
本文將講解String的幾個性質。 一、String的不可變性 對於初學者來說,很容易誤認為String對象是可以改變的,特別是+鏈接時,對象似乎真的改變了。然而,String對象一經創建就不可以修改。接下來,我們一步步 分析String是怎麼維護其不可改變的性質; 1. 手段一:final類 和 ...
本文將講解String的幾個性質。
一、String的不可變性
對於初學者來說,很容易誤認為String對象是可以改變的,特別是+鏈接時,對象似乎真的改變了。然而,String對象一經創建就不可以修改。接下來,我們一步步 分析String是怎麼維護其不可改變的性質;
1. 手段一:final類 和 final的私有成員
我們先看一下String的部分源碼:
1 public final class String 2 implements java.io.Serializable, Comparable<String>, CharSequence { 3 /** The value is used for character storage. */ 4 private final char value[]; 5 /** Cache the hash code for the string */ 6 private int hash; // Default to 0 7 /** use serialVersionUID from JDK 1.0.2 for interoperability */ 8 private static final long serialVersionUID = -6849794470754667710L; 9 }
我們可以發現 String是一個final類,且3個成員都是私有的,這就意味著String是不能被繼承的,這就防止出現:程式員通過繼承重寫String類的方法的手段來使得String類是“可變的”的情況。
從源碼發現,每個String對象維護著一個char數組 —— 私有成員value。數組value 是String的底層數組,用於存儲字元串的內容,而且是 private final ,但是數組是引用類型,所以只能限制引用不改變而已,也就是說數組元素的值是可以改變的,而且String 有一個可以傳入數組的構造方法,那麼我們可不可以通過修改外部char數組元素的方式來“修改”String 的內容呢?
我們來做一個實驗,如下:
1 public static void main(String[] args) { 2 char[] arr = new char[]{'a','b','c','d'}; 3 String str = new String(arr); 4 arr[3]='e'; 5 System.out.println("str= "+str); 6 System.out.println("arr[]= "+Arrays.toString(arr)); 7 }
運行結果
1 str= abcd 2 arr[]= [a, b, c, e]
結果與我們所想不一樣。字元串str使用數組arr來構造一個對象,當數組arr修改其元素值後,字元串str並沒有跟著改變。那就看一下這個構造方法是怎麼處理的:
1 public String(char value[]) { 2 this.value = Arrays.copyOf(value, value.length); 3 }
原來 String在使用外部char數組構造對象時,是重新複製了一份外部char數組,從而不會讓外部char數組的改變影響到String對象。
2. 手段二:改變即創建對象的方法
從上面的分析我們知道,我們是無法從外部修改String對象的,那麼可不可能使用String提供的方法,因為有不少方法看起來是可以改變String對象的,如replace()、replaceAll()、substring()等。我們以substring()為例,看一下源碼:
1 public String substring(int beginIndex, int endIndex) { 2 //........ 3 return ((beginIndex == 0) && (endIndex == value.length)) ? this 4 : new String(value, beginIndex, subLen); 5 }
從源碼可以看出,如果不是切割整個字元串的話,就會新建一個對象。也就是說,只要與原字元串不相等,就會新建一個String對象。
緩存Hashcode
Java中經常會用到字元串的哈希碼(hashcode)。例如,在HashMap中,字元串的不可變能保證其hashcode永遠保持一致,這樣就可以避免一些不必要的麻煩。這也就意味著每次在使用一個字元串的hashcode的時候不用重新計算一次,這樣更加高效。
在String類中,有以下代碼:
1 private int hash;//this is used to cache hash code.
以上代碼中hash變數中就保存了一個String對象的hashcode,因為String類不可變,所以一旦對象被創建,該hash值也無法改變。所以,每次想要使用該對象的hashcode的時候,直接返回即可。
二、字元串拼接
其實,所有的所謂字元串拼接,都是重新生成了一個新的字元串。下麵一段字元串拼接代碼:
1 String s = "abcd"; 2 s = s.concat("ef");
其實最後我們得到的s已經是一個新的字元串了。如下圖
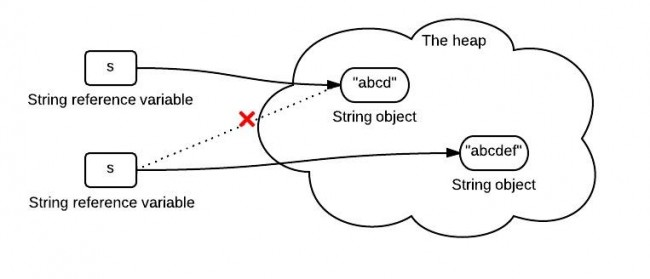
s中保存的是一個重新創建出來的String對象的引用.
