背景:併發知識是一個程式員段位升級的體現,同樣也是進入BAT的必經之路,有必要把併發知識重新梳理一遍。 ConcurrentHashMap:在有了併發的基礎知識以後,再來研究concurrent包。普通的HashMap為非線程安全的,在高併發場景下要使用線程安全版本的ConcurrentHashMa ...
背景:併發知識是一個程式員段位升級的體現,同樣也是進入BAT的必經之路,有必要把併發知識重新梳理一遍。
ConcurrentHashMap:
在有了併發的基礎知識以後,再來研究concurrent包。普通的HashMap為非線程安全的,在高併發場景下要使用線程安全版本的ConcurrentHashMap;
眾所周知HashTable可以保證線程安全但卻效率低下,而HashMap是非線程安全但效率卻高於HashTable,於是ConcurrentHashMap就孕育而生成為二者的結合體,為了更好的理解ConcurrentHashMap先看下這兩個Map。
HashMap:
HashMap之所以具有很快的訪問速度,因為它是根據鍵的hashCode值來存儲數據,在大多數情況下可以直接定位到它的值,但遍歷的順序是不確定的;HashMap的key可以為null,但是最多只允許一條記錄的鍵為null,另外允許多條記錄(value)的值為null,key為null的鍵值對永遠都放在一table[0]為頭節點的鏈表中;HashMap為非線程安全的,適用於單線程環境下,即在任一時刻都可以有多個線程同時對HashMap進行讀或寫操作,可以會導致數據的不一致;如果一定要使用HashMap又要保證線程安全,則可以用Collection的synchronizedMap方法或ConcurrentHashMap都OK;HashMap是基於哈希實表實現的,每一個元素是一個key-value對,其內部通過單鏈表結局衝突問題的,當Map容量不足(超過了閥值)時鏈表會自動增長;HashMap實現了Serializable介面,因此其支持序列化,並且實現了Cloneable介面,可以被克隆;
HashMap存儲數據的過程:
HashMap內部維護了一個存儲數據的Entry數組,HashMap採用鏈表解決衝突,每一個Entry本質上其實是一個單向鏈表;當要添加一個key-value對時,首先會通過hash(key)方法技術hash值,然後通過indexFor(hash,length)求該key-value對的存儲位置,其計算方法是先用Hash&0x7FFFFFFF後,再對length取模,這就保證了每一個key-value對都能存入HashMap,當計算出相同的位置是,由於存入位置是一個鏈表,所以把這個key-value對插入鏈表頭。
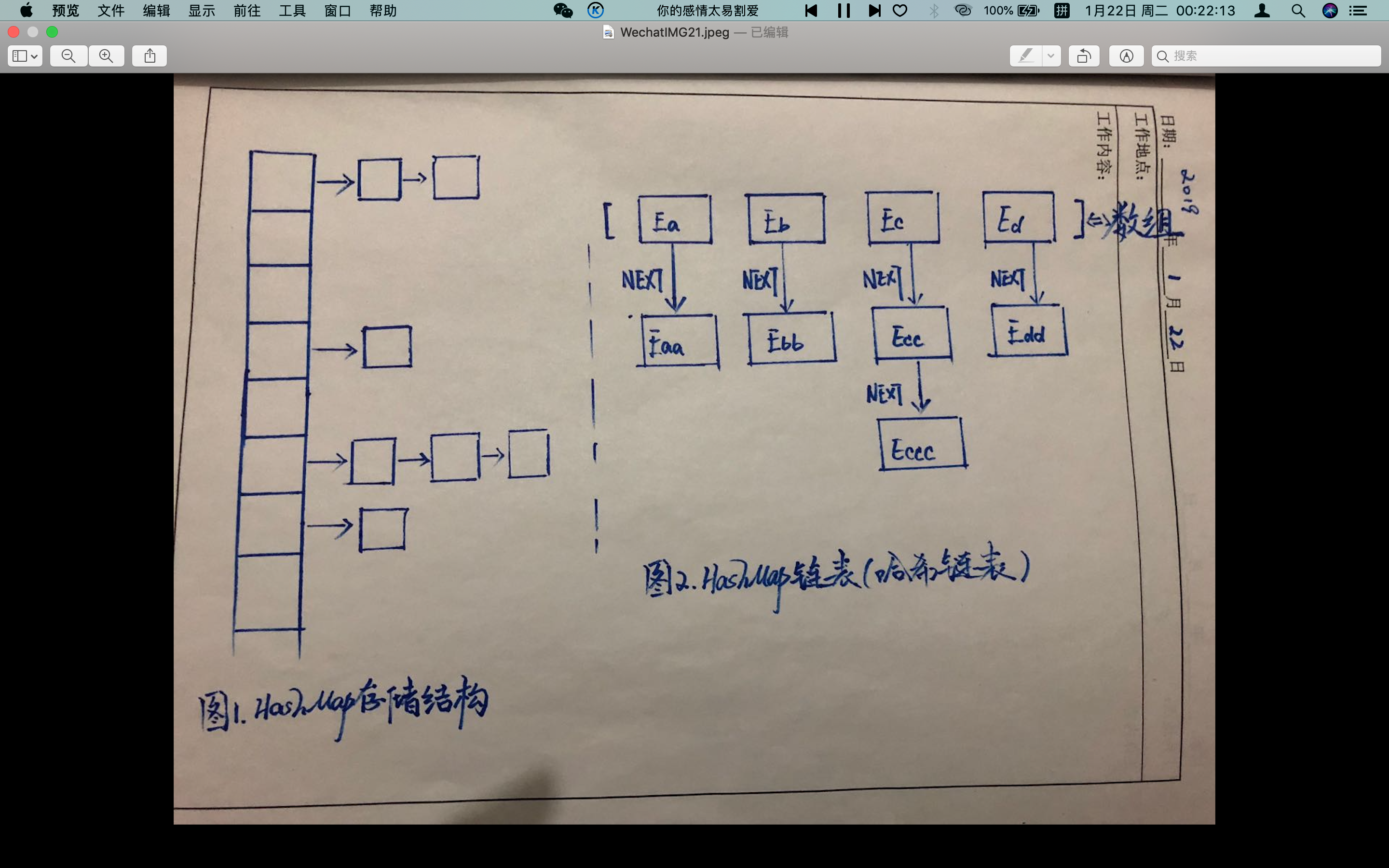
如上圖1 所示,最左邊豎列排的多個方格就代表哈希表,也叫哈希數組,數組的每個元素都是一個單鏈表的頭節點,鏈表是用來解決衝突的,如果不同的key映射到了數組的同一位置處,就將其放入單鏈表中;HashMap記憶體儲數據的Entry數組預設是16,如果沒有對Entry擴容機制的話,當存儲的數據一多,Entry內部的鏈表會很長,這就失去了HashMap的存儲意義了,所以HasnMap內部有自己的擴容機制(當size大於threshold時,對HashMap進行擴容)。 