
Hadoop 1.0 到 Hadoop 2.0 經歷了什麼,我們又能從中看出什麼呢? ...
1. 概述
在 Google 三篇大數據論文發表之後,Cloudera 公司在這幾篇論文的基礎上,開發出了現在的 Hadoop 。但 Hadoop 開發出來也並非一帆風順的,Hadoop 1.0 版本有諸多局限。在後續的不斷實踐之中, Hadoop 2.0 橫空出世,而後 Hadoop 2.0 逐漸成為主流。這次我們就來看看 Hadoop 從 1.0 遇到了哪些問題,又為什麼需要做架構的升級呢?
2. Hadoop 1.0
首先我們來看 hadoop1.0 的整體結構。在 hadoop1.0 中有兩個模塊,一個是分散式文件系統 HDFS(Hadoop Distrbuted File System) 。另一個則是分散式計算框架 MapReduce 。我們分別來看看這兩個模塊的架構吧。
2.1 HDFS
對HDFS來說,其主要的運行架構則是 master-slave 架構,即主從架構。其中呢,master 主節點稱之為 Namenode 節點,而slave從節點稱為 DataNode 節點。
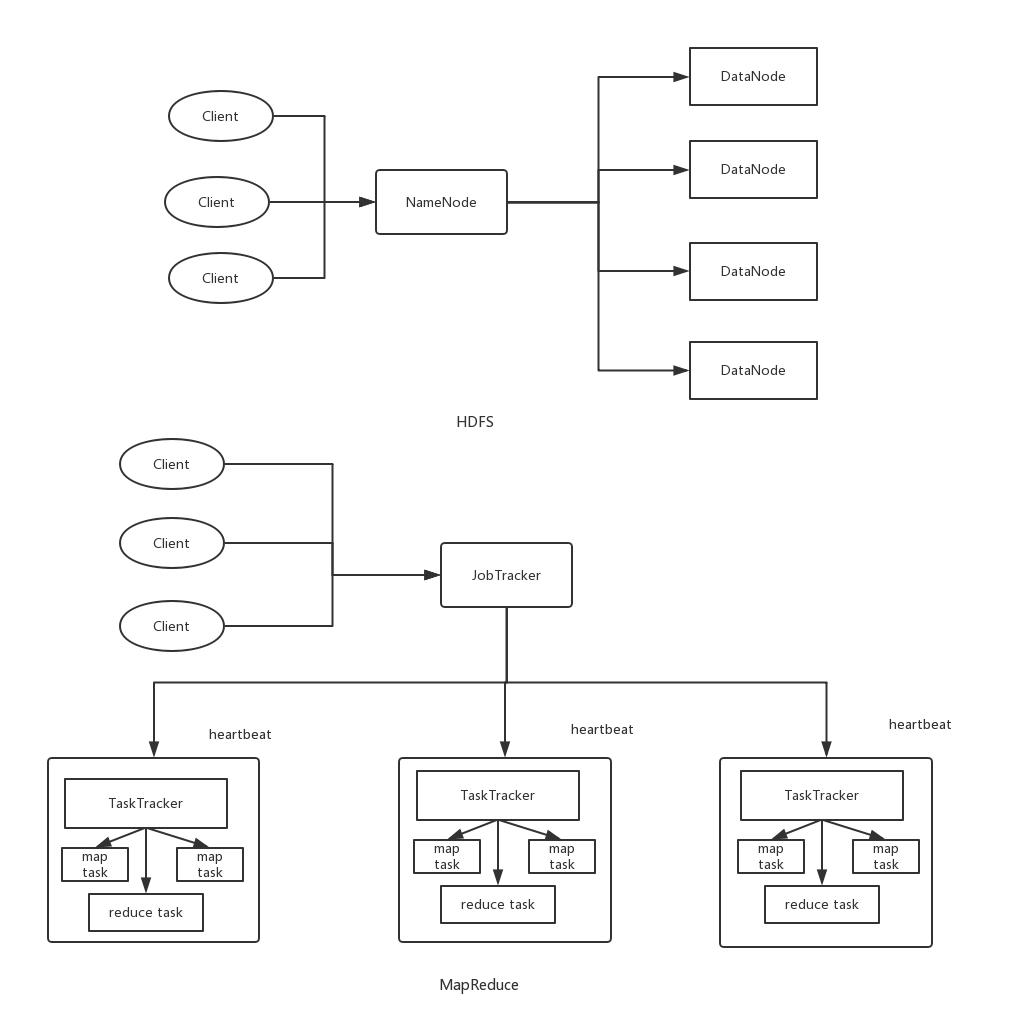
這個NameNode的職責是什麼呢?
