
C++ 前言 c++是一種比較早的語言,具體誕生在什麼時候我就不記得了 然後進入正文 正文 Part 1 C++程式構造 C++程式構造比較簡單實現 這玩意反正Noip在考場上是可以用的,它包含了許多頭文件,所以又被稱為萬能頭文件 Ps: 本人不推薦使用萬能頭文件 雖然現在沒什麼大事發生,但是指不定 ...
C++
前言
c++是一種比較早的語言,具體誕生在什麼時候我就不記得了
然後進入正文 -- >
正文
Part 1 C++程式構造
C++程式構造比較簡單實現
#include<bits/stdc++.h> // 頭文件
using namespace std; //使用STL空間
... //一些其他的程式或者定義內容
int main() //主程式
{
return 0;
}#include<bits/stdc++.h>這玩意反正Noip在考場上是可以用的,它包含了許多頭文件,所以又被稱為萬能頭文件
Ps: 本人不推薦使用萬能頭文件 - 雖然現在沒什麼大事發生,但是指不定那天CCF傻逼突然給你禁止了那麼你就GG了,最好記住每個操作所對應的頭文件什麼的
using namespace std; 這玩意在OJ上面比較多,一般最好每次編程的時候都要加上,而且加了似乎比不加的空間要小(待考證)
int main()
{
...
}這玩意是個主程式,一般情況下有人這麼寫,與上面的寫法等價,推薦寫上面的
int main(void)
{
...
return 0;
}括弧裡面還是可以有參數,
int main(int argc char *argv[])
{
...
return 0;
}這個不太常用,因為這個是一個傳參的程式 - 基本只有對拍的時候能用到,現在先不討論
您會發現第一個寫法似乎不需要return 0;乍一看還真是,運行也是正確的,但是為了確保程式正常運行之後結束,我們不考慮不加return 0的做法,只是告訴你可以不寫,但是為了保險還是寫上
int main()
{
...
return 0;
}接下來 -> 主程式設計
Part 2 主程式設計
我們現在將要討論主程式設計的相關事宜
用幾個問題來講 :
Q: 如何去定義一個我想要的變數
這個有幾個變數是您需要瞭解的
整形變數 - 整數
| 變數類型 | 變數上限 | 存儲內容 |
|---|---|---|
| int | \(2^{31}-1\) | 整數 |
| short | \(2^{15}-1\) | 整數 |
| long | \(2^{31}-1\) | 整數 |
| long long | \(2^{63}-1\) | 整數 |
| unsigned + XX | 原來類型上限*2 | 整數 |
其中的XX指的是unsigned上面的變數
為什麼要講上限呢?因為如果一個數字存不下了,那麼這個變數就會溢出,從最小值從頭開始加,就會導致結果的錯誤
int a=2147483648;
printf("%d",a);//結果是負數浮點數 - 小數
| 變數類型 | 有效位數 | 存儲內容 |
|---|---|---|
| float | 6-7 | 浮點數 |
| double | 15-16 | 浮點數 |
| long double | 18-19 | 浮點數 |
浮點數可以理解成小數
浮點數相關註意事項
不能直接比較
float a =1.0;
if(a==1) return 0;這樣的寫法是錯誤的
應該是這樣的
float a = 1.0;
if(a - 1 < 0.0000001) return 0;還有有的時候浮點數精度問題會出錯,如果和答案有些差距建議換成有效位數比較高的long double
其他變數
| 變數類型 | 存儲內容 |
|---|---|
| char | 單個字元 |
| bool | 0或者1 |
| string | 字元串 - 多個字元組合在一起 |
| void | 空指針 , 無類型 |
char 一般表示的是單個字元
char c='A';
char c=65;
char c;由於C++比較靈活,使得char類型和整形之間可以相互轉換
比如
int b=65;
char a=b;ASCII表
| 字元內容 | 對應ASCII碼的值 |
|---|---|
| 0 - 9 | 48-57 |
| A-Z | 65-90 |
| a-z | 97-122 |
| - (減號) | 45 |
上面的最好背下來
char c=48;
char c='0';上面兩句是等價的,因為第二句傳的是字元 0而不是0這個數字
考試的時候忘了 賦值輸出就好
bool變數-非零即一,空間小,一般用來做標記
string 字元串 - 比較好用,但是個人認為不如字元數組好用,數組是後面的內容
void 一般用來聲明函數,因為有一些函數可以不用返回值
這裡仔細講講全局變數和局部變數
不在函數內定義的 -> 全局變數
所有的函數都可以使用這個變數
在函數內定義的 -> 局部變數
只有定義它的函數才能夠使用
局部數組容量 < 全局數組容量
因此,我們一般使用全局數組,局部變數
這裡還要介紹一個東西 : sizeof
sizeof(變數名)返回的是變數類型占用存儲空間的大小
用處不大,最多參考著定數組大小
接下來 , --> 變數的讀入
Part 3 變數的讀入
#include<cstdio>
using namespace std;
int main()
{
int a;
long long b;
