
1.前言 總是聊併發的話題,聊到大家都免疫了,所以這次串講下個話題——資料庫(歡迎糾正補充) 看完問自己一個問題來自我檢測: NoSQL我到底該怎麼選? 1.1.分類 主要有這麼三大類:[再老的資料庫就不說了] 1.傳統資料庫(SQL): 關係資料庫:SQLite、MySQL、SQLServer.. ...
1.前言
總是聊併發的話題,聊到大家都免疫了,所以這次串講下個話題——資料庫(歡迎糾正補充)
看完問自己一個問題來自我檢測:NoSQL我到底該怎麼選?
1.1.分類
主要有這麼三大類:[再老的資料庫就不說了]
1.傳統資料庫(SQL):
- 關係資料庫:SQLite、MySQL、SQLServer...
2.高併發產物(NoSQL):
- 鍵值資料庫:Redis、MemCached...
- 文檔資料庫:MongoDB、CouchBase、CouchDB、RavenDB...
- 列式資料庫:Cassandra、HBase、BigTable...
- 圖形資料庫:Neo4J、Infinite Graph、InfoGrid...
3.新時代產物(TSDB):
- 時序資料庫:InfluxDB、LogDevice...
來看個權威的圖:(紅色的是推薦NoSQL,灰色是傳統SQL)
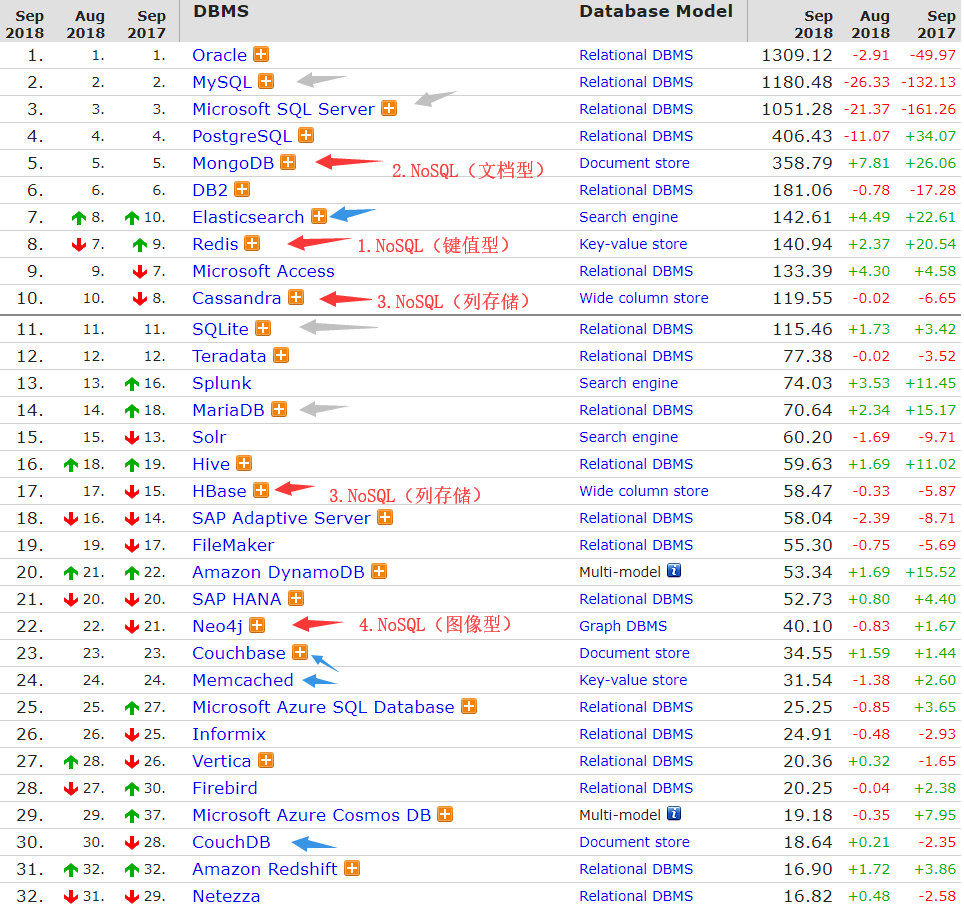
1.2.概念
先說下NoSQL不是不要使用傳統SQL了,而是不僅僅是傳統的SQL(not only sql)
1.關係型資料庫優劣
先看看傳統資料庫的好處:
- 通過事務保持數據一致
- 可以Join等複雜查詢
- 社區完善(遇到問題簡單搜下就ok了)
當然了也有不足的地方:
- 數據量大了的時候修改表結構。eg:加個欄位,如果再把這個欄位設置成索引那是卡到爆,完全不敢在工作時間搞啊
- 列不固定就更蛋疼了,一般設計資料庫不可能那麼完善,都是後期越來越完善,就算自己預留了
保留欄位也不人性化啊 - 大數據寫入處理比較麻煩,eg:
- 數據量不大還好,批量寫入即可。
- 可是本身數據量就挺大的,進行了
主從複製,讀數據在Salver進行到沒啥事,但是大量寫資料庫懟到Master上去就吃不消了,必須得加主資料庫了。 - 加完又出問題了:雖然把主資料庫一分為二,但是容易發生
