
[TOC]### 操作系統理論####站在馮諾依曼角度,理解操作系統定位管理和控制電腦硬體與軟體資源的電腦程式馮諾伊曼(存儲程式原理)1. 馮諾伊曼體系的存儲器指的是記憶體2. 不考慮緩存的情況,CPU只能對記憶體進行操作,不能訪問外設(輸入或輸出設備)3. 外設(輸入輸出設備)如果想輸入輸出數據也... ...
目錄
操作系統理論
站在馮諾依曼角度,理解操作系統定位
管理和控制電腦硬體與軟體資源的電腦程式
馮諾伊曼(存儲程式原理)
馮諾伊曼體系的存儲器指的是記憶體
不考慮緩存的情況,CPU只能對記憶體進行操作,不能訪問外設(輸入或輸出設備)
外設(輸入輸出設備)如果想輸入輸出數據也只能寫入記憶體或從記憶體中讀取
所有設備只能直接和記憶體打交道
站在管理角度,理解操作系統[先描述再組織]
描述:管理軟體的軟體
組織:如何管理軟體?
操作系統是最基本的系統軟體,它控制著電腦所有的資源並提供應用程式開發的介面
站在應用者的角度,理解操作系統
從程式員角度看,操作系統是將程式員從複雜的硬體控制中解脫出來,併為軟體開發者提供了一個虛擬機,從而能更方便的進行程式設計
從一般用戶角度看,操作系統為他們提供了一個良好的交互界面,使得他們不必瞭解有關硬體和系統軟體的細節,就能方便地使用電腦
站在操作系統角度,理解系統調用介面
操作系統作為系統軟體,它的任務是為用戶的應用程式提供良好的運行環境。因此,由操作系統內核提供一系列內核函數,通過一組稱為系統調用的介面提供給用戶使用。系統調用的作用是把應用程式的請求傳遞給系統內核,然後調用相應的內核函數完成所需的處理,最終將處理結果返回給應用程式。因此,系統調用是應用程式和系統內核之間的介面
站在操作系統角度,理解操作系統外殼程式定位與作用(Linux shell)
在操作系統之上提供的一套命令解釋程式叫做外殼程式(shell)
外殼程式是操作員與操作系統交互的界面,操作系統再負責完成與機器硬體的交互。
所以操作系統可成為機器硬體的外殼,shell命令解析程式可稱為操作系統的外殼。
自定義網站/動畫/圖片/flash等、可添加統計代碼、自定義限制運行時間,限制操作等、自定義公告內容、到時自動運行、設置開機啟動、隱藏執行‘、hosts修改、設置主頁
對比系統調用,理解庫函數
一般而言,跟內核功能與操作系統特性緊密相關的服務,由系統調用提供;
具有共通特性的功能一般需要較好的平臺移植性,故而由庫函數提供。
庫函數與系統調用在功能上相互補充:
如進程間通信資源的管理,進程式控制制等功能與平臺特性和內核息息相關,必須由系統調用來實現。
文件 I/O操作等各平臺都具有的共通功能一般採用庫函數,也便於跨平臺移植。
某些情況下,庫函數與系統調用也有交集:
如庫函數中的I/O操作的內部實現依然需要調用系統的I/O方能實現。- 庫函數與系統調用主要區別:
所有 C 函數庫是相同的,而各個操作系統的系統調用是不同的。
函數庫調用是調用函數庫中的一個程式,而系統調用是調用系統內核的服務。
函數庫調用是與用戶程式相聯繫,而系統調用是操作系統的一個進入點
函數庫調用是在用戶地址空間執行,而系統調用是在內核地址空間執行
函數庫調用的運行時間屬於用戶時間,而系統調用的運行時間屬於系統時間
函數庫調用屬於過程調用,開銷較小,而系統調用需要切換到內核上下文環境然後切換回來,開銷較大
在C函數庫libc中大約 300 個程式,在 UNIX 中大約有 90 個系統調用
函數庫典型的 C 函數:system, fprintf, malloc,而典型的系統調用:chdir, fork, write, brk
進程基本概念(重點)
進程概念(PCB[task_struct])
基本概念:程式執行的一個實例,正在運行的程式
基於內核:但當分配系統資源(CPU時間、記憶體)的實體
基於PCB(Linux下稱為task_struct):task_struct是一種數據結構,他被裝載到RAM里並包含進程信息(信息如下)
1. 標示符:區別和其他進程的唯一標識符號
2. 狀態:任務狀態、退出代碼、退出信號
3. 優先順序:相對其他進程的優先順序
4. 程式計數器:程式中即將被執行的下一條指令
5. 記憶體指針:包括程式代碼和進程相關的數據指針,還有和其他進程共用記憶體的指針
6. 上下文數據:進程執行時處理器的寄存器中的數據
7. I/O狀態信息:包括I/O顯示的請求、分配給I/O的設備、被進程使用的文件列表
8. 記賬信息:可能包括處理器時間總和,使用的時鐘數總和,時間限制,記賬號
進程和程式有什麼區別
進程是程式的一次執行過程,是動態概念,程式是一組有序的指令集和,是靜態概念
進程是暫時的,是程式在數據集上的一次執行,可創建可撤銷,程式是永存的
進程具有併發行,程式沒有
進程是競爭電腦資源的最小單位,程式不是
進程與程式不是一一對應,多個進程可執行一個程式,一個程式可執行多個程式
進程標識,進程間關係
- 進程標識:進程ID,簡稱PID,是大多數操作系統內核用於唯一標識進程的數值
PID的數值是非負整數
每個進程都有唯一的一個PID
PID可以簡單地表示為主進程表中的一個索引
當某一進程終止後,其PID可以作為另一個進程的PID
調度進程的PID固定為0,他按一定原則把處理機分配給進程使用
初始化進程的PID固定為1,他是Linux系統中其他進程的祖先,是進程的最終控制者
每個進程都有六個重要的ID:進程ID,父進程ID,有效用戶ID,有效組ID,實際用戶ID,實際組ID
獲取各類ID的函數 #include<sys/types.h> #include<unistd.h> void getpid(void)//返回值:進程ID void getppid(void)//返回值:父進程ID void getpid(void)//返回值:進程ID void getuid(void)//返回值:實際用戶進程ID void geteuid(void)//返回值:有效用戶進程ID void getgid(void)//返回值:實際組進程ID void getegid(void)//返回值:有效組進程ID進程狀態
