
GraphQuery " " " " " " " " " " " " GraphQuery is a query language and execution engine tied to any backend service. It is . Project Address: "GraphQue ...
GraphQuery 






GraphQuery is a query language and execution engine tied to any backend service. It is back-end language independent.
Project Address: GraphQuery
Related Projects:
- GraphQuery-PlayGround : Learn and test GraphQuery in an interactive walkthrough
- Document : Detailed documentation of GraphQuery
GraphQuery-http : Cross language solution for GraphQuery
Catalog
- Overview
- Getting Started
- Install
Overview
GraphQuery is an easy to use query language, it has built-in Xpath/CSS/Regex/JSONpath selectors and enough built-in text processing functions.
The most amazing thing is that you can use the minimalist GraphQuery syntax to get any data structure you want.
Language-independent
Use GraphQuery to let you unify text parsing logic on any backend language.
You won't need to find implementations of Xpath/CSS/Regex/JSONpath selectors between different languages and get familiar with their syntax or explore their compatibility.
Multiple selector syntax support
You can use GraphQuery to parse any text and use your skilled selector. GraphQuery currently supports the following selectors:
Jsonpathfor parsing JSON stringsXpathandCSSfor parsing XML/HTMLRegular expressionsfor parsing any text.
You can use these selectors in any combination in GraphQuery. The rich built-in selector provides great flexibility for your parsing.
Complete function
Graphquery has some built-in text processing functions like trim, template, replace. If you think these functions don't meet your needs, you can register new custom functions in the pipeline.
Clear data structure & Concise grammar
With GraphQuery, you won't need to look for parsing libraries when parsing text, nor do you need to write complex nesting and traversal. Simple and clear GraphQuery syntax gives you a clear picture of the data structure.

As you can see from the comparison chart above, the syntax of GraphQuery is so simple that even if you are in touch with it for the first time, you can still understand its meaning and get started quickly.
At the same time, GraphQuery is also very easy to integrate into your backend data system (any backend language), let's continue to look down.
Getting Started
GraphQuery consists of query language and pipelines. To guide you through each of these components, we've written an example designed to illustrate the various pieces of GraphQuery. This example is not comprehensive, but it is designed to quickly introduce the core concepts of GraphQuery. The premise of the example is that we want to use GraphQuery to query for information about library books.
1. First example
<library>
<!-- Great book. -->
<book id="b0836217462" available="true">
<isbn>0836217462</isbn>
<title lang="en">Being a Dog Is a Full-Time Job</title>
<quote>I'd dog paddle the deepest ocean.</quote>
<author id="CMS">
<?echo "go rocks"?>
<name>Charles M Schulz</name>
<born>1922-11-26</born>
<dead>2000-02-12</dead>
</author>
<character id="PP">
<name>Peppermint Patty</name>
<born>1966-08-22</born>
<qualification>bold, brash and tomboyish</qualification>
</character>
<character id="Snoopy">
<name>Snoopy</name>
<born>1950-10-04</born>
<qualification>extroverted beagle</qualification>
</character>
</book>
</library>Faced with such a text structure, we naturally think of extracting the following data structure from the text :
{
bookID
title
isbn
quote
language
author{
name
born
dead
}
character [{
name
born
qualification
}]
}This is perfect, when you know the data structure you want to extract, you have actually succeeded 80%, the above is the data structure we want, we call it DDL (Data Definition Language) for the time being. let's see how GraphQuery does it:
{
bookID `css("book");attr("id")`
title `css("title")`
isbn `xpath("//isbn")`
quote `css("quote")`
language `css("title");attr("lang")`
author `css("author")` {
name `css("name")`
born `css("born")`
dead `css("dead")`
}
character `xpath("//character")` [{
name `css("name")`
born `css("born")`
qualification `xpath("qualification")`
}]
}As you can see, the syntax of GraphQuery adds some strings wrapped in ` to the DDL. These strings wrapped by ` are called Pipeline. We will introduce Pipeline later.
Let's first take a look at what data GraphQuery engine returns to us.