數據不一致(同樣數據在兩個主資料庫更新成不一樣的值),這時候得結合分庫分表,把表分散在不同的主資料庫中。 - 完了嗎?NoNoNo,想一想表之間的Join咋辦?豈不是要跨資料庫和跨伺服器join了?簡直就是拆東牆補西牆的節奏啊,所以各種中間件就孕育而生了【SQLServer這方面擴展的挺不錯的,列存儲也自帶,也跨平臺了(建議在Docker中運行)(點我查看幾年前寫的一篇文章)】
- 歡迎補充~(說句良心話,中小型公司
SQLServer絕對是最佳選擇,能省去很多時間)
2.NoSQL
現在說說NoSQL了:(其實你可以理解為:NoSQL就是對原來SQL的擴展補充)
- 分表分庫的時候一般把關聯的表放在同一臺伺服器上,這樣便於join操作。而NoSQL不支持join,反而不用這麼局限了,數據更容易分散存儲
- 大量數據處理這塊,讀方面傳統SQL並沒有太多劣勢,NoSQL主要是進行緩存處理,批量寫數據方面測試往往遠高於傳統SQL,而且NoSQL在擴展方面方便太多了
- 多場景類型的NoSQL(鍵值,文檔、列、圖形)
如果還是不清楚到底怎麼選擇NoSQL,那就再詳細說說每個類型的特點:
- 鍵值資料庫:這個大家很熟悉,主要就是
鍵值存儲,代表=>Redis(支持持久化和數據恢復,後面我們會詳談) - 文檔資料庫:代表=>MongoDB(優酷的線上評論就是用基於MongoDB的)
- 一般都不具備事務(
MongoDB 4.0開始支持ACID事務了) - 不支持Join(Value是一個可變的
類JSON格式,表結構修改比較方便)
- 一般都不具備事務(
- 列式資料庫:代表:Cassandra、
HBase- 對大量行少量列進行修改更新(新增一欄位,批量做個啥操作的不要太方便啊~針對列為單位讀寫)
- 擴展性高,數據增加也不會降低對應的處理速度(尤其是寫)
- 圖形資料庫:代表:Neo4J(數據模型是圖結構的,主要用於 關係比較複雜 的設計,比如繪製一個QQ群關係的可視化圖、或者繪製一個微博粉絲關係圖等)
回頭還是要把併發剩餘幾個專題深入的,認真看的同志會發現不管什麼語言底層實現都是差不多的。
比如說進程,其底層就是用到了我們第一講說的OS.fork。再說進(線)程通信,講的PIPE、FIFO、Lock、Semaphore等很少用吧?但是Queue底層就是這些實現的,不清楚的話怎麼讀源碼?