short c;
char d;
bool e;
float f;
double g;
long double h;
scanf("%d",&a);
scanf("%lld",&b);
scanf("%hd",&c);
scanf("%d",&c);// short的兩種讀入方式都可以
scanf("%c",&d);
scanf("%d",&e);//可以用整型方式輸入輸出沒問題
scanf("%f",&f);
scanf("%lf,&g);
scanf("%llf",&h);
printf("%d %lld %hd\n",a,b,c);
printf("%d %lld %d",a,b,c);
return 0;
}這裡的scanf和printf從屬於
#include<cstdio>的,是一種C語言的輸入輸出方式,c++中也能夠用,讀入輸出的速度很快,比較推薦
scanf("%lld",&b);這個裡面的%lld表示的是格式,&是地址符,您只要知道要這麼做就行,不這麼做要麼RE(Runtime Error : 運行時錯誤) ,要麼CE(編譯錯誤),要麼WA(Wrong Answer,錯誤答案),有人不加地址符沒事,但是這隻是個例的語句,還是要加的
因為”“裡面的是輸入格式,%d是變數的輸入格式,還可以有
scanf("%d %d",&n,&m);輸入兩個int變數n,m,中間用空格隔開,其實中間的格式操作符有很多,讀者可以自己去查
printf("%d",b);格式操作符和scanf一樣,輸出的時候%d是變數格式控制符,可以在""內填其他的要輸出的內容
printf("青山");只是後面變數名不需要加上地址符,後面還可以加上回車控制符\n,右對齊什麼的,保證寬度至少為5位,就是%nd,然後%0nd用得比較多,表示輸出的整型寬度至少為n位,不足n位用0填充,還有對於浮點數來說,可以%0.nf來保留n位輸出
printf("%5d\n",b);
printf("%-5d\n",b);
long double b;
printf("%0.5llf\n",b);然後string類型的不能夠使用scanf讀入
#include<iostream>
using namespace std;
int main()
{
int a;
long long b;
short c;
...//其他的都一樣
cin>>a>>b>>c;
cout<<a<<" "<<b<<" "<<c<<endl;
cout<<a<<" "<<b<<" "<<c;
return 0;
}一般cin和cout比較方便,沒有格式什麼的設定,但是它的速度十分的慢,所以一般情況下為了防止CCF老人機卡您的程式,我並不推薦您用cin和cout,雖然有取消同步從而加速的操作,但是如果恰巧您的printf和scanf之類的出現在程式中,那麼遲早要出事
還有一個我推薦scanf和printf不推薦cin和cout的原因是cout保留n位輸出和printf可能有不一樣的地方,而造數據的一般用printf,所以最好不要用cin和cout
不過cin一個string類型的變數還是很不錯的
下一章 -> 數組
Part 4 數組
現在我們已經學完了變數的定義方式那麼:
Q: 現在要求輸入N個數字,並原樣輸出
輸入格式
兩行,第一行,一個數字N
第二行,N個用空格隔開的數字
輸出格式
一行,N個用空格隔開的數字
對於這道題目而言我們可以這麼來理解 - 輸出一個數組
其實還有一種線上做法,十分簡單,但是因為沒有講迴圈,先當做數組的練習題
不管是什麼類型我們都可以定義數組
定義方式
變數類型 + 數組名 + [ 數組大小 ] ;
舉個例子
int ans[10086];int - 變數類型
ans - 數組名
[10086] 數組大小
數組的用法:
數組賦初值
int a[3]={1,2,3}; //數組大小為3,初始值為a[0]=1,a[1]=2,a[2]=3;
int a[]={1,2,3};//和上面的語句等價,一定要賦初值,然後系統自動分配空間
int a[3]={};//數組初始化為零
int a[3]={0};//和上面的語句等價
int a[3]={1,2};//這也是可以的,只是沒有賦值的為0,也就是a[0]=1,a[1]=2,a[2]=0;這裡要註意的是:數組從零開始,也就是說,
int a[n];
printf("%d",a[n]);是錯誤的,它只到a[n-1];
還有一種初始值操作:
#include<cstring>
memset(a,0,sizeof(a));但是好像只能為0或者-1,還有16進位的相關問題(不知道進位的可以自己去學)
因為這個地方的參數,也就是memset裡面的那個數字(在上面的例子中是0),然後我們可以發現的是,這個參數賦值是賦值到int變數的4個Byte中,也就是說,一個數字賦值為0 是這樣的
0000 | 0000 | 0000 | 0000 = 0而 0x代表的就是16進位,所以0x3f3f3f3f代表的就是
因為\(3_{(10)}={11}_{(2)}\),而且\(f_{(16)}=15_{(10)}=1111_{(2)}\),十六進位位沒有的數字用0補齊,十六進位在二進位中4位表示一個數字
\[{00111111001111110011111100111111}_{(2)} = {0x3f3f3f3f}_{(16)}\]
所以也就是memset(a,0x3f,sizeof(a));得到數字的來由.