上圖2 是HashMap的鏈表存儲結構,其中E*代表一個Node節點,每個Node節點就對應著一個key-value的mapping映射;每個Node除了保存了key和value的映射之外,還保存了它下一Node的引用(Eb保存了Ebb的引用,而Ebb保存了Ebbb的引用);圖2中,每一個鏈表如Ec-->Ecc-->Eccc,這三個節點的key是不相等的。
分析HashMap源碼會發現其內部有幾個重要的變數如:size用於記錄HashMap的底層數組中已用槽的數量、threshold用於HashMap的閾值判斷,看是否需要調整HashMap的容量(threshold = 容量*載入因數)、DEFAULT_LOAD_FACTOR = 0.75f,即載入因數預設0.75。 HashMap的擴容是是新建了一個HashMap的底層數組,通過調用transfer方法,將就HashMap的全部元素添加到新的HashMap中(此步需要重新計算元素在新的數組中的索引位置,導致HashMap擴容成為一個相當耗時的操作),So我們在用HashMap的時,最好能提前預估下HashMap中元素的個數,這樣有助於提高HashMap的性能。
HashTable:
HashMap的功能與HashMap類似,如同樣是基於哈希表實現的、內部也是通過單鏈表解決衝突問題、容量不足時也會自動增加、同樣實現了Seriablizable介面支持序列化、實現了Cloneable介面可克隆;不同的是HashTable繼承自Dictionary類且為線程安全的(任一時間只有一個線程可以寫HashTable,但性能不如