還記得當時引入Queue篇提到Java里的CountDownLatch嗎?要是不瞭解Condition怎麼自己快速模擬一個Python裡面沒有的功能呢?
知其然不知其所以然是萬萬不可取的。等後面講MQ的時候又得用到Queue的知識了,可謂一環套一環~
既然不是公司的萌妹子,所以呢~技術的提升還是得靠自己了^_^,先到這吧,最後貼個常用解決方案:
Python、NetCore常用解決方案(持續更新)
https://github.com/LessChina
2.概念
上篇提到了ACID這次準備說說,然後再說說CAP和數據一致性
2.1.ACID事務
以小明和小張轉賬的例子繼續說說:
- A:原子性(Atomic)
- 小明轉賬1000給小張:小明-=1000 => 小張+=1000,這個 (事務)是一個不可分割的整體,如果小明-1000後出現問題,那麼1000得退給小明
- C:一致性(Consistent)
- 小明轉賬1000給小張,必須保證小明+小張的總額不變(假設不受其他轉賬(事務)影響)
- I:隔離性(Isolated)
- 小明轉賬給小張的同時,小潘也轉錢給了小張,需要保證他們相互不影響(主要是併發情況下的隔離)
- D:持久性(Durable)
- 小明轉賬給小張銀行要有記錄,即使以後扯皮也可以拉流水賬【事務執行成功後進行的持久化(就算資料庫之後掛了也能通過Log恢復)】
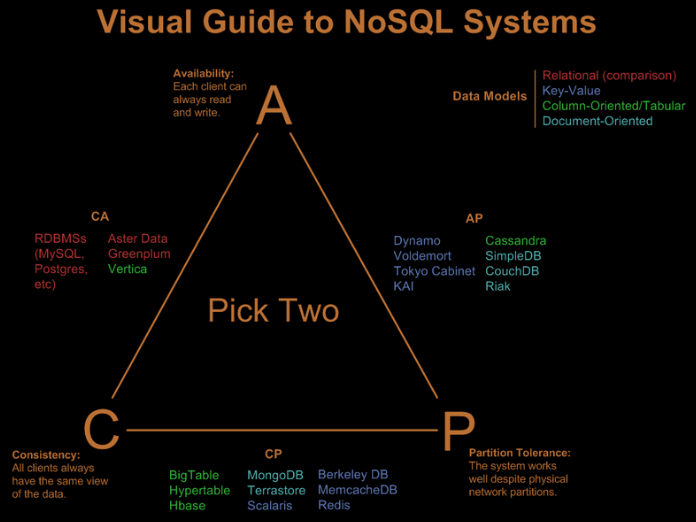
2.2.CAP概念
CAP是分散式系統需要考慮的三個指標,數據共用只能滿足兩個而不可兼得:
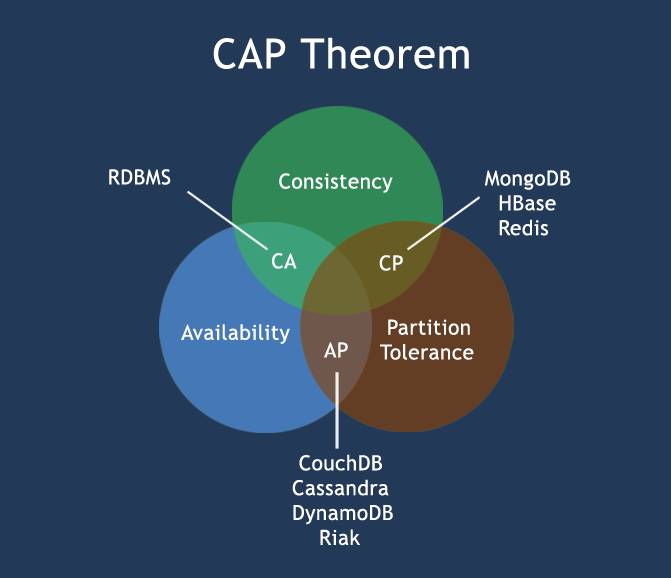
- C:一致性(Consistency)
- 所有節點訪問同一份最新的數據副本(在分散式系統中的所有數據備份,在同一時刻是否同樣的值)
- eg:分散式系統里更新後,某個用戶都應該讀取最新值
- A:可用性(Availability)
- 在集群中一部分節點故障後,集群整體是否還能響應客戶端的讀寫請求。(對數據更新具備高可用性)
- eg:分散式系統里每個操作總能在一定時間內返回結果(超時不算【網購下單後一直等算啥?機房掛幾個伺服器也不影響】)
- P:分區容錯性(Partition Toleranc)
- 以實際效果而言,分區相當於對通信的時限要求。系統如果不能在時限內達成數據一致性,就意味著發生了分區的情況,必須就當前操作在C和A之間做出選擇。
- eg:分散式系統里,存在網路延遲(分區)的情況下依舊可以接受滿足一致性和可用性的請求
CA
代表:傳統關係型資料庫
如果想避免分區容錯性問題的發生,一種做法是將所有的數據(與事務相關的)都放在一臺機器上。雖然無法100%保證系統不會出錯,但不會碰到由分區帶來的負面效果(會嚴重的影響系統的擴展性)