而之所以賦值為1不行的原因是
\[0001 | 0001 | 0001 | 0001 = 1000100010001_{2} = 16843009\]
所以與我們預想的不一樣
所以記住,memset只能夠賦值0,-1,0x3f(得到結果為0x3f3f3f3f)
其中的0x3f3f3f3f是一個\(10^9\)數量級的數字,但是
2*0x3f3f3f3f < 0x7fffffff (2147483647也就是\(2^{31}-1\))
\[0x7fffffff = 0111 | 1111 | 1111 | 1111 | 1111 | 1111 | 1111 | 1111_{(2)} = 1111111111111111111111111111111_{(2)}=2^{31}-1\]
我們一般把INF(無窮大)定為0x3f3f3f3f的原因是在將來的最短路學習中,如果我們選擇了Max_int,那麼就算是再加上1也會溢出,而這裡的無窮大即使加上無窮大也是比Max_int要小的,所以為了保險期間一般選擇0x3f3f3f3f作為無窮大的值
學好Latex(上面數學公式排版的格式規範)還是很重要的
字元數組的操作
| 序號 | 操作方式 | 意義 |
|---|---|---|
| 1 | strcpy(s1,s2) | 複製字元串 s2 到字元串 s1 |
| 2 | strcat(s1,s2) | 連接字元串 s2 到字元串 s1 的末尾 |
| 3 | strlen(s1) | 返回字元串 s1 的長度 |
| 4 | strcmp(s1,s2) | 返回s1與s2的比較結果 |
| 5 | strchr(s1,ch) | 返回一個指針,指向字元串s1中字元ch的第一次出現的位置 |
| 6 | strstr(s1,s2) | 返回一個指針,指向字元串s1中s2的第一次出現的位置 |
初始化字元數組 :
C 風格的字元串起源於 C 語言,併在 C++ 中繼續得到支持。字元串實際上是使用 null 字元 ‘\0’ 終止的一維字元數組。因此,一個以 null 結尾的字元串,包含了組成字元串的字元。
下麵的聲明和初始化創建了一個 “Hello” 字元串。由於在數組的末尾存儲了空字元,所以字元數組的大小比單詞 “Hello” 的字元數多一個。
char greeting[6] = {'H', 'e', 'l', 'l', 'o', '\0'};其實,您不需要把 null 字元放在字元串常量的末尾。C++ 編譯器會在初始化數組時,自動把 ‘\0’ 放在字元串的末尾。所以也可以利用下麵的形式進行初始化
char greeting[] = "Hello";以下是 C/C++ 中定義的字元串的記憶體表示:
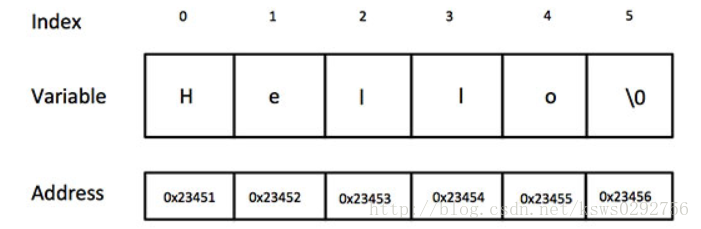
字元串的操作
初始化字元串:
string str; //生成一個空字元串
string str ("ABC") //等價於 str="ABC"<br>
string str ("ABC", strlen) // 將"ABC"存到str里,最多存儲前strlen個位元組
string s("ABC",stridx,strlen) //將"ABC"的stridx位置,做為字元串開頭,存到str里.且最多存儲strlen個位元組.
string s(strlen, 'A') //存儲strlen個'A'到str里所有字元串的操作:
str1.assign("ABC"); //清空string串,然後設置string串為"ABC"
str1.length(); //獲取字元串長度
str1.size(); //獲取字元串數量,等價於length()
str1.capacity(); //獲取容量,容量包含了當前string里不必增加記憶體就能使用的字元數
str1.resize(10); //表示設置當前string里的串大小,若設置大小大於當前串長度,則用字元\0來填充多餘的.
str1.resize(10,char c); //設置串大小,若設置大小大於當前串長度,則用字元c來填充多餘的
str1.reserve(10); //設置string里的串容量,不會填充數據.
