到的索引。比如請客吃飯,possible_keys是應到多少人,key是實到多少人。當我們沒有建立索引時:
explain select o.* from order_info o where o.product_name= 'p1' and o.productor='whh'; create index idx_name_productor on order_info(productor); drop index idx_name_productor on order_info;

建立複合索引後再查詢:

7.key_len
表示查詢優化器使用了索引的位元組數,這個欄位可以評估組合索引是否完全被使用。
8.ref
這個表示顯示索引的哪一列被使用了,如果可能的話,是一個常量。前文的type屬性里也有ref,註意區別。

9.rows
rows 也是一個重要的欄位,mysql 查詢優化器根據統計信息,估算 sql 要查找到結果集需要掃描讀取的數據行數,這個值非常直觀的顯示 sql 效率好壞, 原則上 rows 越少越好。可以對比key中的例子,一個沒建立索引錢,rows是9,建立索引後,rows是4。
10.extra

explain 中的很多額外的信息會在 extra 欄位顯示, 常見的有以下幾種內容:
- using filesort :表示 mysql 需額外的排序操作,不能通過索引順序達到排序效果。一般有 using filesort都建議優化去掉,因為這樣的查詢 cpu 資源消耗大。
- using index:覆蓋索引掃描,表示查詢在索引樹中就可查找所需數據,不用掃描表數據文件,往往說明性能不錯。
- using temporary:查詢有使用臨時表, 一般出現於排序, 分組和多表 join 的情況, 查詢效率不高,建議優化。
- using where :表名使用了where過濾。
五、優化案例
explain select u.*,o.* from user_info u LEFT JOIN order_info o on u.id=o.user_id;
執行結果,type有ALL,並且沒有索引:

開始優化,在關聯列上創建索引,明顯看到type列的ALL變成ref,並且用到了索引,rows也從掃描9行變成了1行:
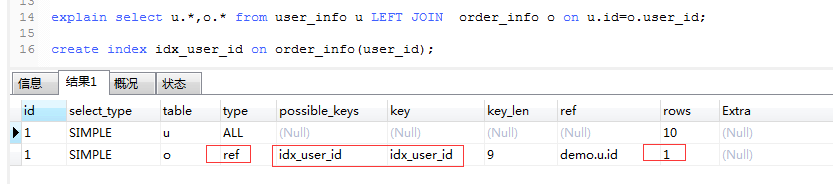
這裡面一般有個規律是:左鏈接索引加在右表上面,右鏈接索引加在左表上面。
六、是否需要創建索引?
索引雖然能非常高效的提高查詢速度,同時卻會降低更新表的速度。實際上索引也是一張表,該表保存了主鍵與索引欄位,並指向實體表的記錄,所以索引列也是要占用空間的。



