
某備份系統大量使用rsync來傳輸文件,但是偶爾會出現rsync客戶端在上傳數據的時候長時間卡死,本文記錄瞭解決問題的步驟。 本文只涉及rsync客戶端中IO相關邏輯,關於rsync的發送演算法並不涉及,服務端邏輯略有提到。 ...
簡介
某備份系統大量使用rsync來傳輸文件,但是偶爾會出現rsync客戶端在上傳數據的時候長時間卡死,本文記錄瞭解決問題的步驟。
本文只涉及rsync客戶端中IO相關邏輯,關於rsync的發送演算法並不涉及,服務端邏輯略有提到。
故障現象
rsync客戶端一直駐留記憶體,strace跟蹤rsync客戶端進程發現:
# strace -p 22819
Process 22819 attached - interrupt to quit
select(4, [3], [], NULL, {57, 106010}) = 0 (Timeout)
select(4, [3], [], NULL, {60, 0}) = 0 (Timeout)
select(4, [3], [], NULL, {60, 0}) = 0 (Timeout)
select(4, [3], [], NULL, {60, 0}) = 0 (Timeout)
select(4, [3], [], NULL, {60, 0}) = 0 (Timeout)
select(4, [3], [], NULL, {60, 0}) = 0 (Timeout)
select(4, [3], [], NULL, {60, 0}) = 0 (Timeout)故障原因查詢
- 因為rsync在編譯時沒有把代碼信息編譯進去(也就是沒有加上
-g選項),所以gdb也無法跟蹤具體的調用堆棧。 - 但是從上面的跟蹤可以看出,進程一直在等待fd=3的讀取事件,每次都是超時(預設60秒)。
- ok,先查查這個fd=3是什麼:
# ll /proc/22819/fd
total 0
lr-x------ 1 root root 64 Jan 4 19:24 0 -> /dev/null
l-wx------ 1 root root 64 Jan 4 19:24 1 -> pipe:[1247832664]
l-wx------ 1 root root 64 Jan 4 19:24 2 -> pipe:[1247832664]
