
C++知識庫總結(用來記錄日常接觸到的C++知識點),將會持續更新 ...
1.重載函數是否能夠通過函數返回值的類型不同來區分?
不可以。因為在C++編程中,函數的返回值可以忽略(不使用其返回值),程式中調用此時函數名相同和參數相同的兩個函數對編譯器和程式員來說是沒有辦法區分的,編譯器會提示出錯。
2.C++多態機制的實現
(1)重載:同一個類中同一個函數的不同實現,必須保證函數參數不同(類型,個數,順序),本質上與多態無關。使用重載函數,編譯器會根據函數的名稱和參數定義來生成函數的內部標識符,保證每個函數的標識符是唯一的,這樣在鏈接時就可以鏈接到對應的函數。重載屬於靜態綁定,在編譯過程中就能確定調用哪一個函數,是早期綁定,與多態原理不同。
(2)覆蓋:也稱為重寫,子類中對父類的同名函數同參數的重寫,父類的函數必須設置為虛函數,這樣保證使用基類指針或者引用指向不同的子類對象可以動態調用屬於具體子類的方法而不是調用基類的方法,從而實現多態。
PS:C++中 多態一般預設是指動態多態(通過類繼承機制和虛函數機制實現),是在運行時確定的,在面向對象編程中直接被稱為多態,而靜態多態一般是指使用函數重載或者模板機制實現的。模板也允許將不同的特殊行為和單個泛化記號相關聯,由於這種關聯處理於編譯期而非運行期,因此被稱為“靜態”。可以用來實現類型安全、運行高效的同質對象集合操作。C++ 的STL庫大量使用了模板機制來實現,而並沒有使用虛函數機制,屬於靜態多態。
詳情可以參考以下博客:https://blog.csdn.net/sinat_20265495/article/details/50112311
3.隊列和棧的共同點以及不同點(C++版本)
隊列:這裡只說單向隊列,就是我們平常所說的FIFO隊列,它滿足先進先出的規則,即只能在隊尾插入元素,提取元素只能在隊頭。(C++裡面提供了queue容器作為單向隊列的實現)
棧:棧滿足LIFO規則(後進先出),插入和取出操作只能在棧頂進行(C++提供了stack容器作為棧的實現)
相同點:都是線性表結構,並且只能在端點進行數據的插入和讀取(受限制的線性表結構),都不能進行隨機存取,都不支持遍歷(不開臨時空間),在C++ stl中可以採用deque作為兩者的底層容器;
不同點:棧和隊列的操作不同,棧只能線上性表的一端進行插入和刪除,而隊列則是只能在表的一端進行插入,在另一端進行刪除;棧符合LIFO原則,而隊列符合FIFO原則,即滿足隊列的操作原則;
具體可以參考這篇博客:https://blog.csdn.net/zqixiao_09/article/details/51474589
4.模板(函數模板、類模板)
可以參考這篇博客:https://blog.csdn.net/sinat_20265495/article/details/50112311
5.C++記憶體模型(記憶體佈局)
一般來說,一個C++程式所分配的記憶體空間主要分為五個部分:堆、棧、靜態存儲區、代碼段
根據C++中類的情況,可以分為以下幾種情況進行討論:
單一類:
(1)空類:占據一個位元組,用於標識這個類是一個空類,沒有實際含義,使用sizeof操作符可以看到大小為1個位元組。

(2)只有成員變數的類:該類的大小為所有普通成員變數所占據的記憶體大小的和(靜態成員變數並不存放在對象的記憶體空間中),記憶體佈局如下圖所示,可以看出在記憶體中是按照變數聲明的順序存放的。
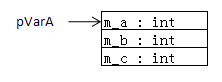
(3)只有虛函數的類:根據虛函數的實現機制,該類的對象所占據的記憶體只有一個虛函數表指針(vfptr),指向一個虛函數表,該表按照函數的聲明順序存儲著虛函數的函數指針。記憶體佈局如下所示:

從上面我們可以看到,在該類的對象中,只存放一個虛函數表指針,它指向虛函數表,虛函數表並沒有存放在對象的記憶體空間中。該類的對象的大小為虛函數表指針大大小(64位系統為8個位元組,32位系統則為4個位元組)
(4)既有虛函數,又有成員變數的類
這樣的類的對象記憶體中既有虛函數表指針,又有成員變數(按照聲明的順序存放),記憶體佈局如下圖所示: https://blog.csdn.net/it_yuan/article/details/24651347

單繼承、多繼承的情況則比較複雜,此處不進行詳細分析,具體可以自己網上找一下或者參考以下這篇博客: https://blog.csdn.net/it_yuan/article/details/24651347
6.函數調用壓棧出棧過程及參數入棧順序
函數對應的棧其實是棧幀,由系統從系統棧(記憶體中的棧空間)劃分一定大小的空間給函數,函數獨占該棧幀,棧幀裡面存放著該函數執行時的局部變數 、上一個棧幀的ESP和EBP、函數調用的返回地址(函數的後面的指令的地址),在函數調用過程中涉及了棧幀的分配、切換和釋放,不同操作系統、不同語言、不同編譯器的實現機制基本相同,但是具體的實現細節有所不同,例如參數壓棧出棧的順序等。具體可以參考以下博客(個人覺得兩位大神的分析特別詳細):
https://blog.csdn.net/u011555996/article/details/70211315
https://www.cnblogs.com/roy-blog/p/6367093.html
7.C++ inline原理(註意與define的區別和聯繫)
inline是C++的一種機制,作用於函數,將一個函數聲明為inline,可以讓編譯器在編譯代碼時,將“對此函數的每一個調用”都以函數本體替換之,該過程發生在編譯期間。inline的優點是:它可以省去函數調用所帶來的額外開銷,提高程式的速度。缺點也很明顯:首先,過分使用inline函數會導致代碼膨脹,占用過多記憶體和硬碟空間;其次,在升級inline函數時,需要所有引用它的模塊都要重新編譯。
綜合以上說明,inline一般用於函數體比較小,頻繁切換的函數上面。另外需要強調的一點是,千萬不要將構造或析構函數inline。原因是,這種函數往往看起來是空的,而實際上在編譯期間會生成很多代碼,如果將它們inline了,很容易就會導致代碼膨脹。
8.define和const的區別
const是定義了一種數據類型,被其修飾的變數會被系統分配記憶體空間,存放在靜態存儲區,在編譯時會進行類型檢查,而define定義的常量本質上是一種巨集替換,不是一種數據類型,系統不會為其分配記憶體空間,巨集定義的常量在預處理的時候會被替換,不會進行類型檢查。
具體差異可以參考這篇博客:https://blog.csdn.net/yingyujianmo/article/details/51206460
9.虛繼承和虛基類表、虛基類表指針
虛繼承是為瞭解決多重繼承中派生類對象記憶體同時存在多份虛基類的實體而提出的,當使用虛繼承時,派生類中最多保存一份虛基類的實體,但是需要在記憶體中增加虛基類表指針。具體可以參考 以下博客:
https://blog.csdn.net/bxw1992/article/details/77726390
10.C++ 11多線程 thread庫
C++11標準中新增了對多線程的標準庫支持,使多線程程式的開發更加方便,主要是通過thread類來創建、調度、運行線程,並提供了大量多線程操作的API,可以說是伺服器端開發的一大神器,具體可以參考這篇博客,講得很詳細,這裡就不再贅述。
https://www.cnblogs.com/wangguchangqing/p/6134635.html#autoid-3-0-0


