
本著做題的心態,上了東莞理工學院的 oj 網;看了一下題目不想動手,在選擇難度的時候發現有些通過率和難度可能存在著某些關係,於是決定爬下這些數據簡單查看一下是否存在關係。 一、新建項目 我是用 Scrapy 框架爬取的(因為剛學沒多久,順便練練手)。首先,先新建 project (下載 Scarpy ...
本著做題的心態,上了東莞理工學院的 oj 網;看了一下題目不想動手,在選擇難度的時候發現有些題目通過率和難度可能存在著某些關係,於是決定爬下這些數據簡單查看一下是否存在關係。
一、新建項目
我是用 Scrapy 框架爬取的(因為剛學沒多久,順便練練手)。首先,先新建 project (下載 Scarpy 部分已省略),在控制台輸入 scrapy startproject onlineJudge(其中, onlineJudge為項目名稱),敲擊回車鍵新建項目完成。
二、明確目的
在動手寫代碼之前,先分析一下網頁結構。網站是通過動態載入的,數據通過 json 文件載入。

1、明確要爬取的目標: http://oj.dgut.edu.cn/problems 網站里的題目,難度,提交量,通過率。在查找 json 的時候發現只有通過數,那麼通過率就要自己計算。
2、打開 onlineJudge 目錄下的 items.py 寫下如下代碼:
class OnlinejudgeItem(scrapy.Item): id = scrapy.Field() # 題目編號 title = scrapy.Field() # 標題 difficulty = scrapy.Field() # 難度 submissionNo = scrapy.Field() # 提交量 acceptedNo = scrapy.Field() # 正確數 passingRate = scrapy.Field() # 正確率
三、製作爬蟲
1、在當前目錄下輸入命令:scrapy genspider oj "oj.dgut.edu.cn" (其中 oj 是爬蟲的名字,"oj.dgut.edu.cn"算是一個約束,規定一個功能變數名稱)
2、打開 onlineJudge/spiders 下的 ojSpider.py ,增加或修改代碼為:
import scrapy import json from onlineJudge.items import OnlinejudgeItem class OjSpider(scrapy.Spider): name = 'oj' # 爬蟲的名字 allowed_domains = ['oj.dgut.edu.cn'] # 功能變數名稱範圍 offset = 0 url = 'http://oj.dgut.edu.cn/api/xproblem/?limit=20&offset=' start_urls = [url + str(offset)] # 爬取的URL元祖/列表 def parse(self, response): data = json.loads(response.text)['data']['results'] if len(data): for i in range(len(data)): submissionNo = data[i]['submission_number'] acceptedNo = data[i]['accepted_number'] try: passingRate = round((int(acceptedNo)/int(submissionNo)) * 100, 2) except ZeroDivisionError as e: passingRate = 0 strPR = str(passingRate) + "%" item = OnlinejudgeItem() item['id'] = data[i]['_id'] item['title'] = data[i]['title'] item['difficulty'] = data[i]['difficulty'] item['submissionNo'] = submissionNo item['acceptedNo'] = acceptedNo item['passingRate'] = strPR yield item print(i) self.offset += 20 yield scrapy.Request(self.url + str(self.offset), callback=self.parse)
四、存儲數據
1、打算將數據存儲為 excel 文檔,要先安裝 openpyxl 模塊,通過 pip install openpyxl 下載。
2、下載完成後,在 pipelines.py 中寫入如下代碼
from openpyxl import Workbook class OnlinejudgePipeline(object): def __init__(self): self.wb = Workbook() self.ws = self.wb.active # 激活工作簿 self.ws.append(['編號', '標題', '難度', '提交量', '正確數', '正確率']) # 設置表頭 def process_item(self, item, spider): line = [item['id'], item['title'], item['difficulty'], item['submissionNo'], item['acceptedNo'], item['passingRate']] self.ws.append(line) self.wb.save('oj.xlsx') return item
五、設置 settings.py
修改並增加代碼:
LOG_FILE = "oj.log" ROBOTSTXT_OBEY = True ITEM_PIPELINES = { 'onlineJudge.pipelines.OnlinejudgePipeline': 300, }
六、運行爬蟲
在當前目錄下新建一個 main.py 並寫下如下代碼
from scrapy import cmdline cmdline.execute("scrapy crawl oj".split())
然後運行 main.py 文件。
於是,想要的數據就被爬下來了

