
編碼及運算符 1.編碼 1.編碼的概念 在電腦硬體中,編碼(coding)是指用代碼來表示各組數據資料,使其成為可利用電腦進行處理和分析的信息。代碼是用來表示事物的記號,它可以用數字、字母、特殊的符號或它們之間的組合來表示。 2.編碼的種類(常用種類) ①ASCCI 1.ASCCI的產生 在計算 ...
編碼及運算符
1.編碼
1.編碼的概念
在電腦硬體中,編碼(coding)是指用代碼來表示各組數據資料,使其成為可利用電腦進行處理和分析的信息。代碼是用來表示事物的記號,它可以用數字、字母、特殊的符號或它們之間的組合來表示。
2.編碼的種類(常用種類)
①ASCCI
1.ASCCI的產生
在電腦中,所有的數據在存儲和運算時都要使用二進位數表示(因為電腦用高電平和低電平分別表示1和0),例如,像a、b、c、d這樣的52個字母(包括大寫)、以及0、1等數字還有一些常用的符號(例如*、#、@等)在電腦中存儲時也要使用二進位數來表示,而具體用哪些二進位數字表示哪個符號,當然每個人都可以約定自己的一套(這就叫編碼),而大家如果要想互相通信而不造成混亂,那麼大家就必須使用相同的編碼規則,於是美國有關的標準化組織就出台了ASCII編碼,統一規定了上述常用符號用哪些二進位數來表示。
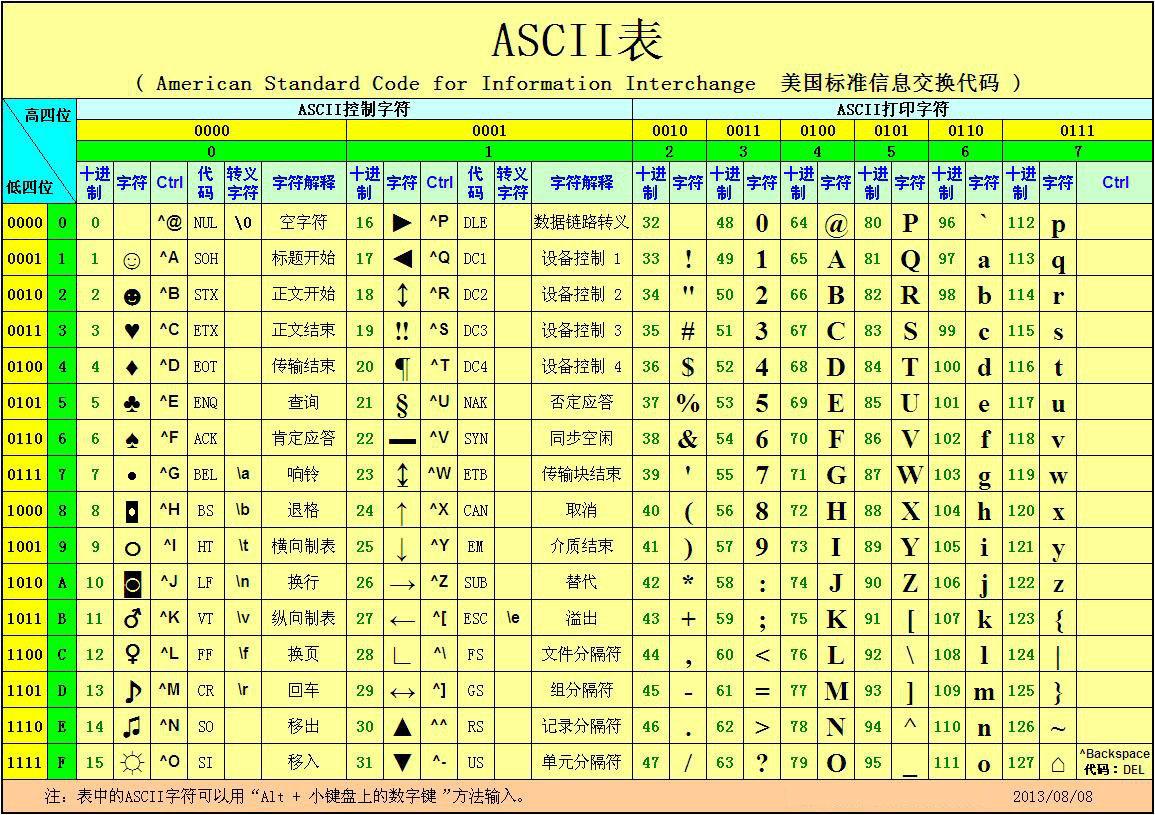
2.ASCCI的表述
ASCII 碼使用指定的7 位或8 位二進位數組合來表示128 或256 種可能的字元。標準ASCII 碼也叫基礎ASCII碼,使用7 位二進位數(剩下的1位二進位為0)來表示所有的大寫和小寫字母,數字0 到9、標點符號, 以及在美式英語中使用的特殊控制字元。
字母A用ASCII編碼是十進位的65,二進位的01000001;
②unicode
1.Unicode的產生
unicode碼擴展自ASCII 字元集。在嚴格的ASCII中,每個字元用7位元表示,或者電腦上普遍使用的每字元有8位元寬。如果要表示中文,顯然一個位元組是不夠的,至少需要兩個位元組,而且還不能和ASCII編碼衝突,所以,中國制定了GB2312編碼,用來把中文編進去。類似的,日文和韓文等其他語言也有這個問題。為了統一所有文字的編碼,Unicode應運而生。Unicode把所有語言都統一到一套編碼里,這樣就不會再有亂碼問題了。
2.Unicode的表述
Unicode通常用兩個位元組表示一個字元,原有的英文編碼從單位元組變成雙位元組,只需要把高位元組全部填為0就可以。在Unicode中:漢字“字”對應的數字是23383(十進位),十六進位表示為5B57。在Unicode中,我們有很多方式將數字23383表示成程式中的數據
漢字“中”已經超出了ASCII編碼的範圍,用Unicode編碼是十進位的20013,二進位的01001110 00101101。
③UTF-8
1.UTF-8的產生
事實證明,對可以用ASCII表示的字元使用Unicode並不高效,因為Unicode比ASCII占用大一倍的空間,而對ASCII來說高位元組的0對他毫無用處。為瞭解決這個問題,就出現了一些中間格式的字元集,他們被稱為通用轉換格式,即UTF(Unicode Transformation Format)。常見的UTF格式有:UTF-7, UTF-7.5, UTF-8,UTF-16, 以及 UTF-32。這裡只介紹UTF-8。
2.UTF-8的表述
UTF-8以位元組為單位對Unicode進行編碼。從Unicode到UTF-8的編碼方式如下:
| Unicode編碼(十六進位) | UTF-8 位元組流(二進位) |
| 000000-00007F | 0xxxxxxx |
| 000080-0007FF | 110xxxxx 10xxxxxx |
| 000800-00FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 010000-10FFFF | 11110xxx10xxxxxx10xxxxxx10xxxxxx |
UTF-8的特點是對不同範圍的字元使用不同長度的編碼。對於0x00-0x7F之間的字元,UTF-8編碼與ASCII編碼完全相同。UTF-8編碼的最大長度是4個位元組。從上表可以看出,4位元組模板有21個x,即可以容納21位二進位數字。Unicode的最大碼位0x10FFFF也只有21位。
字元 ASCII Unicode UTF-8 A 01000001 00000000 01000001 01000001 中 x 01001110 00101101 11100100 10111000 10101101
註意(你看到很多網頁的源碼上會有類似<meta charset="UTF-8" />的信息,表示該網頁正是用的UTF-8編碼)
④GBK
1.GBK的產生
GBK全稱《漢字內碼擴展規範》(GBK即“國標”、“擴展”漢語拼音的第一個字母,英文名稱:Chinese Internal Code Specification) ,中華人民共和國全國信息技術標準化技術委員會1995年12月1日制訂,國家技術監督局標準化司、電子工業部科技與質量監督司1995年12月15日聯合以技監標函1995 229號文件的形式,將它確定為技術規範指導性文件。這一版的GBK規範為1.0版。因為目前大家使用的主要是GB編碼字型檔,此編碼標準只收錄了6763個常用漢字,而GB字型檔以外大量漢字,只能通過方正女媧補字軟體拼字或其它造字程式補字。儘管補出的漢字在字形上滿足需要,但在字體風格、大小、結構方面難以協調統一,而採用手工貼圖的方式補字,更不雅觀。進而言之,如果用戶建立信息系統,或需要查詢新聞、出版內容時,靠補字是無法實現的。方正開發的GBK字型檔,將極大地緩解缺字現象。
2.GBK的表述
GBK 亦採用雙位元組表示,總體編碼範圍為 8140-FEFE,首位元組在 81-FE 之間,尾位元組在 40-FE 之間,剔除 xx7F 一條線。總計 23940 個碼位,共收入 21886 個漢字和圖形符號,其中漢字(包括部首和構件)21003 個,圖形符號 883 個。相容ASCCI。
2.Python中的編碼轉碼
1.Python的編碼方式
因為電腦只能處理數字,如果要處理文本,就必須先把文本轉換為數字才能處理。最早的電腦在設計時採用8個比特(bit)作為一個位元組(byte),所以,一個位元組能表示的最大的整數就是255(二進位11111111=十進位255),如果要表示更大的整數,就必須用更多的位元組。比如兩個位元組可以表示的最大整數是65535,4個位元組可以表示的最大整數是4294967295。在最新的Python 3版本中,字元串是以Unicode編碼的,也就是說,Python的字元串支持多語言
2.python中的字元串編碼
由於Python的字元串類型是str,在記憶體中以Unicode表示,一個字元對應若幹個位元組。如果要在網路上傳輸,或者保存到磁碟上,就需要把str變為以位元組為單位的bytes。
Python對bytes類型的數據用帶b首碼的單引號或雙引號表示:
x = b'ABC' >>> 'ABC'.encode('ascii') b'ABC' >>> '中文'.encode('utf-8') b'\xe4\xb8\xad\xe6\x96\x87' >>> '中文'.encode('ascii') Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
3.Python中的轉碼解碼和len()方法
encode(轉碼),decode(解碼)。
x = b'ABC' >>> 'ABC'.encode('ascii') b'ABC' >>> '中文'.encode('utf-8') b'\xe4\xb8\xad\xe6\x96\x87' >>> b'ABC'.decode('ascii') 'ABC' >>> b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8') '中文'
len()函數:計算一個對象長度,如果換成bytes,len()函數就計算位元組數。
>>> len(b'ABC') 3 >>> len(b'\xe4\xb8\xad\xe6\x96\x87') 6 >>> len('中文'.encode('utf-8')) 6
3.運算符
1.運算符概念
運算符用於執行程式代碼運算,會針對一個以上操作數項目來進行運算。例如:2+3,其操作數是2和3,而運算符則是“+”。在vb2005中運算符大致可以分為5種類型:算術運算符、連接運算符、關係運算符、賦值運算符和邏輯運算符。
2.Python中的運算符
運算符優先順序 ↓
| 運算符 | 描述 |
|---|---|
| ** | 指數 (最高優先順序) |
| ~ + - | 按位翻轉, 一元加號和減號 (最後兩個的方法名為 +@ 和 -@) |
| * / % // | 乘,除,取模和取整除 |
| + - | 加法減法 |
| >> << | 右移,左移運算符 |
| & | 位 'AND' |
| ^ | | 位運算符 |
| <= < > >= | 比較運算符 |
| <> == != | 等於運算符 |
| = %= /= //= -= += *= **= | 賦值運算符 |
| is is not | 身份運算符 |
| in not in | 成員運算符 |
| and or not | 邏輯運算符 |
PS(時間原因,博主沒有對每一個運算符介紹,大家自行查閱,養成查找問題習慣)