- NameNode管理著整個文件系統,負責接收用戶的操作請求
- NameNode管理著整個文件系統的目錄結構,所謂目錄結構類似於我們Windows操作系統的體繫結構
- NameNode管理著整個文件系統的元數據信息,所謂元數據信息指定是除了數據本身之外涉及到文件自身的相關信息
- NameNode保管著文件與block塊序列之間的對應關係以及block塊與DataNode節點之間的對應關係
在hadoop1.0中,namenode有且只有一個,雖然可以通過SecondaryNameNode與NameNode進行數據同步備份,但是總會存在一定的延時,如果NameNode掛掉,但是如果有部份數據還沒有同步到SecondaryNameNode上,還是可能會存在著數據丟失的問題。
值得一提的是,在HDFS中,我們真實的數據是由DataNode來負責來存儲的,但是數據具體被存儲到了哪個DataNode節點等元數據信息則是由我們的NameNode來存儲的。
這種架構實現的好處的簡單,但其局限同樣明顯:
- 單點故障問題:因為NameNode含有我們用戶存儲文件的全部的元數據信息,當我們的NameNode無法在記憶體中載入全部元數據信息的時候,集群的壽命就到頭了。
- 拓展性問題:NameNode在記憶體中存儲了整個分散式文件系統中的元數據信息,並且NameNode只能有一臺機器,無法拓展。單台機器的NameNode必然有到達極限的地方。
- 性能問題:當HDFS中存儲大量的小文件時,會使NameNode的記憶體壓力增加。
- 隔離性問題:單個namenode難以提供隔離性,即:某個用戶提交的負載很大的job會減慢其他用戶的job。
2.2 MapReduce
對MapReduce來說,同樣時一個主從結構,是由一個JobTracker(主)和多個TaskTracker(從)組成。
而JobTracker在hadoop1.0的MapReduce中做了很多事情,可以說當爹又當媽。
- 負責接收client提交給的計算任務。
- 負責將接收的計算任務分配給各個的TaskTracker進行執行。
- 通過heartbeat(心跳)來管理TaskTracker機器的情況,同時監控任務task的執行狀況。
這個架構的缺陷:
- 單點故障:依舊是單點故障問題,如果JobTracker掛掉了會導致MapReduce作業無法執行。
- 資源浪費:JobTracker 完成了太多的任務,造成了過多的資源消耗,當 map-reduce job 非常多的時候,會造成很大的記憶體開銷,潛在來說,也增加了 JobTracker 失效的風險,這也是業界普遍總結出老 Hadoop 的 Map-Reduce 只能支持 4000 節點主機的上限;
- 只支持簡單的MapReduce編程模型:要使用Hadoop進行編程的話只能使用基礎的MapReduce,而無法使用諸如Spark這些計算模型。並且它也不支持流式計算和實時計算。
3. Hadoop 2.0

Hadoop 2.0 比起 Hadoop 1.0 來說,最大的改進是加入了 資源調度框架 Yarn ,我們依舊分為HDFS和 Yarn/MapReduce2.0 兩部分來講述Hadoop的改進。
3.1 HDFS
針對 Hadoop 1.0 中 NameNode 制約HDFS的擴展性問題,提出HDFS Federation 以及高可用 HA 。此時 NameNode 間相互獨立,也就是說它們之間不需要相互協調。且多個NameNode分管不同的目錄進而實現訪問隔離和橫向擴展。