lrwx------ 1 root root 64 Jan 4 19:24 3 -> socket:[1247890095]- 可見fd=3是一個socket,查看這個socket的源地址和目標地址:
# grep 1247890095 /proc/net/tcp
13: 3EA8010A:4CC5 3D21010A:22A9 01 00000000:00000000 00:00000000 00000000 0 0 1247890095 1 ffff8808772ae940 23 3 24 3 7 - 源地址【3EA8010A:4CC5】,轉換成十進位就是【10.1.168.62:19653】,也就是本機地址;目標地址【3D21010A:22A9】,轉換成十進位就是【10.1.33.61:8873】。至於如何轉換不再贅述,參考UNP中關於數據的主機順序和網路順序的論述。
- 連接目標機器10.1.33.61,發現這台機器上根本沒有與【10.1.168.62:19653】的連接,也就是服務端連接已經關閉。
- 因此,上述故障原因已經查明:服務端關閉連接,但是客戶端仍在重試等待來自服務端的讀取信息。預設的60秒只是select的超時時間,但是如果沒有指定連接的超時時間,那麼客戶端會一直死等(沒有keep alive等等,根據rsync 3.0.6代碼)。
Talk is cheap,show me your code
基於極客精神,我有興趣查看源代碼,看看rsync為什麼會犯這種錯誤。代碼為rsync 3.0.6,使用工具查看,可以得到調用關係(圖有點大,點開看)。
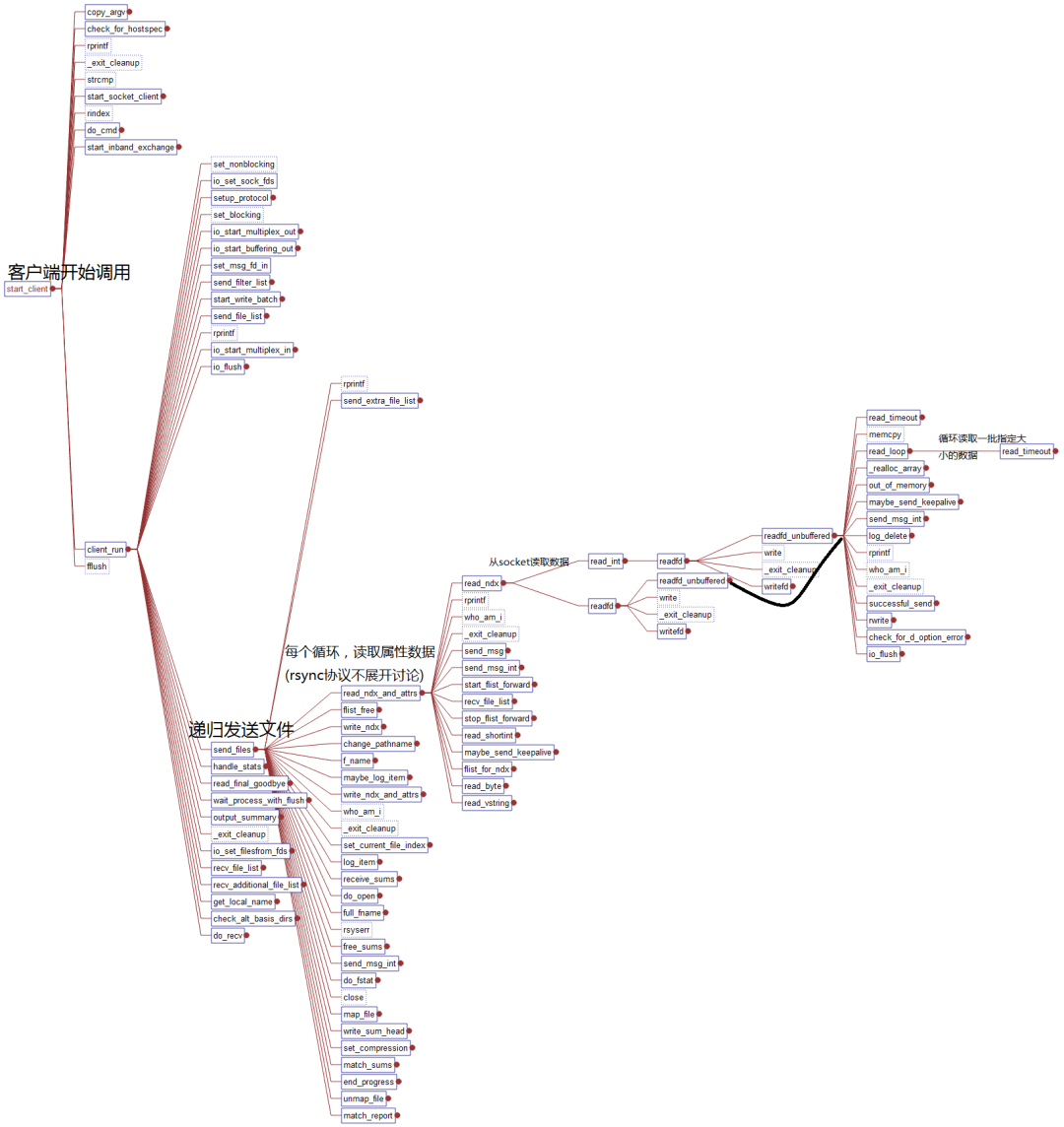
- 客戶端調用路線(大概):main->start_client->send_files->read_ndx_and_attrs->readfd_unbuffered->read_loop->read_timeout,最後跟蹤到
read_timeout函數,代碼如下所示(中文註釋是我添加的):
/**
* Read from a socket with I/O timeout. return the number of bytes
* read. If no bytes can be read then exit, never return a number <= 0.