那麼,在Java中,到底如何進行字元串拼接呢?字元串拼接有很多種方式,這裡簡單介紹幾種比較常用的
1、使用 + 拼接字元串
我們先來看一個例子:
1 public class MyTest { 2 public static void main(String[] args) { 3 String s = "Love You"; 4 String s2 = "Love"+" You"; 5 String s3 = s2 + ""; 6 String s4 = new String("Love You"); 7 System.out.println("s == s2 "+(s==s2)); 8 System.out.println("s == s3 "+(s==s3)); 9 System.out.println("s == s4 "+(s==s4)); 10 } 11 }
運行結果:
1 s == s2 true 2 s == s3 false 3 s == s4 false
是不是對運行結果感覺很不解。別急,我們來慢慢理清楚。首先,我們要知道編譯器有個優點:在編譯期間會儘可能地優化代碼,所以能由編譯器完成的計算,就不會等到運行時計算,如常量表達式的計算就是在編譯期間完成的。所以,s2 的結果其實在編譯期間就已經計算出來了,與 s 的值是一樣,所以兩者相等,即都屬於字面常量,在類載入時創建並維護在字元串常量池中。但 s3 的表達式中含有變數 s2 ,只能是運行時才能執行計算,也就是說,在運行時才計算結果,在堆中創建對象,自然與 s 不相等。而 s4 使用new直接在堆中創建對象,更不可能相等。
那在運行期間,是如何完成String的+號鏈接操作的呢,要知道String對象可是不可改變的對象。我們反編譯上面例子的calss文件,來看看究竟是怎麼實現的:
1 public class MyTest 2 { 3 public MyTest() 4 { 5 } 6 public static void main(String args[]) 7 { 8 String s = "Love You"; 9 String s2 = "Love You";//已經得到計算結果 10 String s3 = (new StringBuilder(String.valueOf(s2))).toString(); 11 String s4 = new String("Love You"); 12 System.out.println((new StringBuilder("s == s2 ")).append(s == s2).toString()); 13 System.out.println((new StringBuilder("s == s3 ")).append(s == s3).toString()); 14 System.out.println((new StringBuilder("s == s4 ")).append(s == s4).toString()); 15 } 16 }
可以看出,編譯器將 + 號處理成了StringBuilder.append()方法。也就是說,在運行期間,鏈接字元串的計算都是通過 創建StringBuilder對象,調用append()方法來完成的。
2、concat
除了使用+拼接字元串之外,還可以使用String類中的方法concat方法來拼接字元串。如:
1 String wechat = "ChenHao"; 2 String introduce = "每日更新Java相關技術文章"; 3 String hollis = wechat.concat(",").concat(introduce);
我們再來看一下concat方法的源代碼,看一下這個方法又是如何實現的。
1 public String concat(String str) { 2 int otherLen = str.length(); 3 if (otherLen == 0) { 4 return this; 5 } 6 int len = value.length; 7 char buf[] = Arrays.copyOf(value, len + otherLen); 8 str.getChars(buf, len); 9 return new String(buf, true); 10 }
這段代碼首先創建了一個字元數組,長度是已有字元串和待拼接字元串的長度之和,再把兩個字元串的值複製到新的字元數組中,並使用這個字元數組創建一個新的String對象並返回。
通過源碼我們也可以看到,經過concat方法,其實是new了一個新的String,這也就呼應到前面我們說的字元串的不變性問題上了。
三、StringBuffer和StringBuilder
接下來我們看看StringBuffer和StringBuilder的實現原理。和String類類似,StringBuilder類也封裝了一個字元數組,定義如下:
1 char[] value;
與String不同的是,它並不是final的,所以他是可以修改的。另外,與String不同,字元數組中不一定所有位置都已經被使用,它有一個實例變數,表示數組中已經使用的字元個數,定義如下:
1 int count;
其append源碼如下:
1 public StringBuilder append(String str) { 2 super.append(str); 3 return this; 4 }
該類繼承了AbstractStringBuilder類,看下其append方法:
1 public AbstractStringBuilder append(String str) { 2 if (str == null) 3 return appendNull(); 4 int len = str.length(); 5 ensureCapacityInternal(count + len); 6 str.getChars(0, len, value, count); 7 count += len; 8 return this; 9 }
append會直接拷貝字元到內部的字元數組中,如果字元數組長度不夠,會進行擴展。
StringBuffer和StringBuilder類似,最大的區別就是StringBuffer是線程安全的,看一下StringBuffer的append方法。
1 public synchronized StringBuffer append(String str) { 2 toStringCache = null; 3 super.append(str); 4 return this; 5 }
該方法使用synchronized進行聲明,說明是一個線程安全的方法。而StringBuilder則不是線程安全的。
效率比較
既然有這麼多種字元串拼接的方法,那麼到底哪一種效率最高呢?我們來簡單對比一下。
1 long t1 = System.currentTimeMillis(); 2 String str = "chenhao"; 3 //StringBuffer str = new StringBuffer("chenhao"); 4 for (int i = 0; i < 50000; i++) { 5 String s = String.valueOf(i); 6 str += s; 7 //str=str.concat(s); 8 //str.append(s); 9 } 10 long t2 = System.currentTimeMillis(); 11 System.out.println("+ cost:" + (t2 - t1));
我們使用形如以上形式的代碼,分別測試下五種字元串拼接代碼的運行時間。得到結果如下:
1 + cost:5119 2 StringBuilder cost:3 3 StringBuffer cost:4 4 concat cost:3623
從結果可以看出,用時從短到長的對比是:
StringBuilder < StringBuffer < concat < + < StringUtils.join
StringBuffer在StringBuilder的基礎上,做了同步處理,所以在耗時上會相對多一些,這個很好理解。
那麼問題來了,前面我們分析過,其實使用+拼接字元串的實現原理也是使用的StringBuilder,那為什麼結果相差這麼多,高達1000多倍呢?
我們再把以下代碼反編譯下:
1 long t1 = System.currentTimeMillis(); 2 String str = "chenhao"; 3 for (int i = 0; i < 50000; i++) { 4 String s = String.valueOf(i); 5 str += s; 6 } 7 long t2 = System.currentTimeMillis(); 8 System.out.println("+ cost:" + (t2 - t1));
反編譯後代碼如下:
1 long t1 = System.currentTimeMillis(); 2 String str = "chenhao"; 3 for(int i = 0; i < 50000; i++) 4 { 5 String s = String.valueOf(i); 6 str = (new StringBuilder()).append(str).append(s).toString(); 7 } 8 9 long t2 = System.currentTimeMillis(); 10 System.out.println((new StringBuilder()).append("+ cost:").append(t2 - t1).toString());
我們可以看到,反編譯後的代碼,在for迴圈中,每次都是new了一個StringBuilder,然後再把String轉成StringBuilder,再進行append。
而頻繁的新建對象當然要耗費很多時間了,不僅僅會耗費時間,頻繁的創建對象,還會造成記憶體資源的浪費。
所以:迴圈體內,字元串的連接方式,使用StringBuilder 的 append 方法進行擴展。而不要使用+。
推薦博客
https://www.cnblogs.com/chen-haozi/p/10227797.html
總結
本文介紹了什麼是字元串拼接,雖然字元串是不可變的,但是還是可以通過新建字元串的方式來進行字元串的拼接。
常用的字元串拼接方式有五種,分別是使用+、使用concat、使用StringBuilder、使用StringBuffer以及使用StringUtils.join。
由於字元串拼接過程中會創建新的對象,所以如果要在一個迴圈體中進行字元串拼接,就要考慮記憶體問題和效率問題。
因此,經過對比,我們發現,直接使用StringBuilder的方式是效率最高的。因為StringBuilder天生就是設計來定義可變字元串和字元串的變化操作的。
但是,還要強調的是:
1、如果不是在迴圈體中進行字元串拼接的話,直接使用+就好了。
2、如果在併發場景中進行字元串拼接的話,要使用StringBuffer來代替StringBuilder。