進程在運行中的幾種運行狀態
創建狀態:進程在創建是需要需要申請一個新的PCB,並將控制和管理進程的信息放在PCB裡面,從而完成資源分配。如果創建工作無法完成(比如資源無法滿足)就無法被調度運行。
就緒狀態:進程已經準備好了,已經分配到所需資源,只要分配到PCB上就能立即運行。(此狀態允許父進程終止子進程)
執行狀態:處於就緒狀態的進程被調度後就進入到執行狀態
阻塞狀態:正在執行的程式由於受到某些事件(IO請求/申請緩存區失敗)的影響而暫時無法運行,進程受到阻塞。在滿足條件時進程進入就緒狀態等待被調度。(此狀態允許父進程終止子進程)
終止狀態:進程結束,或出現錯誤,或被系統終止,進入終止狀態,無法再執行
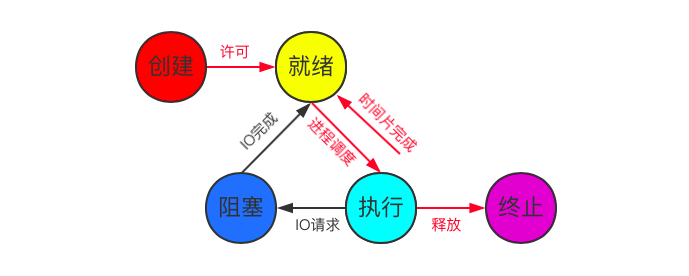 

Linux下的進程狀態(R、S、D、T、Z、X)
R(可執行)狀態:並比意味著進程一定在運行中,它表明要麼在運行中,要麼在運行隊列裡面
S(睡眠)狀態:意味著進程在等待事件完成(這裡的睡眠有時候也叫做可中斷睡眠)
D(不可中斷睡眠)狀態:在這個狀態的進程通常會等待IO結束
T(暫停)狀態:可以發送信號SIGSTOP給進程從而來停止進程,這個進程可以通過SIGCONT信號讓進程繼續運行
Z(僵屍)狀態:該進程在其父進程沒有讀取到子進程退出返回的代碼時就退出了,該進程就進入了僵屍狀態。僵屍狀態會以終止的狀態保持在進程表中,並一直等待父進程讀取退出狀態碼
X(死亡/退出)狀態:這個狀態只是一個返回狀態,在任務列表中看不到這個狀態
進程優先順序
CPU資源分配的先後順序,就是進程的優先權
優先權高的進程先執行,配置優先權對多任務的Linux環境很有用,可以提高系統的性能
還可以把某個進程指定到某個CPU上,可以提高系統整體的性能
進程創建
fork函數
#include<unistd.h>
pid_t fork(void)
返回值:自進程返回0,父進程返回子進程ID,出錯返回-1。- 進程調用fork函數時,當控制轉移到內核中fork代碼後,內核做的事情有:
分配新的數據塊和數據結構給子進程
將父進程的數據結構的部分內容拷貝到子進程中
將子進程添加到系統進程列表
fork返回。開始調度器調度
fork之前,父進程獨立執行,fork之後,父子進程兩個執行流分別執行,誰先誰後不確定,完全由調度器決定的。
通常情況下,父子代碼共用,父子在不寫入的情況下都是共用的。當有一方試圖寫入時,便以寫實拷貝各自一份副本進行寫入。
錯誤碼EAGAIN表示達到進程數上線,ENOMEM表示沒有足夠空間給一個新進程分配
所有由父進程打開的文件描述符都被覆制到子進程中,父子進程中相同編號的文件描述符在內核中指向同一個file結構體,也就是說file結構體的引用計數要增加
- fork常用的場景:
父進程希望複製自己,父子進程同時執行不同代碼段(比如:父進程等待客戶端請求,生成子進程來處理請求)
一個進程要執行不同的程式(比如:子進程從fork返回後調用exec函數)
vfork函數
#include<unistd.h>
pid_t vfork(void)
返回值:自進程返回0,父進程返回子進程ID,出錯返回-1。產生一個子進程,但父子進程共用數據段(共用地址空間)
vfork保證子進程先運行,等到子進程調用exec或者exit之後父進程才開始執行
如果在調用exec或exit之前,子進程依賴於父進程進一步動作,則會造成死鎖
改變子進程變數的值,也是的父進程中的值發生改變,如果想改變共用數據段中的變數值,應該先拷貝父進程
fork和vfork的區別
fork產生子進程不共用地址空間,vfork產生子進程共用地址空間
fork不阻塞,父子進程可以同時執行,vfork阻塞,父進程要等待子進程執行完才能執行
fork後子進程和父進程的執行順序不一定,vfork後子進程先執行,待到子進程退出後父進程才開始執行
進程等待
為什麼要等待?
1.子進程退出,如果父進程不管不顧,可能造成僵屍問題,造成記憶體泄漏
2.一旦變成僵屍狀態,kill -9都無能為力,因為沒有誰可以殺死一個死去了的進程
3.父進程需要知道子進程完成任務的情況(對錯與否,有沒有異常退出等)
4.父進程需要通過進程等待的方式回收子進程的資源,獲取退出信息
怎麼等待?(兩個介面函數)
wait系統調用
#include<sys/types.h> #include<sys/wait.h> pid_t wait(int* status)參數:status輸出型參數,整型指針,指向的空間存放的是子進程退出的狀態,獲取子進程狀態,不關心可以設置為NULL
返回值:pid_t類型,如果返回值大於0,說明等待成功,返回的是子進程的ID,可以通過status查看子進程的退出狀態;如果返回值等於-1,則說明等待失敗(可能wait的進程本身沒有子進程)
該方式為阻塞式等待,父進程什麼都不做在等待子進程退出,如果沒有子進程退出,父進程會一直等;如果父進程收到SIGCHLD信號,該函數就會立馬返回立馬清理。
--
waitpid系統調用
#include<sys/types.h> #include<sys/wait.h> pid_t waitpid(pid_t pid, int* status, int options)參數:pid表示要等待的是哪個進程,status仍然是個輸出型參數,存放子進程的退出碼,options是一個選項,如果options設置為0,那麼這個函數就是阻塞式等待,如果設置為WNOHANG,則函數為非阻塞式等待(發現已經沒有退出的子進程可以收集)
返回值:返回值大於0,等待成功,返回子進程的id,返回值等於0,表示發現等待的子進程沒有退出,返回值等於-1,調用失敗
如果參數pid設置為-1,則表示等待任意子進程,和wait等效
--
wait和waitpid的區別?