*
//對於讀取失敗的問題,這裡列為TODO
* TODO: If the remote shell connection fails, then current versions
* actually report an "unexpected EOF" error here. Since it's a
* fairly common mistake to try to use rsh when ssh is required, we
* should trap that: if we fail to read any data at all, we should
* give a better explanation. We can tell whether the connection has
* started by looking e.g. at whether the remote version is known yet.
*/
static int read_timeout(int fd, char *buf, size_t len)
{
int n, cnt = 0;
io_flush(FULL_FLUSH);
while (cnt == 0) {
/* until we manage to read *something* */
fd_set r_fds, w_fds;
struct timeval tv;
int maxfd = fd;
int count;
FD_ZERO(&r_fds);
FD_ZERO(&w_fds);
FD_SET(fd, &r_fds); //要從fd讀取,把它加到讀取集合中
if (io_filesfrom_f_out >= 0) {
int new_fd;
if (ff_buf.len == 0) {
if (io_filesfrom_f_in >= 0) {
FD_SET(io_filesfrom_f_in, &r_fds);
new_fd = io_filesfrom_f_in;
} else {
io_filesfrom_f_out = -1;
new_fd = -1;
}
} else {
FD_SET(io_filesfrom_f_out, &w_fds);
new_fd = io_filesfrom_f_out;
}
if (new_fd > maxfd)
maxfd = new_fd;
}
tv.tv_sec = select_timeout; //設置超時,如果沒有指定,預設60秒
tv.tv_usec = 0;
errno = 0;
count = select(maxfd + 1, &r_fds, &w_fds, NULL, &tv); //select調用
//如果超時或者服務端關閉socket,都會返回count<0
if (count <= 0) {
if (errno == EBADF) {
