
多表查詢連接 準備倆張員工信息表,我們要查詢員工信息及員工所在部門.那麼就需要倆張表進 行連接查詢,多表查詢. 外鏈接 語法 select 欄位列表 from 表1 inner/left/right join 表2 on 表1.欄位 = 表2.欄位; 第一種情況交叉連接: 不適用任何匹配條件.生成笛 ...
多表查詢連接
準備倆張員工信息表,我們要查詢員工信息及員工所在部門.那麼就需要倆張表進
行連接查詢,多表查詢.
外鏈接 語法
select 欄位列表
from 表1 inner/left/right join 表2 on 表1.欄位 = 表2.欄位;
第一種情況交叉連接: 不適用任何匹配條件.生成笛卡爾積.
mysql> select * from employee,department; +----+----------+--------+------+--------+------+--------------+ | id | name | sex | age | dep_id | id | name | +----+----------+--------+------+--------+------+--------------+ | 1 | egon | male | 18 | 200 | 200 | 技術 | | 1 | egon | male | 18 | 200 | 201 | 人力資源 | | 1 | egon | male | 18 | 200 | 202 | 銷售 | | 1 | egon | male | 18 | 200 | 203 | 運營 | | 2 | alex | female | 48 | 201 | 200 | 技術 | | 2 | alex | female | 48 | 201 | 201 | 人力資源 | | 2 | alex | female | 48 | 201 | 202 | 銷售 | | 2 | alex | female | 48 | 201 | 203 | 運營 | | 3 | wupeiqi | male | 38 | 201 | 200 | 技術 | | 3 | wupeiqi | male | 38 | 201 | 201 | 人力資源 | | 3 | wupeiqi | male | 38 | 201 | 202 | 銷售 | | 3 | wupeiqi | male | 38 | 201 | 203 | 運營 | | 4 | yuanhao | female | 28 | 202 | 200 | 技術 | | 4 | yuanhao | female | 28 | 202 | 201 | 人力資源 | | 4 | yuanhao | female | 28 | 202 | 202 | 銷售 | | 4 | yuanhao | female | 28 | 202 | 203 | 運營 | | 5 | nvshen | male | 18 | 200 | 200 | 技術 | | 5 | nvshen | male | 18 | 200 | 201 | 人力資源 | | 5 | nvshen | male | 18 | 200 | 202 | 銷售 | | 5 | nvshen | male | 18 | 200 | 203 | 運營 | | 6 | xiaomage | female | 18 | 204 | 200 | 技術 | | 6 | xiaomage | female | 18 | 204 | 201 | 人力資源 | | 6 | xiaomage | female | 18 | 204 | 202 | 銷售 | | 6 | xiaomage | female | 18 | 204 | 203 | 運營 |
內連接 : 只連接匹配的行
#找兩張表共有的部分,相當於利用條件從笛卡爾積結果中篩選出了匹配的結果 #department沒有204這個部門,因而employee表中關於204這條員工信息沒有匹配出來 mysql> select employee.id,employee.name,employee.age,employee.sex,department.name from employee inner join department
on employee.dep_id=department.id; +----+---------+------+--------+--------------+ | id | name | age | sex | name | +----+---------+------+--------+--------------+ | 1 | egon | 18 | male | 技術 | | 2 | alex | 48 | female | 人力資源 | | 3 | wupeiqi | 38 | male | 人力資源 | | 4 | yuanhao | 28 | female | 銷售 | | 5 | nvshen | 18 | male | 技術 | +----+---------+------+--------+--------------+ rows in set (0.00 sec) #上述sql等同於 mysql> select employee.id,employee.name,employee.age,employee.sex,department.name from employee,department where employee.dep_id=department.id;
外鏈接之右連接: 優先顯示右表全記錄