七、分析數據
分析數據之前,先安裝好 numpy,pandas,matplotlib,xlrd。
import pandas as pd import xlrd data = pd.read_excel("../onlineJudge/onlineJudge/oj.xlsx") # 導入 excel 文件 data.describe()
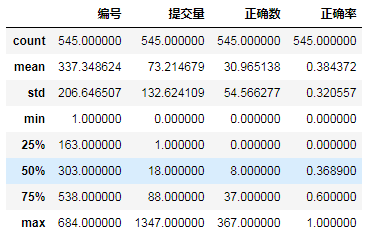
data = data.set_index('編號') # 設置編號為索引
data.head() # 顯示前五條信息

from matplotlib import pyplot as plt import matplotlib.style as psl %matplotlib inline psl.use('seaborn-colorblind') # 設置圖表風格 plt.rcParams['font.sans-serif']=['SimHei'] #用來正常顯示中文標簽
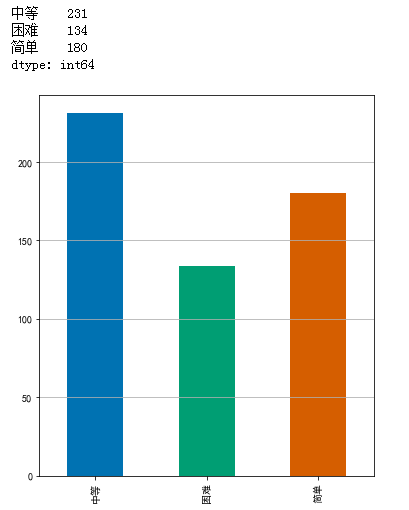
查看題目各難度的數目:
level_values = data['難度'].values difficulties = { '簡單': 0, '中等': 0, '困難': 0 } for value in level_values: if value == '簡單': difficulties['簡單'] += 1 elif value == '中等': difficulties['中等'] += 1 else: difficulties['困難'] += 1 level = pd.Series(difficulties) print(level) level.plot(kind = 'bar', figsize=(6, 7)) plt.grid(axis='y')
驗證正確率與難度之間是否存在關係:
import numpy as np relation = data[['難度', '正確率']] rate_values = relation['正確率'].values fig, axes = plt.subplots(figsize=(15, 6)) axes.scatter(rate_values, level_values) plt.grid(axis='x') plt.xticks(np.arange(0, 1, 0.05)) plt.xlabel('正確率') plt.ylabel('難度')
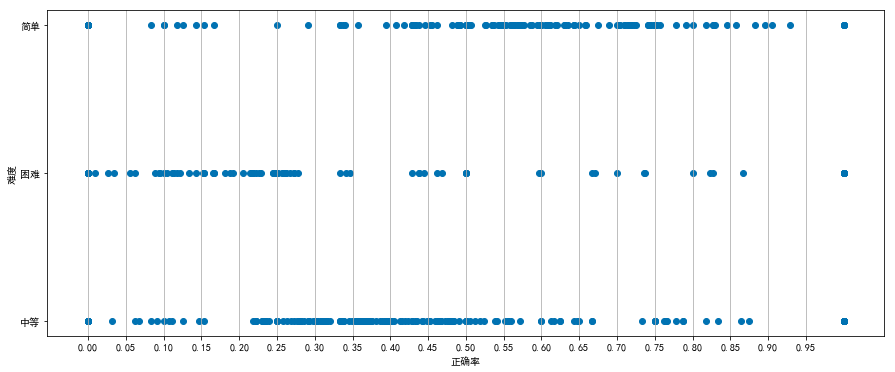
根據表格顯示,題目難度跟正確率是存在一定關係的(我想的沒有錯哈哈哈)。