defer_forwarding_messages = 0;
exit_cleanup(RERR_SOCKETIO);
}
check_timeout(); //處理超時,註意這兩句,如果超時,需要在check_timeout()中退出,否則會一直迴圈
continue;
}
//下麵的代碼忽略check_timeout函數(關鍵):
static void check_timeout(void)
{
time_t t;
if (!io_timeout || ignore_timeout) //註意,客戶端沒有--timeout選項,io_timeout會預設為0,也就是直接返回
return;
if (!last_io_in) {
last_io_in = time(NULL);
return;
}
t = time(NULL);
if (t - last_io_in >= io_timeout) {
if (!am_server && !am_daemon) {
rprintf(FERROR, "io timeout after %d seconds -- exiting\n",
(int)(t-last_io_in));
}
exit_cleanup(RERR_TIMEOUT);
}
}- 總結一下:
- 客戶端select預設60秒超時,超時之後檢查連接是否超時,如果超時則調用
exit_cleanup退出; - 如果客戶端沒有指定
--timeout,那麼io_timeout=0,程式會一直在select()中超時;
- 客戶端select預設60秒超時,超時之後檢查連接是否超時,如果超時則調用
最新版本是否解決了這個問題?rsync-3.1.3
rsync-3.1.3版本的代碼調用堆棧如下:
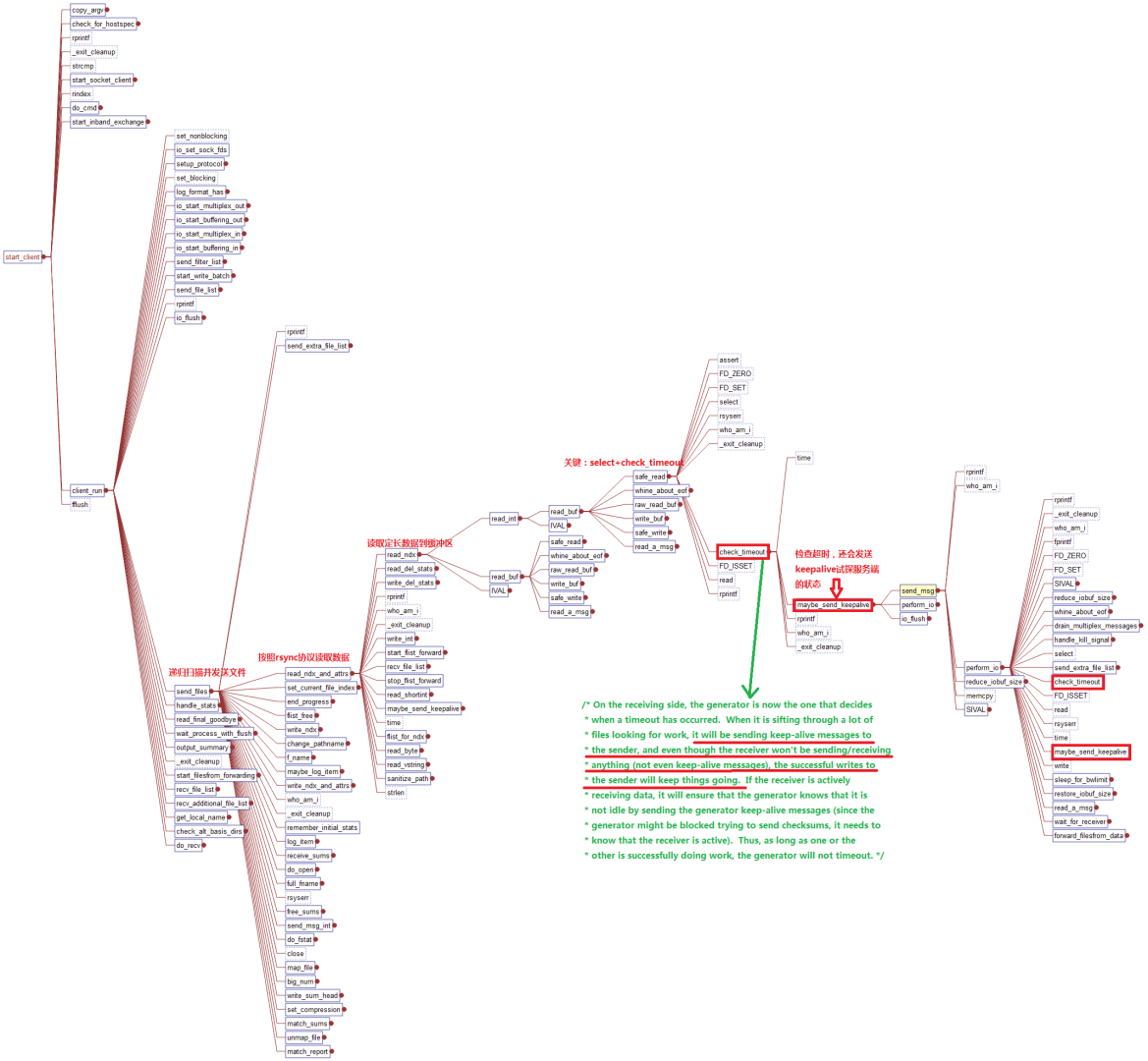
從這裡看出,檢查超時的時候,新版的rsync會嘗試發送一個keep_alive到服務端,如果讀寫成功,表示服務端還存活,則
perform_io()函數會更新時間戳,那麼在check_timeout()的後續判斷中就不會被判斷為超時。
總結以及解決辦法
- 在舊版本rsync中,當客戶端正在讀取服務端的信息,而此時服務端因為某種原因而斷開連接(如伺服器掛了,進程被kill了),客戶端會出現迴圈等待,造成卡死的現象,這是本次要查的問題。
- 原因出現在,舊版rsync沒有處理好上述問題,只是單純以超時判斷,而不去試探服務端是否存活,或者鏈接是否有效。
- 新版的解決辦法:select超時之後嘗試使用keep alive報文去寫socket,嘗試socket是否讀寫成功,如果成功,則更新socket的時間戳,相當於為這個socket加血續命。
- 可以考慮的解決辦法:
- 更新rsync到新版,尤其是客戶端;
- 客戶端調用時加上
--timeout選項指定超時;