str1.swap(str2); //替換str1 和 str2 的字元串
str1.puch_back ('A'); //在str1末尾添加一個'A'字元,參數必須是字元形式
str1.append ("ABC"); //在str1末尾添加一個"ABC"字元串,參數必須是字元串形式
str1.insert ("ABC",2); //在str1的下標為2的位置,插入"ABC"
str1.erase(2); //刪除下標為2的位置,比如: "ABCD" --> "AB"
str1.erase(2,1); //從下標為2的位置刪除1個,比如: "ABCD" --> "ABD"
str1.clear(); //刪除所有
str1.replace(2,4, "ABCD"); //從下標為2的位置,替換4個位元組,為"ABCD"
str1.empty(); //判斷為空, 為空返回true鳴謝: ZeroZone零域大佬和LifeYx大佬在網上發佈的博客,收益匪淺
***
數組的輸入方式
char類型
char c;
scanf("%c",&c);
cin>>c;
c=getchar();上面三種語句都行,但是一般scanf容易出錯,cin又太慢,所以我是比較推薦getchar(),它的作用是讀入單個字元
char[]類型
char c[10];
scanf("%s",c);
gets(c);//不能使用其中的gets是在#include<cstring>的裡面,但是在比賽的時候用的是linux的系統,使用gets會報錯,所以不能使用,所以只能用scanf,讀入快,結束標誌是空格或者換行 ,千萬註意scanf讀入字元數組的時候沒有地址符
string類型
string a;
cin>>a;這個是我推薦的string讀入的寫法,但是我不推薦用string類型,最好使用字元數組
輸出的話
char類型
char c;
putchar(c);//最快最方便的char[]類型
char c[10];
printf("%s",c);//也是可以用的中最快最方便的string類型
string s;
cout<<s;我還是只是推薦寫法,不推薦用string寫程式
除了char和string,都是推薦用printf和scanf輸入的
具體要求和單個變數時一致,加上[當前序號]即可
舉例來講
for(int i=0;i<n;i++) scanf("%d",&a[i]);你閱讀之後可以發現這個for是從哪裡蹦出來的,之前沒有學啊?
沒學沒關係,我現在教你,這貨叫做迴圈,一般還有while,do while一共三種迴圈語句
for語句
for(表達式1;表達式2;表達式3)
{
語句1;
語句2;
語句3;
}
//或者
for(表達式1;表達式2;表達式3) 一個語句;一般是這樣的格式,其中的表達式1一般是定義變數,變數賦初值,表達式2一般是約束條件,只有滿足約束條件的時候才能夠繼續迴圈,不滿足的時候就退出迴圈,表達式3是改變迴圈條件變數的值,使它在運行若幹時長後停止迴圈
舉個例子
for(int i=0 (迴圈變數,定義整型變數i 初始值為0);i<n (整型變數i必須小於n));i++(迴圈變數自增))) scanf("%d",&a[i]);認真的讀者可以發現
i++ 是什麼? 其實i++ 就是 i=i+1;把i本身的值+1,但是理論速度更快,更方便,如果看到了a[i++]的,那麼說明它是在執行完了這個語句之後再把i自增,如果是a[++i] ,那麼就是先把i自增,再執行這個語句,i--和--i都是這樣。
所以我們的程式將會遍歷(以n=3為例)
a[0],a[1],a[2];到了i=3的時候我們發現i=n了,那麼我們跳出迴圈來
這個時候我們講講判斷符
| 判斷符 | 用處 |
|---|---|
| < | 小於 |
| <= | 小於等於 |
| > | 大於 |
| >= | 大於等於 |
| == | 等於 |
| && | 且 |
||(無法原樣保留) |
或 |
| != | 不等於 |
就是這些
前面的一些判斷符我不多說,後面的可能讀者會有點疑惑
&&表示的是 而且
for(int i=0;i<j&&i>0;i++)其中的&&表示的就是i
||表示的是 或
for(int i=0;i<j||i>0;i++)其中的||表示的就是i
!= 表示的是 不等於
也就是\(\ne\),這個應該都學過
將來我們還要學到位運算
保留精力,以後再講
下一章 -> while , do while
課後作業
沒錯,以後每次都有課後作業了
可以考慮截屏,也可以發文本,要求必須是可執行程式
給定一個長度為N的數列,第一行先輸入N,第二行,輸入N個用空格隔開的數字,原樣輸出N個數字,用空格隔開,要求必須使用數組
給定一個長度為N的數列,第一行先輸入N,第二行,輸入N個用空格隔開的數字,原樣輸出N個數字,用空格隔開,要求不能使用數組
給定一個數字N,要求你輸出一行數字,分別為N,N-1,N-2,N-3,...,1(倒序輸出))中間用空格隔開
給定一個數字N,要求你輸出一行數字,分別為1,2,3,4,...,N-1,N(正序輸出))中間用空格隔開
給定一個字元串,以換行為結尾,要求你原樣輸出而且不使用字元數組或者字元串
While語句
格式
while(判斷條件)
{
語句1;
語句2;
}while(判斷條件) 語句1;就是上面兩種
還有
while(T--) 上面的寫法比較常見,因為首先是判斷T的值,再去減,和下麵的語句等價
while(T) T--;T本身是一個數字,而這個數字也可以用來表示判斷的條件,當這個數字是0的時候T不是真,否則T$\geqslant$1的時候T這個數字作為判斷條件為真,也就是
| 數的值 | 判斷的結果 |
|---|---|
| = 0 | 假 |
| $\geqslant$1 | 真 |
所以這個時候,只有T一直減直到為0的時候停止迴圈
為了簡便我們一般採用兩種語句的前者
舉個例子
int i=10;
while(i--)
{
printf("%d ",i);
}得到的結果請自己思考
Do While語句
這個語句與While語句不同的原因是:
先執行do裡面的語句再去判斷while裡面的判斷條件是否成立,而while和for都是先看的條件是否成立
do
{
...