#以右表為準,即找出所有部門信息,包括沒有員工的部門 #本質就是:在內連接的基礎上增加右邊有,左邊沒有的結果 mysql> select employee.id,employee.name,department.name as depart_name from employee right join department on employee.dep_id=department.id; +------+---------+--------------+ | id | name | depart_name | +------+---------+--------------+ | 1 | egon | 技術 | | 2 | alex | 人力資源 | | 3 | wupeiqi | 人力資源 | | 4 | yuanhao | 銷售 | | 5 | nvshen | 技術 | | NULL | NULL | 運營 | +------+---------+--------------+ rows in set (0.00 sec)
外鏈接之左連接: 優先顯示左表全記錄
#以左表為準,即找出所有員工信息,當然包括沒有部門的員工 #本質就是:在內連接的基礎上增加左邊有,右邊沒有的結果 mysql> select employee.id,employee.name,department.name as depart_name from employee left join department on employee.dep_id=department.id; +----+----------+--------------+ | id | name | depart_name | +----+----------+--------------+ | 1 | egon | 技術 | | 5 | nvshen | 技術 | | 2 | alex | 人力資源 | | 3 | wupeiqi | 人力資源 | | 4 | yuanhao | 銷售 | | 6 | xiaomage | NULL | +----+----------+--------------+ rows in set (0.00 sec)
全外連接:顯示左右倆個表全部記錄
#外連接:在內連接的基礎上增加左邊有右邊沒有的和右邊有左邊沒有的結果 #註意:mysql不支持全外連接 full JOIN #強調:mysql可以使用此種方式間接實現全外連接 語法:select * from employee left join department on employee.dep_id = department.id union all select * from employee right join department on employee.dep_id = department.id; mysql> select * from employee left join department on employee.dep_id = department.id union select * from employee right join department on employee.dep_id = department.id ; +------+----------+--------+------+--------+------+--------------+ | id | name | sex | age | dep_id | id | name | +------+----------+--------+------+--------+------+--------------+ | 1 | egon | male | 18 | 200 | 200 | 技術 | | 5 | nvshen | male | 18 | 200 | 200 | 技術 | | 2 | alex | female | 48 | 201 | 201 | 人力資源 | | 3 | wupeiqi | male | 38 | 201 | 201 | 人力資源 | | 4 | yuanhao | female | 28 | 202 | 202 | 銷售 | | 6 | xiaomage | female | 18 | 204 | NULL | NULL | | NULL | NULL | NULL | NULL | NULL | 203 | 運營 | +------+----------+--------+------+--------+------+--------------+ rows in set (0.01 sec) #註意 union與union all的區別:union會去掉相同的紀錄
符合條件連接查詢
以內連接的方式查詢employee和department表,並且employee表中的age
欄位值必須大於25,即找出年齡大於25歲的員工以及員工所在的部門.
select employee.name,department.name from employee inner join department on employee.dep_id = department.id where age > 25;
以內連接的方式查詢employee和department表,並且以age欄位的升序方式顯示.
select employee.id,employee.name,employee.age,department.name from employee,department where employee.dep_id = department.id and age > 25 order by age asc;
子查詢
子查詢是將一個查詢語句嵌套在另一個查詢語句中.
內層查詢語句的查詢結果,可以為外層查詢語句提供查詢條件.