作為一個分散式系統,放棄P,即相當於放棄了分散式,一旦併發性很高,單機服務根本不能承受壓力。像很多銀行服務,確確實實就是捨棄了P,只用高性能的單台小型機保證服務可用性。(所有NoSQL資料庫都是假設P是存在的)
CP
代表:Zookeeper、Redis(分散式資料庫、分散式鎖)
相對於放棄“分區容錯性“來說,其反面就是放棄可用性。一旦遇到分區容錯故障,那麼受到影響的服務需要等待數據一致(等待數據一致性期間系統無法對外提供服務)
AP
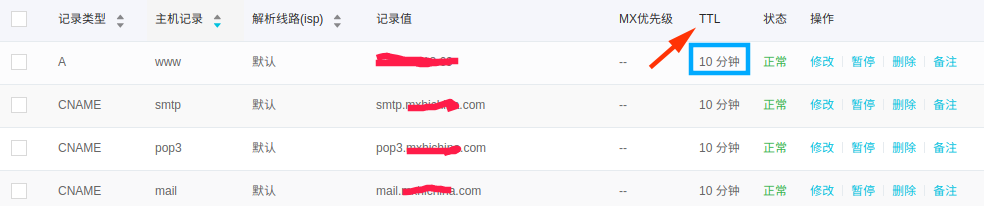
代表:DNS資料庫(IP和功能變數名稱相互映射的分散式資料庫,聯想修改IP後為什麼TTL需要10分鐘左右保證所有解析生效)
反DNS查詢:https://www.cnblogs.com/dunitian/p/5074773.html
放棄強一致,保證最終一致性。所有的NoSQL資料庫都是介於CP和AP之間,儘量往AP靠,(傳統關係型資料庫註重數據一致性,而對海量數據的分散式處理來說可用性和分區容錯性優先順序高於數據一致性)eg:
不同數據對一致性要求是不一樣的,eg:
- 用戶評論、彈幕這些對一致性是不敏感的,很長時間不一致性都不影響用戶體驗
- 像商品價格等等你敢來個看看?對一致性是很高要求的,容忍度鐵定低於10s,就算使用了緩存在訂單裡面價格也是最新的(平時註意下JD商品下麵的緩存說明,JD尚且如此,其他的就不用說了)
2.3.數據一致性
傳統關係型資料庫一般都是使用悲觀鎖的方式,但是例如秒殺這類的場景是hou不動,這時候往往就使用樂觀鎖了(CAS機制,之前講併發和鎖的時候提過),上面也稍微提到了不同業務需求對一致性有不同要求而CAP不能同時滿足,這邊說說主要就兩種:
- 強一致性:無論更新在哪個副本上,之後對操作都要能夠獲取最新數據。多副本數據就需要
分散式事物來保證數據一致性了(這就是問什麼項目裡面經常提到的原因) - 最終一致性:在這種約束下保證用戶最終能讀取到最新數據。舉幾個例子:
- 因果一致性:A、B、C三個獨立進程,A修改了數據並通知了B,這時候B得到的是最新數據。因為A沒通知C,所以C不是最新數據
- 會話一致性:用戶自己提交更新,他可以在會話結束前獲取更新數據,會話結束後(其他用戶)可能不是最新的數據(提交後JQ修改下本地值,不能保證數據最新)
- 讀自寫一致性:和上面差不多,只是不局限在會話中了。用戶更新數據後他自己獲取最新數據,其他用戶可能不是最新數據(一定延遲)
- 單調讀一致性:用戶讀取某個數值,後續操作不會讀取到比這個數據還早的版本(新的程度>=讀取的值)
- 單調寫一致性(時間軸一致性):所有資料庫的所有副本按照相同順序執行所有更新操作(有點像
Redis的AOF)
2.4.一致性實現方法
Quorum系統NRW策略(常用)