}
while(判斷條件);或者
do 一個語句
while(判斷條件);就是看著不舒服
記得一定要在while後面加分號
一個活生生的例子
int i=10;
do i--,printf("%d ",i);
while(i>1);結果還是讀者自己思考
下麵講 -> 判斷語句和運算符優先順序
Part 5 判斷語句和優先順序
判斷語句也不多,就兩種
if 語句
if(判斷條件) 一個語句;if(判斷條件)
{
語句1;
語句2;
語句3;
...
}else語句一般是指,在不滿足與它匹配的if中判斷條件的前提下執行else內的語句
if(a==1) printf("1");
else printf("0");
if(a==1) printf("1");
if(a!=1) printf("1");上面兩句話等價
註意,else必須與if對應,每個else都必須有一個if對應,不然就不對,因為這樣就沒有反面的判斷條件了
if()
{
if()
{
if()
{
...
}
else
{
}
}
else
{
}
}
else
{
}if和else可以相互嵌套,但是不能只有else沒有if
判斷條件前面講過了,不懂得私信我
switch 語句
一個活脫脫的例子
#include<cstdio>
using namespace std;
int main ()
{
char grade=getchar();
switch(grade)
{
case 'A' :puts("真棒!");break;
case 'B' :puts("好樣的!");break;
case 'C' :puts("再試一下?");break;
case 'D' :puts("過關!");break;
case 'E' :puts("不過關!");break;
default :puts("成績無效!");
}
printf("您的成績是:%c\n",grade);
return 0;
}switch(變數)
{
case 1 :
case 2 :
case 3 :
...
default :
}其中的case多少可變,而且這個case後面跟的參數是當變數為此參數時執行這個命令,也就相當於
if(變數 == case參數) 執行語句;case後面的語句可以是多個的
變數可以不是int類型的,case參數以變數為準,比如下麵的也是可以的
switch(grade)
{
case 'A' :puts("真棒!");break;
case 'B' :puts("好樣的!");break;
case 'C' :puts("再試一下?");break;
case 'D' :puts("過關!");break;
case 'E' :puts("不過關!");break;
default :puts("成績無效!");
}這個地方枚舉的是等級的字元
default就是當上面的所有case條件全部不滿足,那麼就執行當前語句
比如上面那個程式我們如果輸入的是F,那麼得到的就是成績無效
需要記住的是 - 字元類型的是'字元',而字元串是"字元串",一個是單引號,一個是雙引號
也就是說:
char c;
if(c=='A') return 0;//正確
if(c=="A") return 0;//錯誤
putchar('A');//正確
putchar("A");//錯誤在判斷語句中間,字元串不能夠直接比較,有一個函數但是不推薦
一般這個雙引號是這樣的
printf("字元串");
puts("字元串");一般可以認為puts輸出完字元串之後會自動換行,但是printf不會。
puts比printf塊
關於break和continue的事情
break
表示退出當前迴圈/判斷,必須單獨成為一個語句
continue
表示跳過當前迴圈/判斷,繼續下個迴圈內容,必須單獨成為一個語句
很早以前的書中還有goto這種操作,但是太隨意了,被人們扔了,所以不能使用,現在沒有什麼書上有,也沒人用
switch(grade)
{
case 'A' :puts("真棒!");break;
case 'B' :puts("好樣的!");break;
case 'C' :puts("再試一下?");break;
case 'D' :puts("過關!");break;
case 'E' :puts("不過關!");break;
default :puts("成績無效!");
}所以這段話中的case後面的break就是跳出當前判斷,如果不加上的話,程式將繼續查看後面的case值,直到遇見下一個break或者最後的default才會跳出
所以default的break語句不是必須的
優先順序
優先順序比較好理解,就是*/號比+-的優先順序高,在沒有括弧的前提下,先執行運算級高的部分 感謝小學數學老師
所以,在C++中的運算符操作一樣是有優先順序的
具體內容參照C++運算符優先順序
Part 6 C++ 基本運算
C++中的數學運算
| 原來數學中代表的內容 | 在C++裡面 |
|---|---|
| × | * |
| ÷ | / |
| + | + |
| - | - |
| ^ | pow(a,b)也就是(\(a^b\)) |
| mod(取餘) | % |
需要註意的是,當整數/另一個整數 , 得到的結果將會取整,也就是說