子查詢中可以包含:in, not in , any , all , exists 和 not exist等關鍵字
還可以包含比較運算符: = , != , > ,< 等
例 帶in 關鍵字的查詢
#查詢平均年齡在25歲以上的部門名 select id,name from department where id in (select dep_id from employee group by dep_id having avg(age) > 25); # 查看技術部員工姓名 select name from employee where dep_id in (select id from department where name='技術'); #查看不足1人的部門名 select name from department where id not in (select dep_id from employee group by dep_id);
帶比較運算的子查詢
#比較運算符:=、!=、>、>=、<、<=、<> #查詢大於所有人平均年齡的員工名與年齡 mysql> select name,age from employee where age > (select avg(age) from employee); +---------+------+ | name | age | +---------+------+ | alex | 48 | | wupeiqi | 38 | +---------+------+ #查詢大於部門內平均年齡的員工名、年齡 思路: (1)先對員工表(employee)中的人員分組(group by),查詢出dep_id以及平均年齡。 (2)將查出的結果作為臨時表,再對根據臨時表的dep_id和employee的dep_id作為篩選條件將employee表和臨時表進行內連接。 (3)最後再將employee員工的年齡是大於平均年齡的員工名字和年齡篩選。 mysql> select t1.name,t1.age from employee as t1 inner join (select dep_id,avg(age) as avg_age from employee group by dep_id) as t2 on t1.dep_id = t2.dep_id where t1.age > t2.avg_age; +------+------+ | name | age | +------+------+ | alex | 48 |
帶exists關鍵字的子查詢
#EXISTS關字鍵字表示存在。在使用EXISTS關鍵字時,內層查詢語句不返回查詢的記錄。而是返回一個真假值。True或False #當返回True時,外層查詢語句將進行查詢;當返回值為False時,外層查詢語句不進行查詢 #department表中存在dept_id=203,Ture mysql> select * from employee where exists (select id from department where id=200); +----+----------+--------+------+--------+ | id | name | sex | age | dep_id | +----+----------+--------+------+--------+ | 1 | egon | male | 18 | 200 | | 2 | alex | female | 48 | 201 | | 3 | wupeiqi | male | 38 | 201 | | 4 | yuanhao | female | 28 | 202 | | 5 | nvshen | male | 18 | 200 | | 6 | xiaomage | female | 18 | 204 | +----+----------+--------+------+--------+ #department表中存在dept_id=205,False mysql> select * from employee where exists (select id from department where id=204); Empty set (0.00 sec)
索引
索引介紹: 資料庫中專門用於幫助用戶快速查找數據的一種數據結構.類似
於字典中的目錄,查找字典內容時可以根據目錄查到數據的存放位置,然後
直接獲取.
索引作用 約束和加速查找
常見的索引:
普通索引; 唯一索引; 主鍵索引;
聯合索引(多列) : 聯合主鍵索引 聯合唯一索引 聯合普通索引
有無索引的區別以及建立索引的目的
無索引: 從前往後逐條查詢
有索引: 創建索引的本質,就是創建額外的文件(某種格式存儲,查詢的時
候,先去額外的文件找,定好位置,再去原始表中直接查詢.)數據過多,對硬
盤也有損耗.
建立索引目的 :
額外的文件保存特殊的數據結構
查詢快, 但是插入更新刪除依然慢
創建索引後,必須命中索引才能有效
hash索引和BTree索引 (1)hash類型的索引:查詢單條快,範圍查詢慢 (2)btree類型的索引:b+樹,層數越多,數據量指數級增長(我們就用它,因為innodb預設支持它)
普通索引 作用:僅有一個加速查找
創建表+普通索引
create table userinfo( nid int not null auto_increment primary key, name varchar(32) not null, email varchar(64) not null, index ix_name(name)
#index創建索引目錄 ix_name表示創建的索引名字 (name)表示為哪個欄位創建索引 );
普通索引
create index 索引的名字 on 表名(列名)
單獨為某一表的某一欄位創建普通索引
刪除索引
drop index 索引的名字 on 表名
查看索引
show index from 表名
唯一索引
功能 : 加速查找 唯一約束(可含null)
create table userinfo( id int not null auto_increment primary key, name varchar(32) not null, email varchar(64) not null, unique index ix_name(name) );
唯一索引: create unique index 索引名 on 表名(列名)
刪除唯一索引 : drop index 索引名 on 表名;
主鍵索引
(主鍵查找類似於 not null + unique 不為空且唯一)
功能:加速查找 唯一約束(不含null)
創建表+主鍵索引
create table userinfo( id int not null auto_increment primary key, name varchar(32) not null, email varchar(64) not null, unique index ix_name(name) ) or create table userinfo( id int not null auto_increment, name varchar(32) not null, email varchar(64) not null, primary key(nid), unique index ix_name(name) )
主鍵索引 alter table 表名 add primary key(列名);
刪除主鍵索引
alter table 表名 drop primary key;
alter table 表名 modify 列名 int, drop primary key;
組合索引
組合索引是將n個列組合成一個索引,進行查詢,並不是採用n個列的各個
單列索引,進行查找,而是統一採用最左首碼規則查找.查找時採用最左面的
索引與後面的索引倆倆結合查找,最左面的索引不同,組合索引的效率也會不同.