這樣 NameNode 的可拓展性自然而然可用增加,據統計 Hadoop 2.0 中最多可以達到 10000 個節點同時運行,並且這樣的架構改進也解決了NameNode單點故障問題。
再來說說高可用 (HA) , HA 主要指的是可以同時啟動2個 NameNode 。其中一個處於工作 (Active) 狀態,另一個處於隨時待命(Standby)狀態。這樣,當一個NameNode所在的伺服器宕機時,可以在數據不丟失的情況下,手工或者自動切換到另一個 NameNode 提供服務。
3.2 Yarn/MapReduce2
針對 Hadoop 1.0 中 MR 的不足,引入了Yarn 框架。Yarn 框架中將 JobTracker 資源分配和作業控制分開,分為 Resource Manager (RM) 以及 Application Master (AM) 。
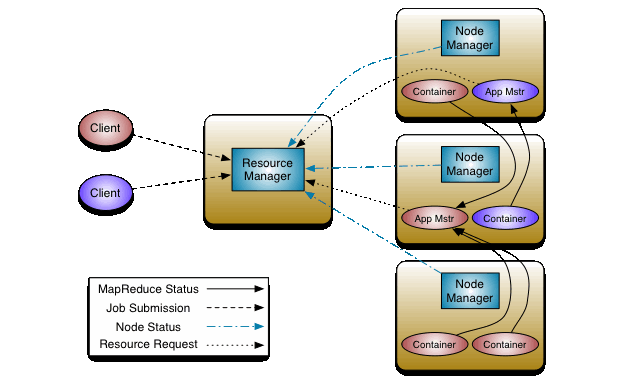
而Yarn框架作為一個通用的資源調度和管理模塊,同時支持多種其他的編程模型,比如最出名的 Spark 。
Yarn的主要三個組件如下:
Resource Manager:ResourceManager包含兩個主要的組件:定時調用器(Scheduler)以及應用管理器(ApplicationManager)。
定時調度器(Scheduler):定時調度器負責嚮應用程式分配資源,它不做監控以及應用程式的狀態跟蹤,並且它不保證會重啟由於應用程式本身或硬體出錯而執行失敗的應用程式。
應用管理器(ApplicationManager):應用程式管理器負責接收新任務,協調並提供在ApplicationMaster容器失敗時的重啟功能。
Application Master:每個應用程式的ApplicationMaster負責從Scheduler申請資源,以及跟蹤這些資源的使用情況以及任務進度的監控。
Node Manager:NodeManager是ResourceManager在每台機器的上代理,負責容器的管理,並監控他們的資源使用情況(cpu,記憶體,磁碟及網路等),以及向 ResourceManager/Scheduler提供這些資源使用報告。
一點點感悟
沒有什麼是一開始就完美的,當下最流行的 Hadoop 也一樣。從上面說的,我們可以知道 Hadoop 1.0 是比較簡陋的,這樣做的目的就是為了易於實現。Hadoop 這樣做也契合了敏捷開發的原則,也可以說契合產品經理口中的最小可行性產品(MVP),就是先實現一個簡單些,但核心功能齊全的版本出來,讓市場對其進行檢驗,而有了結果之後再進行拓展升級。
在當時那種許多公司都苦惱於沒有自己的大數據環境的情況下,Hadoop 一炮而紅。這時候再根據市場,也就是開源社區給出的反饋,不斷迭代,更新升級。最終成為大數群山中最為堅固的一座山峰。
我們在平時的產品開發中應該也要像 Hadoop 學習,先做出最小可行性產品出來,再在後面進行更新升級,不斷完善。當然這對一些完美主義者來說,可能會讓他感到比較痛苦。
你看,世間的事多是相通,技術的發展過程其實也暗合產品之道。有時候我們或許可以跳出技術之外,思考它背後產品的邏輯,這其中又有哪些是我們可以學習的,這些同樣是珍貴的寶藏,所謂他山之石,可以攻玉,莫過於此~~
以上~
推薦閱讀 :
從分治演算法到 MapReduce
Actor併發編程模型淺析
大數據存儲的進化史 --從 RAID 到 Hadoop Hdfs
一個故事告訴你什麼才是好的程式員