- wait是阻塞式等待,waitpid可自行選擇(options為0阻塞,options為WNOHANG為非阻塞)
- wait等待的是任意子進程(等到誰就是誰),waitpid等待的是參數pid傳進來的確定子進程
進程程式替換
替換原理
fork創建子進程執行的是和父進程相同的程式(也有可能是某個分支),通常fork出的子進程是為了完成父進程所分配的任務,所以子進程通常會調用一種exec函數(六種中的任何一種)來執行另一個任務。當進程調用exec函數時,當前用戶空間的代碼和數據會被新程式所替換,該進程就會從新程式的啟動歷程開始執行。在這個過程中沒有創建新進程,所以調用exec並沒有改變進程的id。替換過程(圖解)
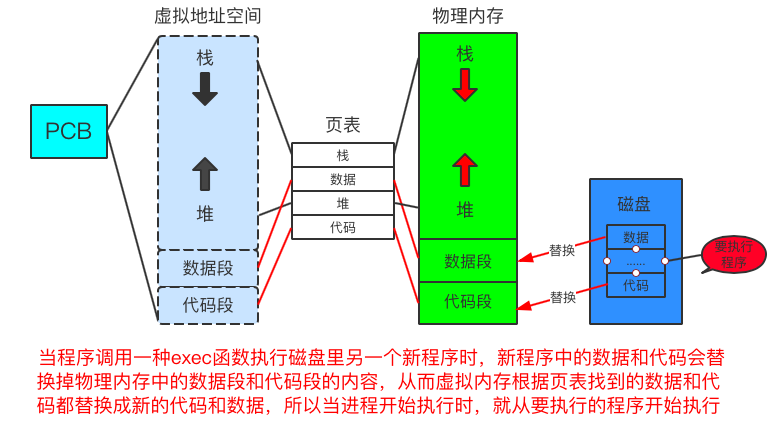 
替換函數(exec簇)---六種
#include<unistd.h>
int execl(const char* path, const char* arg, ···)
int execlp(const char* file, const char* arg, ···)
int execle(const char* path, const char* arg, ···, char* const envp[])
int execv(const char* path, char* const argv[])
int execvp(const char* file, char* const argv[])
int execve(const char* path, char* const argv[], char* const envp[])函數特點
- 這些函數如果調用成功,則載入的新程式從啟動代碼開始執行,不再返回
- 如果調用出錯返回-1
- exec系列函數成功調用沒有返回值,調用失敗才有返回值
命名規律
- l(list):表示參數採用列表
- v(vector):表示參數採用數組
- p(path):自動搜索環境變數PATH
- e(env):自己維護環境變數(自己組裝環境變數)
| 函數名 | 參數格式 | 是否帶路徑 | 是否使用當前環境變數 |
|---|---|---|---|
| execl | 參數列表 | 否 | 是 |
| execlp | 參數列表 | 是 | 是 |
| execle | 參數列表 | 否 | 否 |
| execv | 參數數組 | 否 | 是 |
| execvp | 參數數組 | 是 | 是 |
| execve | 參數數組 | 否 | 否 |
六個函數之間的關係
事實上,只有execve是系統調用,其他五個最終都調用execve。
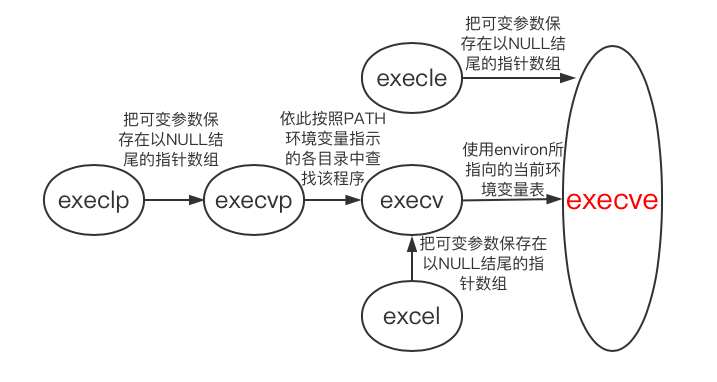 
- 拓展:寫簡易shell的需要迴圈的步驟
- 獲取命令行
- 解析命令行
- 創建子進程(fork)
- 進行程式替換---替換子進程(execve)
- 父進程等待子進程退出(wait)
進程終止
終止方式
1.正常終止,結果正確
2.正常終止,結果錯誤
3.異常終止
終止方法
1.正常終止(可以通過echo $?查看進程退出碼)- 調用_exit函數
#include <unistd.h> void _exit(int status) 參數:status定義了進程終止狀態,父進程通過wait來獲取 註意:雖然status是int,但只有低八位可以被父進程使用 證明:_exit(-1)時,執行echo $?返回值255- 調用exit函數
#include <unistd.h> void exit(int status) exit函數做了以下事情,最終調用了_exit函數: 1. 執行用戶通過ataxia或on_exit定義的清理函數 2. 沖刷緩存,將所有緩存數據寫入,並且關閉所有打開的流 3. 調用_exit函數 
- main函數返回(return退出)
return是一種更常見的退出進程的方法 main函數運行時,exit函數會將main返回值當作參數 return n則相當於exit(n)。2.異常退出
ctrl + c 信號終止
進程地址空間
對於一個進程空間分佈圖如下:
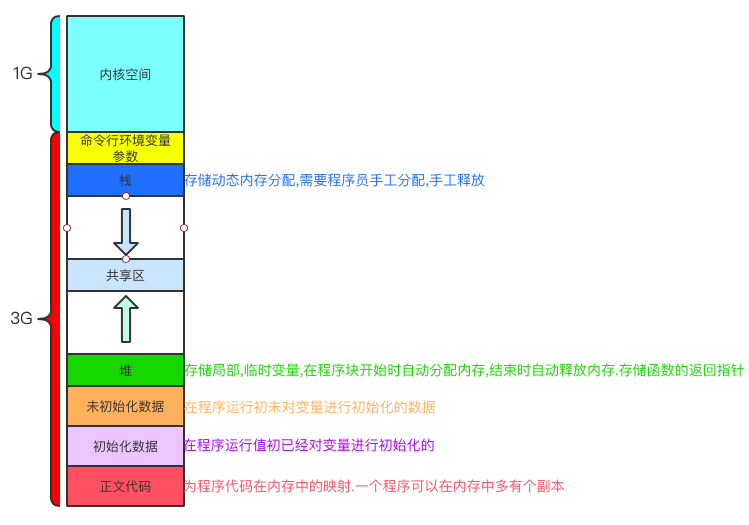 
引子:猜猜下麵輸出結果,為什麼呢?
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_val = 0;
int main() {
pid_t id = fork();
if(id < 0){
perror("fork");
return 0; }
else if(id == 0){ //child
printf("child[%d]: %d : %p\n", getpid(), g_val, &g_val);
}else{ //parent
printf("parent[%d]: %d : %p\n", getpid(), g_val, &g_val);
}
sleep(1);
return 0;
}
輸出結果:
parent[2995]: 0 : 0x80497d8
child[2996]: 0 : 0x80497d8由上可以發現,父子進程變數值和地址一模一樣,因為子進程是以父進程為模版,並且父子進程都沒有對變數進行修改
修改一下代碼(如下),看看結果
```
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_val = 0;
int main() {
pid_t id = fork();
if(id < 0){
perror("fork");
return 0; }
else if(id == 0){ //child
printf("child[%d]: %d : %p\n", getpid(), g_val, &g_val);
}else{ //parent
printf("parent[%d]: %d : %p\n", getpid(), g_val, &g_val);
}
sleep(1);
return 0;
}
輸出結果:
child[3046]: 100 : 0x80497e8
parent[3045]: 0 : 0x80497e8
我們發現,父子進程,輸出地址是一致的,但是變數內容不一樣!