4/3 == 1%號代表的是一個數除另外一個數的餘數,我們知道,一個數除另一個數有兩個結果 - 商 和 餘數
這個商就是/,餘數就是%
規定/,%後面不能為0,不然報錯誤 - 浮點數例外(Linux特產)
還有一個特別屌絲的東西 :
位運算
位運算是什麼?首先我們需要瞭解二進位是什麼
二進位也就是我們所說的非零即一,所有的數字都可以表示成0和1組合的數字。
因為某些匹克操作,二進位十分的強大,所以被用來搞事情
先來瞭解一下進位轉換
\(N\)進位轉\(10\)進位
這個看著比較騷,實際上還好
也就是每個位上的數字去乘進位數的當前所在位-1次方,舉個例子
\[1 + 1 = 10_{(2)}\]
為什麼呢?因為
\[10_{(2)} = 0*2^0+1*2^1\]
好了講了半天(才五行)那麼我們繼續講怎麼實現
int r,len = n,sum=0;//r進位,len為數字長度(數字有多少位),sum為總和,也就是在10禁止下的數字
for(int i=1;i<=n;i++) sum = sum + a[i] * pow(r,i-1);
printf("%d",sum);至於pow是什麼看下麵:
C++有一個庫,包含各種騷操作
#include<cmath>
double acos(double x)
返回x的反餘弦弧度。
double asin(double x)
返回x的正弦弧線弧度。
double atan(double x)
返回x的反正切值,以弧度為單位。
double atan2(doubly y, double x)
返回y / x的以弧度為單位的反正切值,根據這兩個值,以確定正確的象限上的標誌。
double cos(double x)
返回的弧度角x的餘弦值。
double cosh(double x)
返回x的雙曲餘弦。
double sin(double x)
返回一個弧度角x的正弦。
double sinh(double x)
返回x的雙曲正弦。
double tanh(double x)
返回x的雙曲正切。
double exp(double x)
返回e值的第x次冪。
double frexp(double x, int *exponent)
返回的值是尾數,而指數的整數yiibaied是指數。 結果值是x =尾數* 2 ^指數。 (translate by google )
double ldexp(double x, int exponent)
返回x乘以2,增加到指數冪。(translate by google )
double log(double x)
返回自然對數的x(基準-E對數)。
double log10(double x)
返回x的常用對數(以10為底)。
double modf(double x, double *integer)
返回的值是小數成分(小數點後的部分),並設置整數的整數部分。
double pow(double x, double y)
返回x的y次方。
double sqrt(double x)
返回x的平方根。
double ceil(double x)
返回大於或等於x的最小整數值。
double fabs(double x)
返回x的絕對值
double floor(double x)
返回的最大整數值小於或等於x。
double fmod(double x, double y)
返回的x除以y的餘數。要用的時候加個頭文件,按照規範使用就行,只要背一些常用的就行。
需要註意的是 : C++中間在運算的時候不像現代數學有大括弧中括弧花括弧,不管是什麼都是小括弧
printf("%d",((a+b)*c+d)/e)對,中間用的就是小括弧,不管怎樣都是小括弧
\(10\)進位轉\(N\)進位
我相信這個都不會
會的略過
簡單來講,就是10 -> N進位的方式
其實就是原數不斷除進位數,記錄餘數,然後反著組成
舉個例子 :
\[10_{(10)} = 1010_(2)\]
10 % 2 = 0,10 / 2 = 5;
5 % 2 = 1,5 / 2 = 2;
2 % 2 = 0,2 / 2 = 1;
1 % 2 = 1,1 / 2 = 0;
演算法結束倒序輸出,也就是1010,答案是對的沒錯
用程式表達也就是
int sum=n,r,len=0,ans[105];//sum表示十進位數,r表示要轉換的進位數,len表示r進位數的長度,ans存答案
while(sum)
{
ans[++len]=sum % r;
sum = sum / r;
}
for(int i=len;i>=1;i--) printf("%d",ans[i]);有關位運算的操作
這種騷事C++也能幹出來
操作也不多,就那幾個,但是理解需要時間
&
^
|
<<
>>就這五個,嗯
我一個一個講吧
&
按位與,至於按位怎麼來的我想應該是因為它一位一位看吧哈哈哈
舉個例子
1010101
&101010
也就是
在一個位上,如果都是1,那麼就是1,否則為0,如果有一個位另外一個數字沒有,那麼那個數字的哪一位是0,自動補零,一般寫出來省略0
所以答案就是
0000000
也就是0
舒不舒服哈哈哈
^
按位異或
可以理解成兩個數字某一位上的數字相同的時候是0,不同的時候是1,那麼為什麼不反過來呢?數字前面的前置零怎麼辦!
舉例更好理解
1010101
^101010
1111111
矮油我去,怎麼又全是1了?
明明就是這樣balabala
|
按位或
可以理解為兩個數字某一位上的數字中至少1個是1的時候答案是1,否則就是0
也就是說
1010101
|101010
1111111
矮油怎麼還是1111111?受不了換樣例!
屁事多!
11111111
|1111111
11111111
湊合著看吧
<<
左移,可以理解成*2,因為它就是把一個數字在最後加上一個0
>>
右移,可以理解成/2,因為它就是把一個數字的最後一位去掉
這就是位運算
***
運算符
在C的語言中,有這樣的操作,支持快速的賦值
a += b;
a -= b;
a *= b;
a /= b;
a %= b;
a &= b;
a ^= b;
a |= b;
a <<= b;
a >>= b;這個操作是從右向左的,也就是說,下麵這個式子等價於:
a += a *= a /= a-6;
//等價於
a /= a-6;
a *= a;
a += a; 那麼這些操作符是什麼呢?這些操作符表達的意義也就是
a += b;
a = a + b;
a -= b;
a = a - b;
a *= b;
a = a * b;
a /= b;
a = a / b;
a %= b;
a = a % b;
a &= b;
a = a & b;
a ^= b;
a = a ^ b;
a |= b;
a = a | b;
a <<= b;
a = a << b;
a >>= b;
a = a >> b;常量
也就是一個一直保持不變的量,這個時候有兩種定義方式
define
#define可以理解成文本替換,用法簡單
#define 替換文本 目標文本註意,最後沒有分號,所以我們不能在define後面寫註釋,因為這樣很有可能一起替換了
舉個例子
#define LL long long
#define maxn 10005
#define max(a,b) ((a>b) ? a : b)然後這個時候就可以
#include<cstdio>
using namespace std;
#define LL long long
#define maxn 10005
#define max(a,b) ((a>b) ? a : b)
int main()
{
LL a=1,b=2,c=maxn;
printf("%lld %lld",max(a,b),c);
return 0;
}運行結果是
2 10005其中的
(a>b) ? a : b是一個三目運算符,它可以簡單理解為
(判斷條件) ? 語句1 (成立才執行) : 語句2 (否則,不成立才執行)等價於
if(判斷條件) 語句1;
else 語句2;然後#define就這樣用,一般還有
#define int long long也是可以的,但是主函數怎麼辦?沒關係,
signed = signed int = int所以我們可以考慮這樣寫
signed main()其實#define主要是替換內容,但是const是真正的賦初值
const
#include<cstdio>
using namespace std;
#define LL long long
const int maxn = 10005;
#define max(a,b) ((a>b) ? a : b)
int main()
{
LL a=1,b=2,c=maxn;
printf("%lld %lld",max(a,b),c);
return 0;
}答案和用#define的一樣,格式是
const 變數類型 變數名 = 初始值 ;註意,const後面有分號
在編譯的時候,如果用#define而define的變數出錯,它會提示你你替換的那個目標文本有問題,而不是你原來的文本有問題,但是const就會明確告訴你變數名,是哪個變數出錯一清二楚
還有,#define後面不能接0x3f3f3f3f和0x7fffffff,但是const可以
基礎內容講解完畢! 有什麼不懂的可以私信我,大膽地提問沒關係
課後作業
寫出一個判斷閏年的程式,要求輸入一個數字代表年份,一行輸出,如果是閏年則輸出
Yes,如果不是那麼輸出No,判斷規則是:能被4整除的 大多 是閏年,能被100整除而不能被400整除的年份不是閏年,能被400整除的是閏年,能被3200整除的也不是閏年陶陶家的院子里有一棵蘋果樹,每到秋天樹上就會結出 10 個蘋果。蘋果成熟的時候,陶陶就會跑去摘蘋果。陶陶有個 30 釐米高的板凳,當她不能直接用手摘到蘋果的時候,就會踩到板凳上再試試。
