
HashMap的put操作源碼解析 [toc] 1、官方文檔 1.1、繼承結構 1.2、類型參數: 2、put(key, value) HashMap是一種以鍵——值對的形式來存儲數據的數據結構。HashMap允許使用 null 值和 null 鍵,它並不能保證你存放數據和取出的順序是一致的。 接下 ...
目錄
HashMap的put操作源碼解析
1、官方文檔
1.1、繼承結構
java.lang.Object
java.util.AbstractMap<K,V>
java.util.HashMap<K,V>1.2、類型參數:
K - 此映射所維護的鍵的類型
V - 所映射值的類型2、put(key, value)
HashMap是一種以鍵——值對的形式來存儲數據的數據結構。HashMap允許使用 null 值和 null 鍵,它並不能保證你存放數據和取出的順序是一致的。
接下來就以下麵的代碼來看一下put是怎麼將數據存放到map中的。
public class HashMapTest {
public static void main(String[] args) {
Map<String, Object> map = new HashMap<String, Object>();
map.put(null, "map-value");
map.put(map-key", "map-value");
System.out.println(map);
}
}2.1、重點源碼部分截取
在map.put()這裡打個斷點F5(我用的eclipse)跟蹤進去。我們就會進到put方法中:
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
這裡的EMPTY_TABLE是HashMap的一個靜態常量,是一個Entry數組,預設值是空數組,table是HashMap的一個屬性且其預設值就是EMPTY_TABLE,這個table也就是我們數據存放的地方,至此為止可以知道,HashMap其實是一個數組,但它又不是一個純粹的數組。下麵會進行解釋。
static final Entry<?,?>[] EMPTY_TABLE = {};
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;而這個Entry其實是HashMap的一個內部類,定義如下(僅截取部分代碼),記住這個類,記住這個構造方法:它在new Entry的時候接收了一個Entry對象,並將自己的next指向了傳入的Entry對象形成一個鏈表,其自身是表頭。
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
}
從上面我們可以看出來這個Entry其實是一個鏈表,它存放了 key 和 value 並且還有一個指向下一個節點的引用 Entry, 剩下的這個 hash 就是 key 的哈希值。
現在我們可以捋一捋HashMap的結構了。首先HashMap是一個Entry數組,而這個Entry是一個單向鏈表,我們大致可以將其結構畫成如下圖所示:
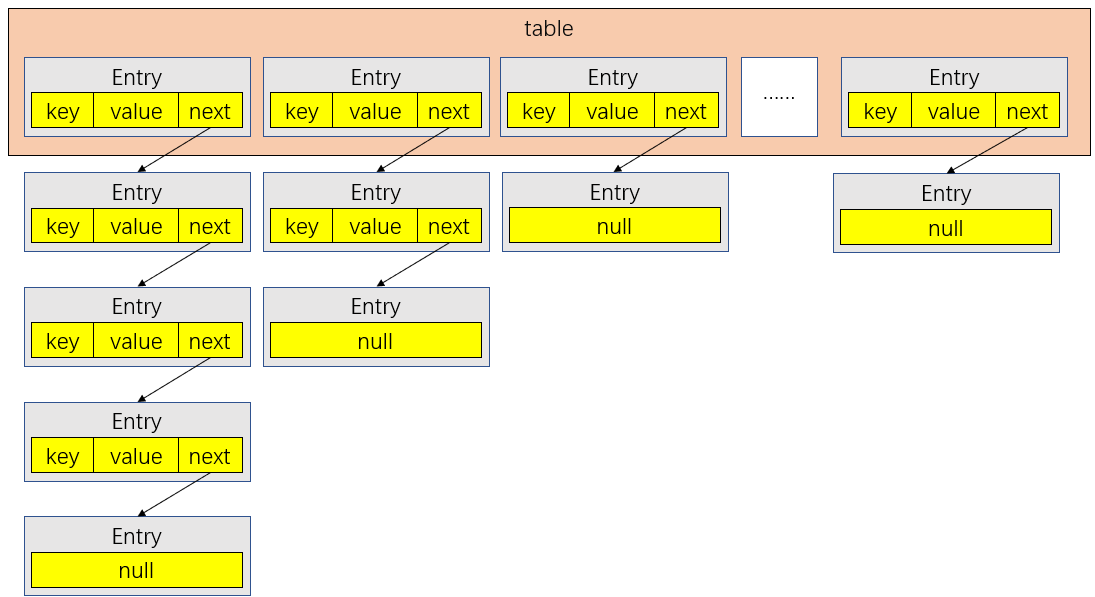
2.2、put(key, value)源碼分析
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}- 因為我們在實例化HashMap的時候使用的是無參構造方法,所以第一次
put數據的時候table為空
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}上面這段代碼會被執行,inflateTable(threshold) 會將table初始化為一個長度為16的Entry數組。
- 它會對我們的
key進行空判斷,如果是空就會執行下麵的代碼:
if (key == null)
return putForNullKey(value); putForNullKey(value) 的實現如下:
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}2.2.1 、key為null的情況