{
"bookID": "b0836217462",
"title": "Being a Dog Is a Full-Time Job",
"isbn": "0836217462",
"quote": "I'd dog paddle the deepest ocean.",
"language": "en",
"author": {
"born": "1922-11-26",
"dead": "2000-02-12",
"name": "Charles M Schulz"
},
"character": [
{
"born": "1966-08-22",
"name": "Peppermint Patty",
"qualification": "bold, brash and tomboyish"
},
{
"born": "1950-10-04",
"name": "Snoopy",
"qualification": "extroverted beagle"
}
],
}Wow, it's wonderful. Just like what we want.
We call the above example Example1, now let's have a brief look at what pipeline is.
2. Pipeline
A pipeline is a collection of functions that use the parent element text as an entry parameter to execute the functions in the collection in sequence.
For example, the language field in our previous example is defined as follows:
language `css("title");attr("lang")`The language is the field name, css("title"); attr("lang") is the pipeline. In this pipeline, GraphQuery first uses the CSS selector to find the title node from the document, and the title node will be obtained. Pass the obtained node into the attr() function and get its lang attribute. The whole process is as follows:
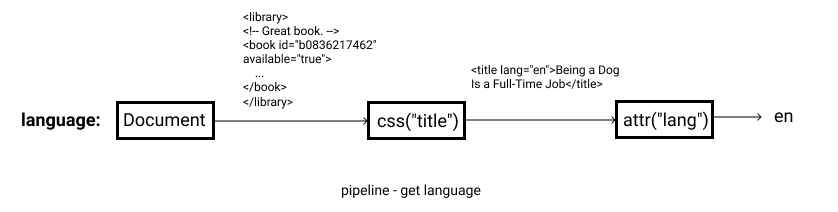
In Example1, we not only use the css and attr functions, but also xpath(). It is easy to associate, Xpath() is to select elements with the Xpath selector.
The following is a list of the pipeline functions built into the current version of graphquery:
| pipeline | prototype | example | introduce |
|---|---|---|---|
| css | css(CSSSelector) | css("title") | Use CSS selector to select elements |
| json | json(JSONSelector) | json("title") | Use json path to select elements |
| xpath | xpath(XpathSelector) | xpath("//title") | Use Xpath selector to select elements |
| regex | regex(RegexSelector) | regex("") | Use Regex selector to select elements |
| trim | trim() | trim() | Clear spaces and line breaks before and after the string |
| template | template(TemplateStr) | template("[{$}]") | Add characters before and after variables |
| attr | attr(AttributeName) | attr("lang") | Extract the property of the current node |
| eq | eq(Index) | eq("0") | Take the nth element in the current node collection |
| string | string() | string() | Extract the current node native string |
| text | text() | text() | Extract the text of the current node |
| link | link(KeyName) | link("title") | Returns the current text of the specified key |
| replace | replace(A, B) | replace("a", "b") | Replace all A in the current node to B |
More detailed introduction to pipeline and function, please go to docs.
Install
GraphQuery is currently only native to Golang, but for other languages, it can be invoked as a service.
1. Golang:
go get github.com/storyicon/graphqueryCreate a new go file :
package main
import (
"encoding/json"
"log"
"github.com/storyicon/graphquery"
)
func main() {
document := `
<html>
<body>
<a href="01.html">Page 1</a>
<a href="02.html">Page 2</a>
<a href="03.html">Page 3</a>
</body>
</html>
`
expr := "{ anchor `css(\"a\")` [ content `text()` ] }"
response := graphquery.ParseFromString(document, expr)
bytes, _ := json.Marshal(response.Data)
log.Println(string(bytes))
}Run the go file, the output is as follows :
{"anchor":["Page 1","Page 2","Page 3"]}2. Other language
We use the HTTP protocol to provide a cross-language solution for developers to query GraphQuery using any back-end language you want to use to access the specified port after starting the service.
GraphQuery-http : Cross language solution for GraphQuery
You can also use RPC for communication, but currently you may need to do this yourself, because the RPC project on GraphQuery is still under development.
At the same time, We welcome the contributors to write native support code for other languages in GraphQuery.