現在已知 10 個蘋果到地面的高度,以及陶陶把手伸直的時候能夠達到的最大高度,請幫陶陶算一下她能夠摘到的蘋果的數目。假設她碰到蘋果,蘋果就會掉下來。
輸入包括兩行數據。第一行包含 10 個 100 到 200 之間(包括 100 和 200 )的整數(以釐米為單位)分別表示 10 個蘋果到地面的高度,兩個相鄰的整數之間用一個空格隔開。第二行只包括一個 100 到 120 之間(包含 100 和 120 )的整數(以釐米為單位),表示陶陶把手伸直的時候能夠達到的最大高度。
輸出一行,這一行只包含一個整數,表示陶陶能夠摘到的蘋果的數目。[Noip普及組2005年]
某校大門外長度為L的馬路上有一排樹,每兩棵相鄰的樹之間的間隔都是 1 米。我們可以把馬路看成一個數軸,馬路的一端在數軸 0 的位置,另一端在 L 的位置;數軸上的每個整數點,即 0,1,2,…,L,都種有一棵樹。
由於馬路上有一些區域要用來建地鐵。這些區域用它們在數軸上的起始點和終止點表示。已知任一區域的起始點和終止點的坐標都是整數,區域之間可能有重合的部分。現在要把這些區域中的樹(包括區域端點處的兩棵樹)移走。你的任務是計算將這些樹都移走後,馬路上還有多少棵樹。
輸入輸出格式
輸入格式:
第一行有 2個整數 L(1\(\le\)L$\le$10000)和 M(1 \(\le\)M$\le$100), L 代表馬路的長度, M 代表區域的數目, L 和 M 之間用一個空格隔開。
接下來的 M 行每行包含 2 個不同的整數,用一個空格隔開,表示一個區域的起始點和終止點的坐標。輸出格式:
1 個整數,表示馬路上剩餘的樹的數目。[Noip普及組2005年]
津津上初中了。媽媽認為津津應該更加用功學習,所以津津除了上學之外,還要參加媽媽為她報名的各科複習班。另外每周媽媽還會送她去學習朗誦、舞蹈和鋼琴。但是津津如果一天上課超過八個小時就會不高興,而且上得越久就會越不高興。假設津津不會因為其它事不高興,並且她的不高興不會持續到第二天。請你幫忙檢查一下津津下周的日程安排,看看下周她會不會不高興;如果會的話,哪天最不高興。
輸入輸出格式
輸入格式:
輸入包括 7 行數據,分別表示周一到周日的日程安排。每行包括兩個小於 10 的非負整數,用空格隔開,分別表示津津在學校上課的時間和媽媽安排她上課的時間。輸出格式:
一個數字。如果不會不高興則輸出 0,如果會則輸出最不高興的是周幾(用 1, 2, 3, 4, 5, 6, 7分別表示周一,周二,周三,周四,周五,周六,周日)。如果有兩天或兩天以上不高興的程度相當,則輸出時間最靠前的一天。[Noip普及組2004年]
某校的慣例是在每學期的期末考試之後發放獎學金。發放的獎學金共有五種,獲取的條件各自不同:
院士獎學金,每人8000元,期末平均成績高於80分(>80),並且在本學期內發表11篇或11篇以上論文的學生均可獲得;
五四獎學金,每人4000元,期末平均成績高於85分(>85),並且班級評議成績高於80分(>80)的學生均可獲得;
成績優秀獎,每人2000元,期末平均成績高於90分(>90)的學生均可獲得;
西部獎學金,每人1000元,期末平均成績高於85分(>85)的西部省份學生均可獲得;
班級貢獻獎,每人 850 元,班級評議成績高於80分(>80)的學生幹部均可獲得;
只要符合條件就可以得獎,每項獎學金的獲獎人數沒有限制,每名學生也可以同時獲得多項獎學金。例如姚林的期末平均成績是87分,班級評議成績82分,同時他還是一位學生幹部,那麼他可以同時獲得五四獎學金和班級貢獻獎,獎金總數是4850元。現在給出若幹學生的相關數據,請計算哪些同學獲得的獎金總數最高(假設總有同學能滿足獲得獎學金的條件)。
輸入輸出格式
輸入格式:
第一行是 1 個整數 N(1\(\le\)N$\le$100),表示學生的總數。接下來的 N 行每行是一位學生的數據,從左向右依次是姓名,期末平均成績,班級評議成績,是否是學生幹部,是否是西部省份學生,以及發表的論文數。姓名是由大小寫英文字母組成的長度不超過 20的字元串(不含空格);期末平均成績和班級評議成績都是0到100之間的整數(包括 0 和 100 );是否是學生幹部和是否是西部省份學生分別用1個字元表示,Y表示是,N表示不是;發表的論文數是0到10的整數(包括 0 和 10 )。每兩個相鄰數據項之間用一個空格分隔。
輸出格式:
包括 3 行。第 1 行是獲得最多獎金的學生的姓名。
第 2 行是這名學生獲得的獎金總數。如果有兩位或兩位以上的學生獲得的獎金最多,輸出他們之中在輸入文件中出現最早的學生的姓名。
第 3 行是這 N 個學生獲得的獎學金的總數。
提示: 名字用字元數組,
scanf %s輸入,printf %s輸出[Noip提高組2005年]