其應用場景為: 頻繁的同時使用n列來進行查詢,如 :
where name='alex' and email='[email protected]'.
create index 索引名 on 表名(列名1,列名2);
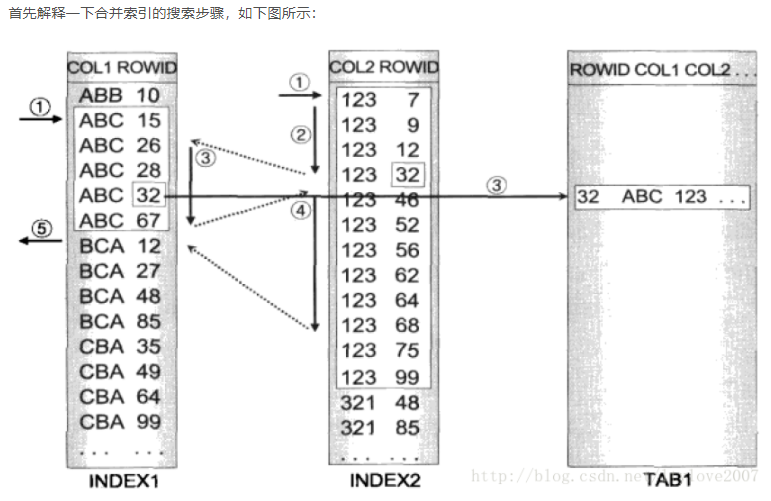
組合索引總和保存了col1和col2的數據,他不需要在2個索引表之間跳轉,所以速度會更快,組合索引
的搜索步驟如下

索引名詞(非正規SQL名稱)
#覆蓋索引:在索引文件中直接獲取數據 例如: select name from userinfo where name = 'alex50000'; #索引合併:把多個單列索引合併成使用 例如: select * from userinfo where name = 'alex13131' and id = 13131;
如下圖索引合併,需要反覆在倆個索引表間進行跳轉,造成速度慢的原因之一,假設col1='ABC'的數
據有5行,滿足col2=123的數據有1000行,最壞的情況(那5行在col2的1000行最後面) 需要掃描完col2的
1000行才能找到需要的數據,並不能達到快速查找的目的.
正確使用索引的情況
資料庫表中添加索引後確實會讓查詢速度飛起,但是前提必須是正確的使
用索引來查詢,如果以錯誤的方式使用,則即使建立索引也會不奏效.
使用索引,必須:
創建索引-->命中索引-->正確使用索引
測試:


#1. 準備表 create table userinfo( id int, name varchar(20), gender char(6), email varchar(50) ); #2. 創建存儲過程,實現批量插入記錄 delimiter $$ #聲明存儲過程的結束符號為$$ create procedure auto_insert1() BEGIN declare i int default 1; while(i<3000000)do insert into userinfo values(i,concat('alex',i),'male',concat('egon',i,'@oldboy')); set i=i+1; end while; END$$ #$$結束 delimiter ; #重新聲明分號為結束符號 #3. 查看存儲過程 show create procedure auto_insert1\G #4. 調用存儲過程 call auto_insert1(); - like '%xx' select * from userinfo where name like '%al'; - 使用函數 select * from userinfo where reverse(name) = 'alex333'; - or select * from userinfo where id = 1 or email = 'alex122@oldbody'; 特別的:當or條件中有未建立索引的列才失效,以下會走索引 select * from userinfo where id = 1 or name = 'alex1222'; select * from userinfo where id = 1 or email =