從上面可以看出來,如果key為null的話,它會從table中取出下標為0也就是第一個元素,沒忘記的話我們應該還知道它一個Entry,是一個鏈表,如果這個元素不是null,那麼就會遍歷這個鏈表,並判斷當前這個Entry節點對象的key是不是null。
- 如果是
null(key相同了): 使用oldValue來存放當前這個Entry節點對象的value,然後將我們新的值(map-value)賦給當前節點,再將原值oldValue返回回去。 - 如果遍歷完鏈表的所有節點都沒有找到
key為null的節點就會調用addEntry(0, null, value, 0),這個方法前面的if(){***}這塊代碼是判斷當前table是否要進行擴容。這裡只做簡單講述。
size是當前table存放的Entry鏈表的個數,拿我上面畫的那個HapshMap結構來看就是4。
如果我們實例化HashMap的時候沒有給大小那麼:threshold=loadFactor(負載因數預設為0.75f) *DEFAULT_INITIAL_CAPACITY(HashMap預設大小也就是table長度為16),所以threshold=12。
如果我們給了大小為initialCapacity,那麼負載因數還是預設的0.75f,但是threshold不需要算了,值就是initialCapacity。如果我們同時給了HashMap的大小initialCapacity和負載因數loadFactor,那麼HashMap就使用我們給定的負載因數值作為新的負載因數,給定的HashMap大小作為threshold。ok第一個條件結束。
null != table[bucketIndex]就很好理解了,就是我當前這個節點要存放的位置是空的。
滿足上面兩個條件,HashMap就會進行擴容,擴容後的大小為擴容前的2倍,然後對key重新計算它的hash值以及數組下標。 - 繼續
put內容,從上面源碼我們可以知道key為null的情況下它的hash值是0,至於bucketIndex的計算是這樣的h & (length-1),也是將hash值與table的長度按位相與值也是。至此也就是確定了key為null的這個節點將存放在table的第一個位置上。然後就會調用createEntry(0, null, "map-value", 0); - 在
createEntry(int hash, K key, V value, int bucketIndex)這個方法里首先拿到table中下標為bucketIndex的鏈表的表頭:Entry<K,V> e = table[bucketIndex];然後再用Entry對象的構造方法new一個Entry將我們的hash值,key,value,鏈表的表頭作為參數傳入:table[bucketIndex] = new Entry<>(hash, key, value, e);就這樣我們的這個新節點就放在了原來的表頭的前面作為新的表頭了。沒看懂的再回到上面看一下Entry的構造方法,我有重點標註的。
2.2.2、 key不為null的情況
源碼依舊拿下來
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}- 首先說一下
hash值:對於相同的key它們的hash值是相同的。但是hash值相同,它們的key卻不一定是相同的,這就是哈希碰撞。 key不為null的話它會根據key算出這個key對就的hash值以及它的bucketIndex,然後拿到table中下標為bucketIndex的這個Entry鏈表,然後遍歷這個鏈表,判斷當前節點的hash其實也就是當前節點的key的hash是否等於我們傳入的map-key的hash,然後判斷當前節點的key是否與我們傳入的key相同。
如果以上條件都滿足了,那麼就是key相同了,就會跟Key為null的分析中的第一條一樣將新值覆蓋舊值,並將舊值返回回去。
如果遍歷完這個鏈表以上條件沒有得到滿足,那麼就會跟key為null的分析中的第四條一樣,獲得table下標為i的鏈表的表頭e,然後將我們的map-key,map-value,hash以及表頭e作為參數new一個新的Entry對象並將它的next指向原來的表頭e,它也就變成了新的表頭了。
3、完結
最怕你的能力配不上你的野心。