Quorum是集合A,A是全集U的子集,A中任意取集合B、C,他們兩者都存在交集。
NRW演算法:
- N:表示數據所具有的副本數。
- R:表示完成讀操作所需要讀取的最小副本數(一次讀操作所需參與的最小節點數)
- W:表示完成寫操作所需要寫入的最小副本數(一次寫操作所需要參與的最小節點數)
- 只需要保證
R + W > N就可以保證強一致性(讀取數據的節點和被同步寫入的節點是有重疊的)比如:N=3,W=2,R=2(有一個節點是讀+寫)
擴展:
- 關係型資料庫中,如果N=2,可以設置W=2,R=1(寫耗性能一點),這時候系統需要兩個節點上數據都完成更新才能確認結果並返回給用戶
- 如果
R + W <= N,這時候讀寫不會在一個節點上同時出現,系統只能保證最終一致性。副本達到一致性的時間依賴於系統非同步更新的方式,不一致性時間=從更新節點~所有節點都非同步更新完畢的耗時 - R和W設置直接影響系統的性能、擴展和一致性:
- 如果W設置為1,那麼一個副本更新完就返回給用戶,然後通過非同步機制更新剩餘的N-W個節點
- 如果R設置為1,只要有一個副本被讀取就可以完成讀操作,R和W的值如果較小會影響一致性,較大會影響性能
- 當W=1,R=N==>系統對寫要求高,但讀操作會比較慢(N個節點裡面有1個掛了,讀就完成不了了)
- 當R=1,W=N==>系統對讀操作有高要求,但寫性能就低了(N個節點裡面有1個掛了,寫就完成不了了)
- 常用方法:一般設置
R = W = N/2 + 1,這樣性價比高,eg:N=3,W=2,R=2(3個節點==>1寫,1讀,1讀寫)
參考文章:
http://book.51cto.com/art/201303/386868.htm
https://blog.csdn.net/jeffsmish/article/details/54171812時間軸策略(常用)
- 主要是關係型資料庫的日記==>記錄事物操作,方便數據恢復
- 還有就是並行數據存儲的時候,由於數據是分散存儲在不同節點的,對於同一節點來說只要關心
數據更新+消息通信(數據同步):- 保證較晚發生的更新時間>較早發生的更新時間
- 消息接收時間 > 消息發送時刻的時間(要考慮伺服器時間差的問題~時間同步伺服器)
其他策略
其實還有很多策略來保證,這些概念的對象逆天不是很熟~比如:向量時鐘策略
推薦幾篇文章:
https://www.cnblogs.com/yanghuahui/p/3767365.html
http://blog.chinaunix.net/uid-27105712-id-5612512.html
https://blog.csdn.net/dellme99/article/details/16845991
https://blog.csdn.net/blakeFez/article/details/48321323