```結合上面兩個例子我們可以總結出以下結論:
1. 變數內容不一樣,所以⽗子進程輸出的變數絕對不是同⼀個變數
2. 但地址值是⼀樣的,則該地址絕對不是物理地址
3. 在Linux地址下,這種地址叫做虛擬地址
4. 我們在⽤C/C++語⾔言所看到的地址,全部都是虛擬地址,物理地址,⽤戶一概看不到,由OS統⼀管理早期記憶體管理原理:
- 要運⾏一個程式,會把這些程式全都裝⼊記憶體
- 當電腦同時運⾏多個程式時,必須保證這些程式用到的記憶體總量要⼩於電腦實際物理記憶體的⼤⼩問題:
- 進程地址空間不隔離。由於程式都是直接訪問物理記憶體,所以惡意程式可以隨意修改別的進程的記憶體數據,以達到破壞的目的
- 記憶體使⽤效率低。在 A 和 B 都運⾏的情況下,如果⽤戶⼜運⾏了程式 C ,⽽程式 C 需要 15M ⼤ ⼩的記憶體才能運⾏,而此時系統只剩下 4M 的空間可供使⽤,所以此時系統必須在已運⾏的程式中 選擇一個將該程式的數據暫時拷⻉到硬碟上,釋放出部分空間來供程式 C 使⽤,然後再將程式 C 的數據全部裝入記憶體中運⾏
- 程式運⾏的地址不確定。當記憶體中的剩餘空間可以滿足程式 C 的要求後,操作系統會在剩餘空間中隨機分配一段連續的 20M ⼤⼩的空間給程式 C 使⽤,因為是隨機分配的,所以程式運⾏的地址是不確定的,這種情況下,程式的起始地址都是物理地址,⽽而物理地址都是在載入之後才能確定。
由於以上機制存在問題,於是後來使用分段來解決這些問題
分段
- 在編寫代碼的時候,只要指明瞭所屬段,代碼段和數據段中出現的所有的地址,都是從0零開始,映射關係完全由操作系統維護
- CPU將記憶體分割成了不同的段,於是指令和數據的有效地址並不是真正的物理地址⽽是相對於段⾸地址的偏移地址
解決問題:
- 因為段寄存器的存在,使得進程的地址空間得以隔離,越界問題很容易被判定出來
- 實際代碼和數據中的地址,都是偏移量,所以第一條指令可以從0地址開始,系統會⾃動進⾏轉化映射,也就解決了程式運⾏的地址不確定的問題。
- 可是,分段並沒有解決性能問題,在記憶體空間不⾜的情況下,依舊要換⼊喚出整個程式或者整個段,⽆疑要造成記憶體和硬碟之間拷⻉⼤量數據的情況,進⽽導致性能問題。
分段仍然存在一些問題,於是引進了分頁和虛擬地址概念
分頁&虛擬地址空間
頁表:實現從頁號到物理塊號的地址映射
虛擬記憶體基本思想:每個進程有用獨立的邏輯地址空間,記憶體被分為大小相等的多個塊,稱為頁(Page).每個頁都是一段連續的地址。對於進程來看,邏輯上貌似有很多記憶體空間,其中一部分對應物理記憶體上的一塊(稱為頁框,通常頁和頁框大小相等),還有一些沒載入在記憶體中的對應在硬碟上
創建進程,虛擬地址和物理地址之間的映射關係
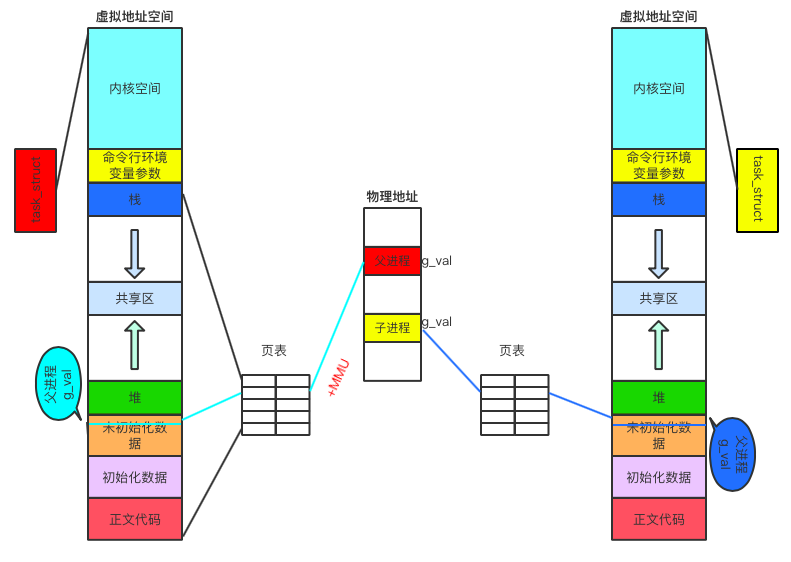 

上面的圖說明:同一個變數,地址相同,其實是虛擬地址相同,內容不同其實是被映射到了不同的物理地址!過程:當訪問虛擬記憶體時,會訪問MMU(記憶體管理單元)去匹配對應的物理地址,而如果虛擬記憶體的頁並不存在於物理記憶體中,會產生缺頁中斷,從磁碟中取得缺的頁放入記憶體,如果記憶體已滿,還會根據某種演算法將磁碟中的頁換出。(MMU中存儲頁表,用來匹配虛擬記憶體和物理記憶體)
二級頁表:因為頁表中每個條目是4位元組,現在的32位操作系統虛擬地址空間是
2^32次方,假設每頁分為4k,也需(2^32/(4*2^10))*4=4M的空間,為每個進程建立一個4M的頁表並不明智。因此在頁表的概念上進行推廣,產生二級頁表,雖然頁表條目沒有減少,但記憶體中可以僅僅存放需要使用的二級頁表和一級頁表,大大減少了記憶體的使用。缺頁中斷:虛擬記憶體的頁並不存在於物理記憶體中,會產生缺頁中斷。處理中斷地址轉換➕更新(地址轉換:有空閑塊兒,調入頁面,沒有利用置換演算法替換出去一個;更新頁表,重啟該命令,檢索頁表,命中物理塊兒,運算得出物理地址)
拓展
CPU把虛擬地址轉換成物理地址:一個虛擬地址,大小4個位元組(32bit),分為3個部分:第22位到第31位這10位(最高10位)是頁目錄中的索引,第12位到第21位這10位是頁表中的索引,第0位到第11位這12位(低12位)是頁內偏移。一個一級頁表有1024項,虛擬地址最高的10bit剛好可以索引1024項(2的10次方等於1024)。一個二級頁表也有1024項,虛擬地址中間部分的10bit,剛好索引1024項。虛擬地址最低的12bit(2的12次方等於4096),作為頁內偏移,剛好可以索引4KB,也就是一個物理頁中的每個位元組。頁面替換演算法:物理記憶體是極其有限的,當虛擬記憶體所求的頁不在物理記憶體中時,將需要將物理記憶體中的頁替換出去,選擇哪些頁替換出去就顯得尤為重要。
最佳置換演算法(Optimal Page Replacement Algorithm):將未來最久不使用的頁替換出去,這聽起來很簡單,但是無法實現。但是這種演算法可以作為衡量其它演算法的基準。
最近不常使用演算法(Not Recently Used Replacement Algorithm):這種演算法給每個頁一個標誌位,R表示最近被訪問過,M表示被修改過。定期對R進行清零。這個演算法的思路是首先淘汰那些未被訪問過R=0的頁,其次是被訪問過R=1,未被修改過M=0的頁,最後是R=1,M=1的頁。
先進先出頁面置換演算法(First-In,First-Out Page Replacement Algorithm):淘汰在記憶體中最久的頁,這種演算法的性能接近於隨機淘汰。並不好。
改進型FIFO演算法(Second Chance Page Replacement Algorithm):這種演算法是在FIFO的基礎上,為了避免置換出經常使用的頁,增加一個標誌位R,如果最近使用過將R置1,當頁將會淘汰時,如果R為1,則不淘汰頁,將R置0.而那些R=0的頁將被淘汰時,直接淘汰。
時鐘替換演算法(Clock Page Replacement Algorithm):雖然改進型FIFO演算法避免置換出常用的頁,但由於需要經常移動頁,效率並不高。因此在改進型FIFO演算法的基礎上,將隊列首位相連形成一個環路,當缺頁中斷產生時,從當前位置開始找R=0的頁,而所經過的R=1的頁被置0,並不需要移動頁。
最久未使用演算法(LRU Page Replacement Algorithm):LRU演算法的思路是淘汰最近最長未使用的頁。這種演算法性能比較好,但實現起來比較困難。
進程間通信
一組編程介面,讓程式員能夠協調不同的進程,使之能在一個操作系統里同時運行,並能夠相互傳遞交換信息
為什麼要通信(重點)
數據傳輸:一個進程需要將它的數據發送到另一個進程
資源共用:多個進程之間需要共用資源
事件通知:一個進程要向另一個或者一組進程發送消息,通知它(們)發生的事件(比如進程終止要通知父進程)
進程式控制制:有些進程需要完全控制另一個進程(如Debug進程),此時,控制進程希望能夠攔截它想控制的進程的所有的陷入和異常,並能夠及時知道其狀態的改變
怎麼通信(主要三種方式),通信本質(重點)
管道(Unix中最古老的進程間通信的方式)
我們把一個進程連接到另一個進程的一個數據流稱為管道
匿名管道(通常就叫管道)
創建方法 #include <unistd.h> int pipe(int fd[2]) 參數:文件描述符數組,fd[0]表示讀端,fd[1]表示寫端 返回值:成功返回0,失敗返回錯誤代碼特點:
1. 單向傳輸(單工),只能在父子進程間或兄弟進程間使用
2. 管道是臨時對象
3. 管道和文件的使用方法類似,都能使用read、write、open等普通IO函數
4. 管道面向位元組流,即提供流式服務
5. 一般來講,管道生命周期隨進程,進程退出,管道釋放
6. 一般來講,內核會對管道操作進行同步與互斥
7. 本質上Linux上的管道是通過空文件夾實現的
8. 事實上,管道使用的文件描述符、文件描述符、文件指針最終都會轉化成系統內核中SOCKET描述符,都收到了SOCKET描述符的限制
9. 補充:Linux中,用兩個file數據結構來實現管道命名管道
特點:創建方法 $ mkfifo filename //命令行創建 int mkfifo(count char* filename, mode_t mode)//函數- 命名管道也是單向傳輸,但它可以在不相關的進程間使用
- 命名管道不是臨時對象,它們是文件系統真正的實體
- Linux下,在寫進程打開命名管道之前,必須處理讀進程對命名管道的打開,在寫進程寫數據之前,也必須處理處理讀進程對管道的讀
- 除了以上的特點與管道不同,其他的都是都與管道一樣,包括數據結構和操作
匿名管道和命名管道的區別?
答:匿名管道只能在父子進程間或兄弟進程間使用,命名管道可以在不相關的進程間使用;匿名管道是臨時對象,命名管道是文件系統真正的實體;匿名管道和命名管道打開和關閉方式不同。
管道的缺陷
- 管道讀數據的同時也將數據移除,所以管道不能對多個接收者廣播數據
- 管道中的數據被當作位元組流,所以無法識別信息的邊界
- 如果一個進程中有多個讀進程,寫進程無法發送到指定的讀進程,如果有多個寫進程,無法知道數據是哪一個發送的
系統IPC(System V IPC資源生命周期隨內核)
消息隊列
提供了一個由一個進程向另外一個進程發送一塊數據的方法
特點:
1. 消息隊列是隨內核,只有重啟和手動刪除才會被真正的刪除
2. 每個數據塊都被認為是有個類型,接受者進程接受的數據塊可以是不同類型值
3. 每個消息是有最大長度的上限的,每個消息隊列的位元組數也是有上限的,系統上消息隊列數也有上限
4. 可用於機器上的任何進程間通信消息隊列與管道的區別:
1. 提供有格式的位元組流,減少開發人員的工作量
2. 消息具有類型,實際應用中,可以當做優先順序使用
3. 消息隊列隨內核,生命周期比管道長,應用空間更大共用記憶體
由一個進程創建,其餘進程對這塊記憶體進行讀寫
特點:- 最快的IPC形式
- 進程間數據傳遞不再涉及到記憶體(不執行進入系統的內核調用來傳遞彼此的數據)
- Linux無法對共用記憶體進行同步,需要程式自己對共用記憶體做同步運算,這種運算很多時候就是通過信號量來實現的
信號量
主要用於同步與互斥
- 進程互斥
- 由於有些進程需要共用資源,而且需要互斥使用,所以個進程競爭使用這些資源,這種關係被稱為進程互斥
- 系統中某些進程一次只能被一個進程使用,稱這樣的資源為臨界資源或者互斥資源
- 在進程中涉及互斥資源的的程式段叫做臨界區
進程同步
多個進程需要配合完成同一個任務- 信號量和P、V原語
- 由Dijkstra提出
- 信號量
- 互斥:P、V在同一個進程
- 同步:P、V在不同的進程
- 信號量值的含義
- S>0:表示可用資源個數
- S=0:表示沒有可以用的資源,無等待進程
- S<0:表示等待隊列中有|S|個進程
- 進程互斥
套接字(socket)
TCP用主機的ip地址加上主機上的埠號作為TCP連接的端點,這種端點就叫做套接字或插口
用(IP地址:埠號)表示
- 特點:
- 是網路通信過程中端點的抽象表示,是支持TCP/IP的網路通信的基本操作單元
- 包含進行網路通信必須的五種信息:連接使用的協議、本地主機的IP地址、本地進程的協議埠、遠地主機的IP地址、遠地進程的協議埠
- 在所有提供了TCP/IP協議棧的操作系統都適用,且編程方法幾乎一樣
- 要通過Internet進行通信,至少需要一對套接字
進程與文件(重點)
進程打開文件的本質
當我們打開文件時,操作系統在記憶體中要創建相應的數據結構來描述目標文件。於是就有了file結構體。表⽰⼀個已經打開的文件對象。而進程執行open系統調⽤,所以必須讓進程和文件關聯起來。每個進程都有⼀個指針*files, 指向⼀張表files_struct,該表最重要的部分就是包涵一個指針數組,每個元素都是一個指向打開文件的指針!所以,本質上,文件描述符就是該數組的下標。所以,只要拿著文件描述符,就可以找到對應的文件。
文件描述符的本質
本質是數組元素的下標,每個進程都對應一張文件描述符表,該表可視為指針數組,給數組的元素指向文件表的一個元素,數組元素的下標就是大名鼎鼎的文件描述符
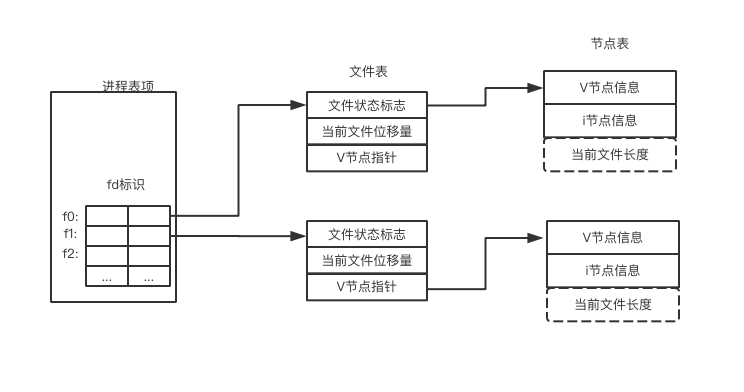 

圖詳解:
1.右側的表稱為i節點表,在整個系統中只有1張。該表可以視為結構體數組,該數組的一個元素對應於一個物理文件。
2.中間的表稱為文件表,在整個系統中只有1張。該表可以視為結構體數組,一個結構體中有很多欄位,其中有3個欄位比較重要:
file status flags 用於記錄文件被打開來讀的,還是寫的。其實記錄的就是open調用中用戶指定的第2個參數 current file offset 用於記錄文件的當前讀寫位置(指針)。正是由於此欄位的存在,使得一個文件被打開並讀取後, 下一次讀取將從上一次讀取的字元後開始讀取 v-node ptr 該欄位是指針,指向右側表的一個元素,從而關聯了物理文件。
3.左側的表稱為文件描述符表,每個進程有且僅有1張。該表可以視為指針數組,數組的元素指向文件表的一個元素。最重要的是:數組元素的下標就是大名鼎鼎的文件描述符。
4.open系統調用執行的操作:新建一個i節點表元素,讓其對應打開的物理文件(如果對應於該物理文件的i節點元素已經建立,就不做任何操作);新建一個文件表的元素,根據open的第2個參數設置file status flags欄位,將current file offset欄位置0,將v-node ptr指向剛建立的i節點表元素;在文件描述符表中,尋找1個尚未使用的元素,在該元素中填入一個指針值,讓其指向剛建立的文件表元素。最重要的是:將該元素的下標作為open的返回值返回。
5.這樣一來,當調用read(write)時,根據傳入的文件描述符,OS就可以找到對應的文件描述符表元素,進而找到文件表的元素,進而找到i節點表元素,從而完成對物理文件的讀寫。
文件描述符與C FILE*的關係,理解系統調用與庫函數
每個進程都有⼀個指針*files, 指向⼀張表files_struct,該表最重要的部分就是包涵一個指針數組,每個元素都是一個指向打開文件的指針,文件描述符就是該數組的下標。
系統調用與庫函數
可以認為,f#系列的函數(庫函數),都是對系統調⽤的封裝,方便⼆次開發。
站在系統角度,常見的文件操作介面的使用
open系統調用執行的操作:新建一個i節點表元素,讓其對應打開的物理文件(如果對應於該物理文件的i節點元素已經建立,就不做任何操作);新建一個文件表的元素,根據open的第2個參數設置file status flags欄位,將current file offset欄位置0,將v-node ptr指向剛建立的i節點表元素;在文件描述符表中,尋找1個尚未使用的元素,在該元素中填入一個指針值,讓其指向剛建立的文件表元素。最重要的是:將該元素的下標作為open的返回值返回。
read(write)時,根據傳入的文件描述符,OS就可以找到對應的文件描述符表元素,進而找到文件表的元素,進而找到i節點表元素,從而完成對物理文件的讀寫
open close read write lseek都屬於系統提供的接⼝,稱之為系統調⽤接⼝
文件描述符重定向的本質與操作
1.linux用文件描述符來標識每個文件對象,文件描述符是一個非負整數,可以唯一地標識會話中打開的文件,每個過程一次最多可以有9個文件描述符;
2.0=>STDIN=>標準輸入;1=>STDOUT=>標準輸出;2=>STDERR=>標準錯誤;
3.STDIN:STDIN文件描述符代表shell的標準輸入,對終端界面來說,標準輸入是鍵盤,在使用輸入重定向時(<),linux會用重定向指定的文件來替換標準輸入文件描述符,它會讀取文件並提取數據,如同它是在鍵盤上輸入的;
4.STDOUT:STDOUT文件描述符代表標準的shell輸出,在終端界面上,標準輸出就是終端顯示器,shell的所有輸出會被重定向到標準輸出中,也就是顯示器,在使用輸出重定向(>)時,linux會用重定向指定的文件來替換標準輸出文件描述符,>>表示追加到文件;
5.STDERR:STDERR文件描述符代表shell的標準錯誤輸出,預設情況下,STDERR文件描述符會和STDOUT文件描述符指向同樣的地方,即:錯誤消息也會輸出到顯示器輸出中,使用2>file,可以只將錯誤消息輸出至文件file中,使用&>file可將標準輸出和錯誤消息都重定向至文件file;
理解文件系統中inode的概念
概念:inode就是索引節點,它用來存放檔案及目錄的基本信息,包含時間、檔名、使用者及群組等
inode 是 UNIX 操作系統中的一種數據結構,其本質是結構體
在 Linux 中,索引節點結構存在於系統記憶體及磁碟,其可區分成 VFS inode 與實際文件系統的 inode。
VFS inode 作為實際文件系統中 inode 的抽象,定義了結構體 inode 與其相關的操作 inode_operations
Linux 中 VFS inode include/linux/fs.h struct inode { ... const struct inode_operations *i_op; // 索引節點操作 unsigned long i_ino; // 索引節點號 atomic_t i_count; // 引用計數器 unsigned int i_nlink; // 硬鏈接數目 ... } struct inode_operations { ... int (*create) (struct inode *,struct dentry *,int, struct nameidata *); int (*link) (struct dentry *,struct inode *,struct dentry *); int (*unlink) (struct inode *,struct dentry *); int (*symlink) (struct inode *,struct dentry *,const char *); int (*mkdir) (struct inode *,struct dentry *,int); int (*rmdir) (struct inode *,struct dentry *); ... }
Linux 中 VFS inode
- 每個文件存在兩個計數器:i_count 與 i_nlink,即引用計數與硬鏈接計數
- i_count 用於跟蹤文件被訪問的數量,而 i_nlink 則是上述使用 ls -l 等命令查看到的文件硬鏈接數
- 當文件被刪除時,則 i_nlink 先被設置成 0
- 文件的這兩個計數器使得 Linux 系統升級或程式更新變的容易
- 系統或程式可在不關閉的情況下(即文件 i_count 不為 0),將新文件以同樣的文件名進行替換,新文件有自己的 inode 及 data block,舊文件會在相關進程關閉後被完整的刪除
文件系統 ext4 中的 inode
ext4 中的 inode struct ext4_inode { ... __le32 i_atime; // 文件內容最後一次訪問時間 __le32 i_ctime; // inode 修改時間 __le32 i_mtime; // 文件內容最後一次修改時間 __le16 i_links_count; // 硬鏈接計數 __le32 i_blocks_lo; // Block 計數 __le32 i_block[EXT4_N_BLOCKS]; // 指向具體的 block ... };三個時間的定義可對應與命令 stat 中查看到三個時間
i_links_count 不僅用於文件的硬鏈接計數,也用於目錄的子目錄數跟蹤(目錄並不顯示硬鏈接數,命令 ls -ld 查看到的是子目錄數)
文件系統 ext3 對 i_links_count 有限制,其最大數為:32000(該限制在 ext4 中被取消)
理解軟硬鏈接及其區別
硬鏈接
概念:硬鏈接(hard link, 也稱鏈接)就是一個文件的一個或多個文件名,其中一個修改後,所有與其有硬鏈接的文件都一起修改了
特點
(1)文件有相同的 inode 及 data block
(2)只能對已存在的文件進行創建
(3)硬鏈接文件不占用存儲空間
(4)硬鏈接文件不能跨文件系統
(5)不能對目錄文件進行創建硬鏈接操作
(6)硬鏈接只能引用同一文件系統中的文件。它引用的是文件在文件系統中的物理索引(也稱為 inode)
(7)移動或刪除原始文件時,硬鏈接不會被破壞,因為它所引用的是文件的物理數據而不是文件在文件結構中的位置
(8)硬鏈接的文件不需要用戶有訪問原始文件的許可權,也不會顯示原始文件的位置,這樣有助於文件的安全
(9)刪除的文件有相應的硬鏈接,那麼這個文件依然會保留,直到所有對它的引用都被刪除
軟鏈接
概念:軟鏈接又叫符號鏈接,這個文件包含了另一個文件的路徑名。可以是任意文件或目錄,可以鏈接不同文件系統的文件
特點
(1)軟鏈接有自己的文件屬性及許可權等
(2)可對不存在的文件或目錄創建軟鏈接(鏈接文件可以鏈接不存在的文件,這就產生一般稱之為”斷鏈”的現象)
(3)軟鏈接可交叉文件系統
(4)軟鏈接可對文件或目錄創建
(5)創建軟鏈接時,鏈接計數 i_nlink 不會增加
(6)鏈接文件可以迴圈鏈接自己,類似於編程語言中的遞歸。
(7)刪除軟鏈接並不影響被指向的文件
(8)軟鏈接文件只是被指向的源文件的一個標記,當刪除了源文件後,鏈接文件不能獨立存在,雖然仍保留文件名,但卻不能查看軟鏈接文件的內容了,成為了死鏈接
(9)被指向路徑文件被重新創建,死鏈接可恢復為正常的軟鏈接
硬鏈接和軟鏈接的區別
- 硬鏈接文件有相同的 inode 及 data block;軟連接文件有自己的 inode 及 data block 等文件屬性
- 硬鏈接文件只能對已存在的文件進行創建;軟鏈接文件可對不存在的文件或目錄創建軟鏈接
- 硬鏈接不可交叉文件系統;軟鏈接可交叉文件系統
- 硬鏈接不可對文件或目錄創建;軟鏈接可對文件或目錄創建
- 移動或刪除原始文件時,硬鏈接不會被破壞;刪除了源文件後,鏈接文件不能獨立存在
- 軟鏈接文件相比硬鏈接文件占用存儲空間更大
理解動態與靜態庫
靜態庫
概念
- 靜態庫是指在我們的應用中,有一些公共代碼是需要反覆使用,就把這些代碼編譯為“庫”文件;在鏈接步驟中,連接器將從庫文件取得所需的代碼,複製到生成的可執行文件中的這種庫
特點
可執行文件中包含了庫代碼的一份完整拷貝
靜態庫的代碼是在編譯過程中被載入程式中
缺點
- 就是被多次使用就會有多份冗餘拷貝
動態庫(動態鏈接庫)
概念
- 動態鏈接提供了一種方法,使進程可以調用不屬於其可執行代碼的函數
特點
函數的可執行代碼位於一個 DLL 中,該 DLL 包含一個或多個已被編譯、鏈接並與使用它們的進程分開存儲的函數
DLL 還有助於共用數據和資源
多個應用程式可同時訪問記憶體中單個DLL 副本的內容
DLL 是一個包含可由多個程式同時使用的代碼和數據的庫,Windows下動態庫為.dll尾碼,在linux下為.so尾碼
Linux下靜態庫和動態庫區別
命名上:靜態庫文件名的命名方式是“libxxx.a”,庫名前加”lib”,尾碼用”.a”,“xxx”為靜態庫名;動態庫的命名方式與靜態庫類似,首碼相同,為“lib”,尾碼變為“.so”。所以為“libmytime.so”
鏈接上:靜態庫的代碼是在編譯過程中被載入程式中;動態庫在編譯的時候並沒有被編譯進目標代碼,而是當你的程式執行到相關函數時才調用該函數庫里的相應函數
更新上:如果所使用的靜態庫發生更新改變,你的程式必須重新編譯;動態庫的改變並不影響你的程式,動態函數庫升級比較方便
當同一個程式分別使用靜態庫,動態庫兩種方式生成兩個可執行文件時,靜態鏈接所生成的文件所占用的記憶體要遠遠大於動態鏈接所生成的文件
記憶體上:靜態庫每一次編譯都需要載入靜態庫代碼,記憶體開銷大;系統只需載入一次動態庫,不同的程式可以得到記憶體中相同的動態庫的副本,記憶體開銷小
靜態庫和程式鏈接有關和程式運行無關;動態庫和程式鏈接無關和程式運行有關
進程與線程(重點)
站在操作系統管理角度,理解什麼是線程
線程是不擁有獨立資源空間的程式執行流的最小單位
站在進程地址空間角度,理解什麼是線程
線程是進程中的實體,是進程內部的控制序列,和該進程內的其他線程共用地址空間和資源
站在執行流角度,理解什麼是線程
線程是程式中一個單一的順序控制流程,是程式執行流的最小單位
如何理解線程是進程內部的一個執行分支
- 原因
60年代,在OS中能擁有資源和獨立運行的基本單位是進程,然而隨著電腦技術的發展,進程出現了很多弊端,由於進程是資源擁有者,創建、撤消與切換存在較大的時空開銷,因此需要引入輕型進程;
對稱多處理機(SMP)出現,可以滿足多個運行單位,而多個進程並行開銷過大,因此在80年代,出現了能獨立運行的基本單位——線程(Threads)
- 進程就是一棵樹,我們的線程就是其中的一個個分支,沒有了線程,進程並不能執行任何操作。我們進程的具體操作最後還是分配給每一個線程來執行。相對於線程,我們甚至可以把進程理解為線程的一個容器,它代表線程來接受分配到的資源,為線程提供執行代碼,所以進程是資源分配的基本單位。
進程與線程有什麼區別
Linux下線程有什麼特點
線程中的實體基本上不擁有系統資源,只是有一點必不可少的、能保證獨立運行的資源。
獨立調度和分派的基本單位
多個線程可併發執行(同個或不同進程中均可以)
多個線程共用同個進程的資源和地址空間。
線程是動態概念,它的動態特性由線程式控制制塊TCB(線程狀態、當線程不運行時被保存的現場資源、一組執行堆棧、存放每個線程的局部變數主存區、訪問同一個進程中的主存和其它資源)描述。
Linux下,pthread庫如何控制線程
簡單來說是通過pthread簇函數來控制,常見的必不可少的就是創建和終止,具體如下:
創建線程(pthread_create)
#include <pthread.h>
int pthread_create(pthread_t *restrict thread,/
const pthread_attr_t * restrict attr, /
void *(*start_routine)(void *),/
void * restrict arg);
返回值:成功返回0,失敗返回錯誤號。
其他的系統函數都是成功返回0,失敗返回-1,而錯誤號保存在全局變數errno中。
pthread庫的函數都是通過返回值返回錯誤號
雖然每個線程也都有一個errno,但這是為了相容其他函數介面而提供的
pthread庫本身並不使用它,通過返回值返回錯誤碼更加清晰。
註意:gcc編譯時要加上選項 -lpthread執行過程:在一個線程中調用pthread_create()創建線程後,當前線程從pthread_create()返回繼續往下執行,而新的線程所執行的代碼由我們傳給pthread_create的函數指針start_routine決定。start_routine函數接收一個參數,是通過ptherad_create的arg參數傳遞給它的,該參數的類型為void ,這個指針按什麼類型解釋由調用者自己定義。start_routine的返回值類型也是void ,這個指針的含義同樣由調用者自己定義。start_routine返回時,這個線程就退出了,其他線程可以調用pthread_join得到start_routine的返回值,類似於父進程調用wait()得到子進程的退出狀態。
成功返回: pthread_create成功返回後,新創建的線程的id被填寫到thread參數所指向的記憶體單元。進程id的類型是pid_t,每個進程的id在整個系統中是唯一的,調用getpid()可以獲得當前進程的id,是一個正整數值。線程id的類型是thread_t,它只在當前進程中保證是唯一的,在不同的系統中thread_t這個類型有不同的實現,他可能是一個整數值,也可能是一個結構體,也可能是一個地址,所以不能簡單的當成整數用printf列印,調用pthread_self()可以獲得當前線程的id。
總結
在linux上,thread_t類型是一個地址值,屬於同一進程的多個線程調用getpid()可以得到相同的進程號,而調用pthread_self()得到的線程號各不相同
由於pthread_create的錯誤碼不保存在errno中,因此不能直接用perror()列印錯誤信息,可以先用strerror()把錯誤碼轉成錯誤信息再列印
如果任意一個線程調用了exit或_exit,則整個進程的所有線程都終止,由於從main函數return也相當於調用exit,為了防止新創建的線程還沒有得到執行就終止,我們在main函數return之前延時1秒,但是即使主線程等待1秒鐘,內核也不一定會調度新創建的線程執行。
終止線程
只終止線程而不終止進程的方法有三種
return(從線程函數return)。主線程return相當於調用了exit。
調用pthread_exit函數。
調用pthread_cancel函數(一個線程可以調用pthread_cancel函數終止同一進程中的另一線程)
終止函數
#include <pthread.h> void pthread_exit(void *value_ptr); value_ptr是void *類型,和線程函數返回值的用法一樣,其他線程可以調用pthread_join獲得這個指針 pthread_exit或者return返回的指針所指向的記憶體單元必須是全局的或者是用malloc分配的 不能線上程函數的棧上分配,因為當其他線程得到這個返回指針時線程函數已經退出了在這裡需要用到pthread_join函數所以引入線程等待的概念線程等待
通常情況下,線程終止後,其終止狀態一直保留到其它線程調用pthread_join獲取它的狀態為止。
線程也可以被置為detach狀態,這樣的線程一旦終止就立刻回收它所占用的所有資源,而不保留終止狀態。
不能對一個已經處於detach狀態的線程調用pthread_join,這樣的調用將返回EINVAL。
對一個尚未detach的線程調用pthread_join或pthread_detach都可以把該線程置為detach狀態
不能對同一線程重覆調用pthread_join
對一個線程調用pthread_detach就不能再調用pthread_join了。
#include <pthread.h> int pthread_detach(pthread_t tid); 返回值:成功返回0,失敗返回錯誤號。
為什麼線程等待,如何等待
為什麼需要線程等待(WHY)?