ConcurrentHashMap),而HashMap繼承AbstractMap類且非線程安全。
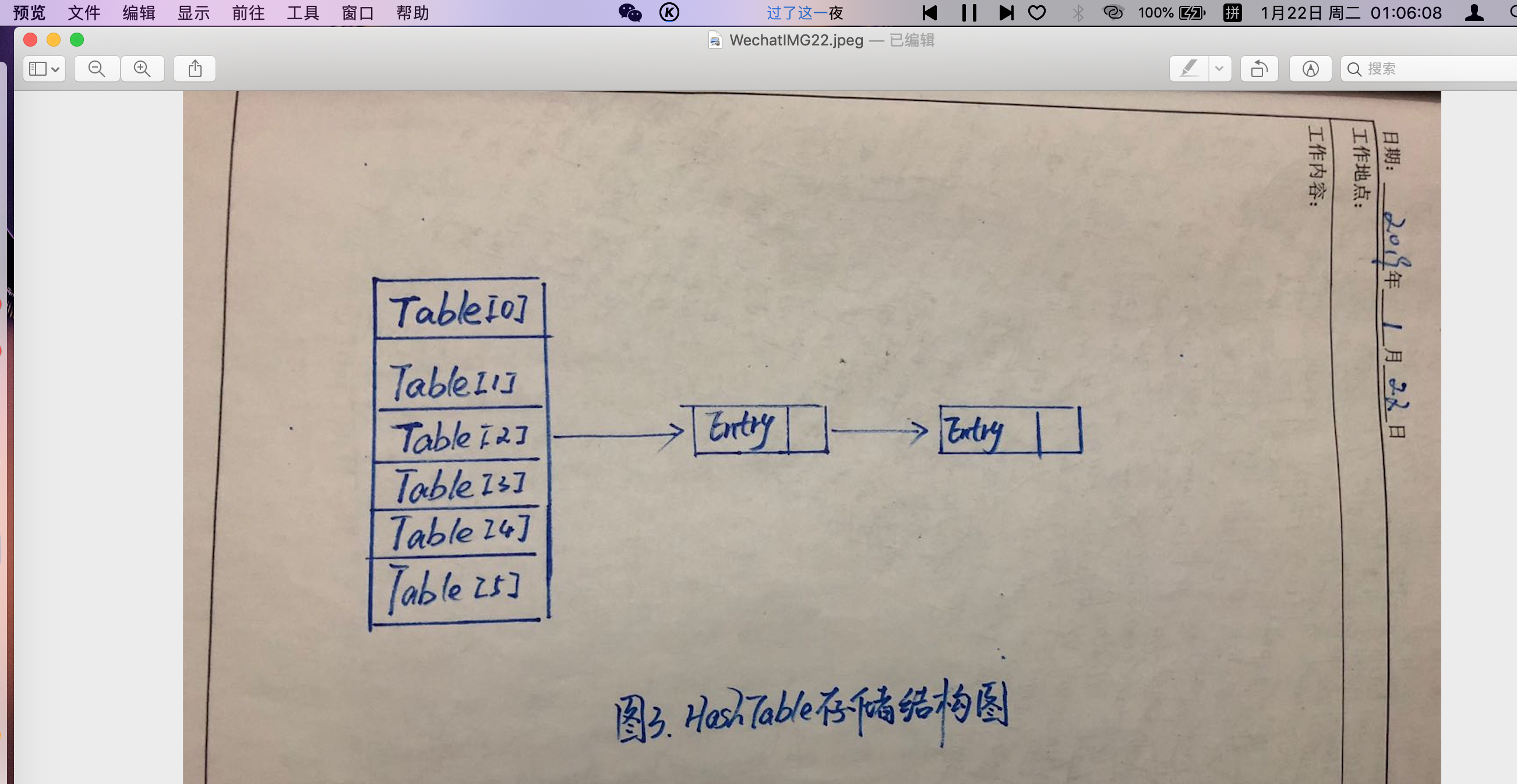
如圖3,HashTable只有一把鎖,當一個線程訪問HashTable的同步方法時,會將整張table 鎖住,當其他線程也想訪問HashTable 同步方法時,就會進入阻塞或輪詢狀態。也就是確保同一時間只有一個線程對同步方法的占用,避免多個線程同時對數據的修改,由此確保線程的安全性;但HashTable 對get,put,remove 方法都使用了同步操作,這就造成如果兩個線程都只想使用get 方法去讀取數據時,因為一個線程先到進行了鎖操作,另一個線程就不得不等待,這樣必然導致效率低下,而且競爭越激烈,效率越低下。
ConcurrentHashMap(併發且線程安全):
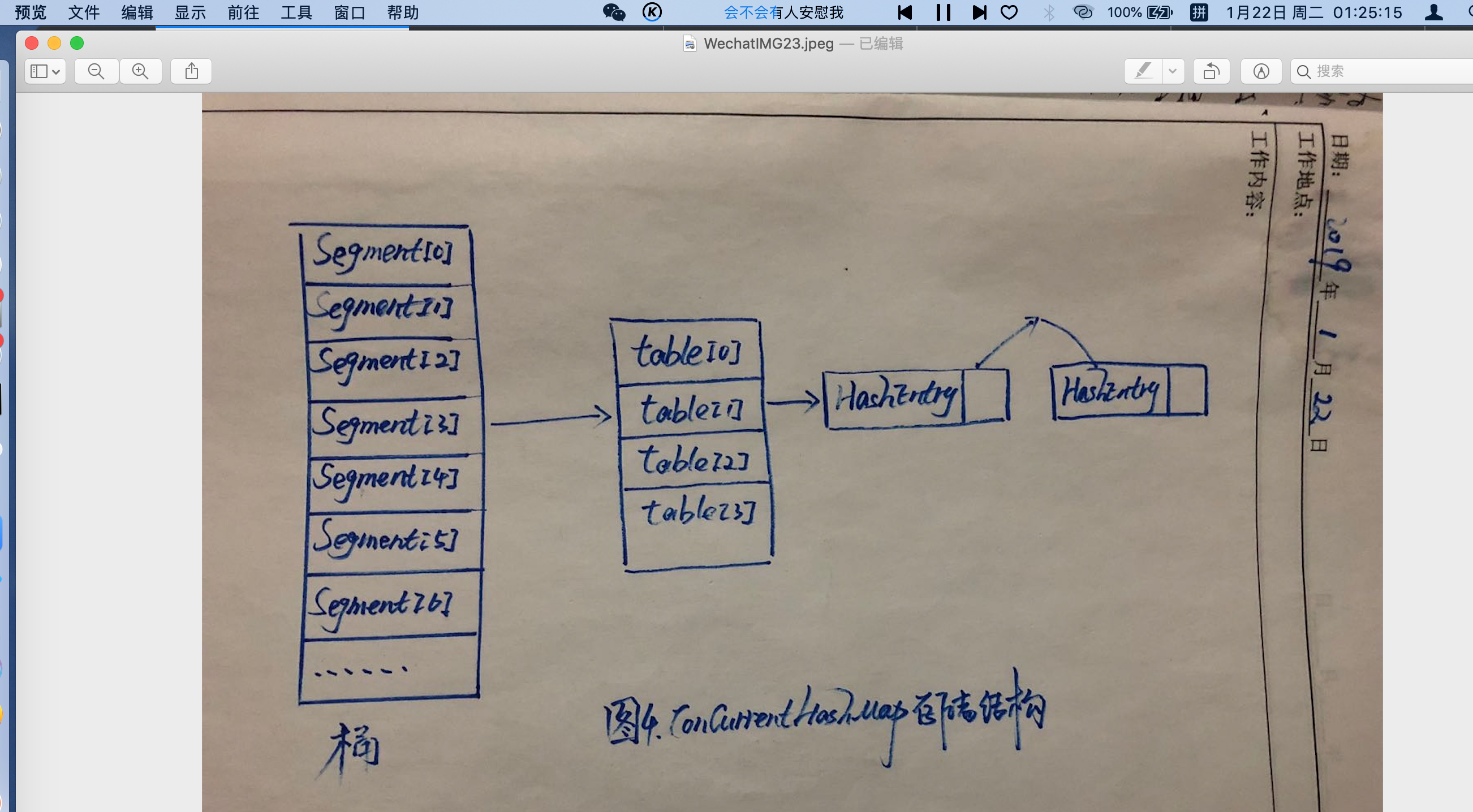
ConcourrentHashMap是通過分段鎖技術來保證線程安全的[case:一個人到酒店開房可直接在前臺辦理入住,三個陌生人到酒店開房登記入住,另外兩個則要先排隊等第一個辦理結束(普通的Map),要是三個人所住的每個樓層都有一個可以辦理入住的前臺就無需排隊了(ConcurrentHashMap)];ConcurrentHashMap主要由Segment(桶)和HashEntry(節點)兩大數據組成,如下圖: