
參考博客:Hadoop HBase概念學習系列 參考博客:Hadoop HBase概念學習系列之HBase里的Zookeeper(二十一) 參考博客:Hadoop HBase概念學習系列之HBase里的客戶端和HBase集群建立連接(詳細)(十四) 參考博客:Hadoop HBase概念學習系列之M ...
參考博客:Hadoop HBase概念學習系列
參考博客:Hadoop HBase概念學習系列之HBase里的Zookeeper(二十一)
參考博客:Hadoop HBase概念學習系列之HBase里的客戶端和HBase集群建立連接(詳細)(十四)
參考博客:Hadoop HBase概念學習系列之META表和ROOT表(六)
參考博客:Hadoop HBase概念學習系列之HBase里的HRegion(五)
參考博客:Hadoop HBase概念學習系列之HLog(二)
參考博客:Hadoop HBase概念學習系列之HRegion伺服器(三)
參考博客:Hadoop HBase概念學習系列之HMaster伺服器(四)
參考博客:ZooKeeper 原理及其在 Hadoop 和 HBase 中的應用
參考博客:HBase介紹和工作原理
參考博客:深入瞭解HBASE架構(轉)
1. 體繫結構圖
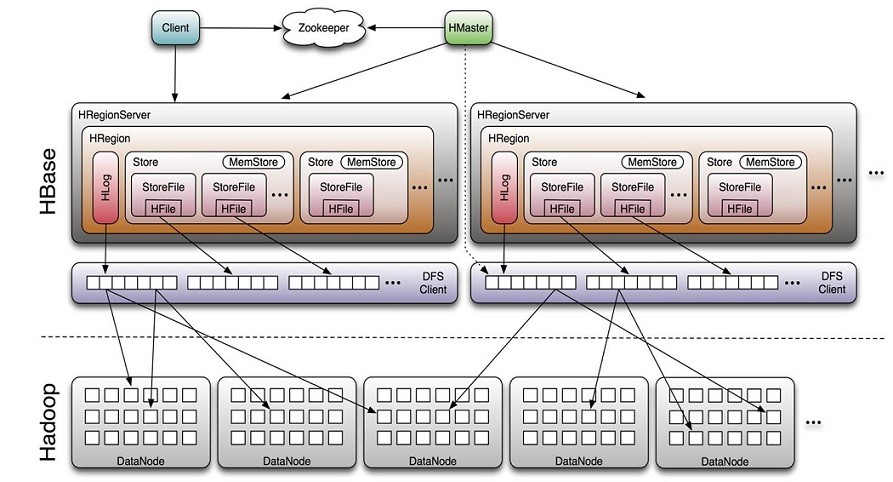
1.1. Hbase特性:
- 強烈一致的讀寫:HBase不是“最終一致”的數據存儲。這使得它非常適合於高速計數器聚合之類的任務。
- 自動分片:HBase表通過區域分佈在集群上,隨著數據的增長,區域會自動分割和重新分佈。
- RegionServer自動故障轉移
- Hadoop/HDFS集成:HBase支持HDFS開箱即用的分散式文件系統。
- MapReduce: HBase支持通過MapReduce進行大規模並行處理,將HBase用作source和sink。
- Java客戶端API: HBase支持易於使用的Java API進行編程訪問。
- Thrift/REST API: HBase還支持非java前端的Thrift 和REST。
- Block Cache和Bloom Filters:HBase支持Block緩存和Bloom過濾器,用於高容量查詢優化。
- 操作管理:HBase提供了內置的web頁面,用於操作洞察以及JMX度量
2. Zookeeper在HBase中的應用
HMaster選舉與主備切換
HMaster選舉與主備切換的原理和HDFS中NameNode及YARN中ResourceManager的HA原理相同。
系統容錯
當HBase啟動時,每個RegionServer都會到ZooKeeper的/hbase/rs節點下創建一個信息節點(下文中,我們稱該節點為”rs狀態節點”),例如/hbase/rs/[Hostname],同時,HMaster會對這個節點註冊監聽。當某個 RegionServer 掛掉的時候,ZooKeeper會因為在一段時間內無法接受其心跳(即 Session 失效),而刪除掉該 RegionServer 伺服器對應的 rs 狀態節點。與此同時,HMaster 則會接收到 ZooKeeper 的 NodeDelete 通知,從而感知到某個節點斷開,並立即開始容錯工作。
HBase為什麼不直接讓HMaster來負責RegionServer的監控呢?如果HMaster直接通過心跳機制等來管理RegionServer的狀態,隨著集群越來越大,HMaster的管理負擔會越來越重,另外它自身也有掛掉的可能,因此數據還需要持久化。在這種情況下,ZooKeeper就成了理想的選擇。
RootRegion管理
對應HBase集群來說,數據存儲的位置信息是記錄在元數據region,也就是RootRegion上的。每次客戶端發起新的請求,需要知道數據的位置,就會去查詢RootRegion,而RootRegion自身位置則是記錄在ZooKeeper上的(預設情況下,是記錄在ZooKeeper的/hbase/meta-region-server節點中)。當RootRegion發生變化,比如Region的手工移動、重新負載均衡或RootRegion所在伺服器發生了故障等是,就能夠通過ZooKeeper來感知到這一變化並做出一系列相應的容災措施,從而保證客戶端總是能夠拿到正確的RootRegion信息。
Region狀態管理
HBase里的Region會經常發生變更,這些變更的原因來自於系統故障、負載均衡、配置修改、Region分裂與合併等。一旦Region發生移動,它就會經歷下線(offline)和重新上線(online)的過程。
分散式SplitWAL任務管理
當某台RegionServer伺服器掛掉時,由於總有一部分新寫入的數據還沒有持久化到HFile中,因此在遷移該RegionServer的服務時,一個重要的工作就是從WAL中恢復這部分還在記憶體中的數據,而這部分工作最關鍵的一步就是SplitWAL,即HMaster需要遍歷該RegionServer伺服器的WAL,並按Region切分成小塊移動到新的地址下,併進行日誌的回放(replay)。
由於單個RegionServer的日誌量相對龐大(可能有上千個Region,上GB的日誌),而用戶又往往希望系統能夠快速完成日誌的恢復工作。因此一個可行的方案是將這個處理WAL的任務分給多台RegionServer伺服器來共同處理,而這就又需要一個持久化組件來輔助HMaster完成任務的分配。當前的做法是,HMaster會在ZooKeeper上創建一個splitWAL節點(預設情況下,是/hbase/splitWAL節點),將“哪個RegionServer處理哪個Region”這樣的信息以列表的形式存放到該節點上,然後由各個RegionServer伺服器自行到該節點上去領取任務併在任務執行成功或失敗後再更新該節點的信息,以通知HMaster繼續進行後面的步驟。ZooKeeper在這裡擔負起了分散式集群中相互通知和信息持久化的角色。
3. Catalog Tables
目錄表hbase:meta以hbase表的形式存在,並從hbase shell的列表命令中過濾出來,但實際上它和其他表一樣是一個表。
hbase:meta表(以前稱為.META.)保存了系統中所有的regions列表,hbase:meta的位置存儲在ZooKeeper中。
4. 寫流程
1、client向Hregionserver發送寫請求。
2、Hregionserver將數據寫到Hlog(write ahead log)。為了數據的持久化和恢復。
3、hregionserver將數據寫到記憶體(memstore)
4、反饋client寫成功。
5. 數據flush過程
1、當memstore數據達到閾值(預設是128M),將數據刷到硬碟【數據存儲到hdfs中】,將記憶體中的數據刪除,同時刪除Hlog中的歷史數據。
2、在hlog中做標記點。
6. Hbase的讀流程
1、通過zookeeper和-ROOT- .META.表定位hregionserver。
2、數據從記憶體和硬碟合併後返回給client
3、數據塊會緩存
7. Hmaster的職責
1、管理用戶對Table表的增、刪、改、查操作;
2、管理HRegion伺服器的負載均衡,調整HRegion分佈;
3、在HRegion分裂後,負責新HRegion的分配;
4、在HRegion伺服器停機後,負責失效HRegion伺服器上的HRegion遷移。
Master負責監視集群中的所有RegionServer實例,是所有元數據更改的介面。在分散式集群中,主機通常在NameNode上運行。
一個常見的列表問題涉及到Master宕機時HBase集群發生了什麼。因為Hbase客戶端直接與regionserver通信,所以集群仍然可以在“穩定狀態”運行。此外,根據目錄表,hbase:meta作為hbase表存在,並不駐留在Master中。但是,主伺服器控制關鍵功能,如區RegionServer故障轉移和完成區域分割。因此,雖然集群在沒有Master的情況下仍然可以運行很短的時間,但是主伺服器應該儘快重啟。
在分散式集群中,主機通常在NameNode上運行。
8. Hregionserver的職責
1、HRegion Server主要負責響應用戶I/O請求,向HDFS文件系統中讀寫數據,是HBASE中最核心的模塊。
2、HRegion Server管理了很多table的分區,也就是region。
9. Client請求
HBase客戶端找到服務於特定行範圍的RegionServers。它通過查詢hbase:meta表來實現這一點。在定位所需的區域之後,客戶端聯繫服務於該region(s)的RegionServer,而不是通過master,併發出讀或寫請求。這些信息緩存在客戶端中,以便後續請求不需要經過查找過程。如果某個區域被主負載均衡器重新分配,或者因為某個RegionServer已死亡,客戶端將重新請求目錄表以確定用戶region的新位置。