已經退出的線程,其空間沒有被釋放,仍然在進程的地址空間內。
創建新的線程不會復⽤剛纔退出線程的地址空間
如何等待(HOW)?
功能:等待線程結束 原型 #include <pthread.h> int pthread_join(pthread_t thread, void **value_ptr); 參數 thread:線程ID value_ptr:它指向⼀一個指針,後者指向線程的返回值 返回值:成功返回0;失敗返回錯誤碼調用該函數的線程將掛起等待,直到id為thread的線程終止 thread線程以不同的方法終止,通過pthread_join得到的終止狀態是不同的: 1. 如果thread線程通過return返回,value_ptr所指向的單元里存放的是thread線程函數 的返回值 2. 如果thread線程被別的線程調用pthread_cancel異常終止掉,value_ptr所指向的單元 里存放的是常數PTHREAD_CANCELED(pthread庫中常數PTHREAD_CANCELED的值是-1) #define PTHREAD_CANCELED ((void *)-1) 3. 如果thread線程是自己調用pthread_exit終止的,value_ptr所指向的單元存放的是傳 給pthread_exit的參數 註意:如果對thread線程的終止狀態不關心,可以傳NULL給value_ptr參數
如何分離線程,為何要分離
什麼是線程分離(WHAT)
簡單來講,線程分離就是當線程被設置為分離狀態後,線程結束時,它的資源會被系統自動的回收,而不再需要在其它線程中對其進行 pthread_join() 操作。
為什麼線程分離(WHY)
在我們使用預設屬性創建一個線程的時候,線程是 joinable 的。 joinable 狀態的線程,必須在另一個線程中使用 pthread_join() 等待其結束,如果一個 joinable 的線程在結束後,沒有使用 pthread_join() 進行操作,這個線程就會變成"僵屍線程"。每個僵屍線程都會消耗一些系統資源,當有太多的僵屍線程的時候,可能會導致創建線程失敗。
怎麼分離(HOW)
在前面講到線程式控制制時提到了終止線程,其中就提到了detach狀態,下麵就是設置為detach狀態的函數
核心思想:#include <pthread.h> int pthread_detach(pthread_t tid); 返回值:成功返回0,失敗返回錯誤號。 註意:線程分離可以在創建的時候屬性裡面設置- 把一個線程的屬性設置為 detachd 的狀態,讓系統來回收它的資源;
- 把一個線程的屬性設置為 joinable 狀態,這樣就可以使用 pthread_join() 來阻塞的等待一個線程的結束,並回收其資源,並且pthread_join() 還會得到線程退出後的返回值,來判斷線程的退出狀態 。
什麼叫做臨界區,臨界資源,原子性
臨界資源:臨界資源是一次僅允許一個進程使用的共用資源。各進程採取互斥的方式,實現共用的資源稱作臨界資源。屬於臨界資源的硬體有,印表機,磁帶機等;軟體有消息隊列,變數,數組,緩衝區等。諸進程間採取互斥方式,實現對這種資源的共用。
臨界區:每個進程中訪問臨界資源的那段代碼稱為臨界區(criticalsection),每次只允許一個進程進入臨界區,進入後,不允許其他進程進入。不論是硬體臨界資源還是軟體臨界資源,多個進程必須互斥的對它進行訪問。多個進程涉及到同一個臨界資源的的臨界區稱為相關臨界區。使用臨界區時,一般不允許其運行時間過長,只要運行在臨界區的線程還沒有離開,其他所有進入此臨界區的線程都會被掛起而進入等待狀態,併在一定程度上影響程式的運行性能。
原子性:原子性是指一個操作是不可中斷的,要麼全部執行成功要麼全部執行失敗,有著“同生共死”的感覺。及時在多個線程一起執行的時候,一個操作一旦開始,就不會被其他線程所干擾。
什麼叫做互斥與同步,為什麼要引入互斥與同步機制
互斥:是指散步在不同任務之間的若幹程式片斷,當某個任務運行其中一個程式片段時,其它任務就不能運行它們之中的任一程式片段,只能等到該任務運行完這個程式片段後才可以運行。最基本的場景就是:一個公共資源同一時刻只能被一個進程或線程使用,多個進程或線程不能同時使用公共資源。
同步:是指散步在不同任務之間的若幹程式片斷,它們的運行必須嚴格按照規定的某種先後次序來運行,這種先後次序依賴於要完成的特定的任務。最基本的場景就是:兩個或兩個以上的進程或線程在運行過程中協同步調,按預定的先後次序運行。比如 A 任務的運行依賴於 B 任務產生的數據。
- 引入互斥與同步機制原因:
現代操作系統基本都是多任務操作系統,即同時有大量可調度實體在運行。在多任務操作系統中,同時運行的多個任務可能:- 都需要訪問/使用同一種資源
- 多個任務之間有依賴關係,某個任務的運行依賴於另一個任務
這兩種情形是多任務編程中遇到的最基本的問題,也是多任務編程中的核心問題,同步和互斥就是用於解決這兩個問題的。
死鎖以及死鎖產生的4個必要條件
所謂死鎖,是指多個進程在運行過程中因爭奪資源而造成的一種僵局,當進程處於這種僵持狀態時,若無外力作用,它們都將無法再向前推進。
產生死鎖的原因:
可歸結為如下兩點:
a. 競爭資源
- 系統中的資源可以分為兩類:
- 可剝奪資源,是指某進程在獲得這類資源後,該資源可以再被其他進程或系統剝奪,CPU和主存均屬於可剝奪性資源;
- 另一類資源是不可剝奪資源,當系統把這類資源分配給某進程後,再不能強行收回,只能在進程用完後自行釋放,如磁帶機、印表機等。
產生死鎖中的競爭資源之一指
- 系統中的資源可以分為兩類:

