
1. Apache Kafka是一個分散式流平臺 1.1 流平臺有三個關鍵功能: 1.2 Kafka通常用於兩大類應用: 1.3 有幾個特別重要的概念: Kafka is run as a cluster on one or more servers that can span multiple d ...
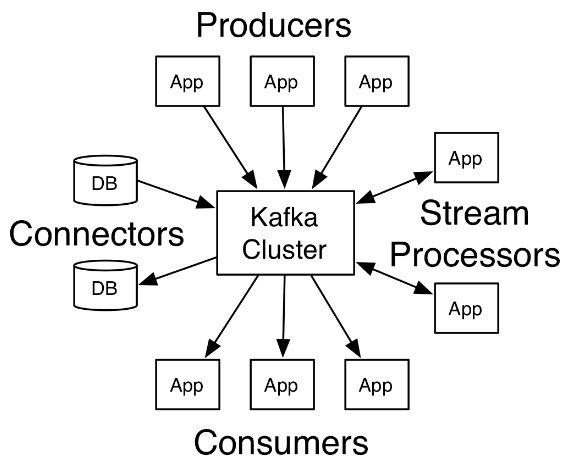
1. Apache Kafka是一個分散式流平臺
1.1 流平臺有三個關鍵功能:
- 發佈和訂閱流記錄,類似於一個消息隊列或企業消息系統
- 以一種容錯的持久方式存儲記錄流
- 在流記錄生成的時候就處理它們
1.2 Kafka通常用於兩大類應用:
- 構建實時流數據管道,在系統或應用程式之間可靠地獲取數據
- 構建對數據流進行轉換或輸出的實時流媒體應用程式
1.3 有幾個特別重要的概念:
Kafka is run as a cluster on one or more servers that can span multiple datacenters.
The Kafka cluster stores streams of records in categories called topics.
Each record consists of a key, a value, and a timestamp.
Kafka作為集群運行在一個或多個可以跨多個數據中心的伺服器上
從這句話表達了三個意思:
- Kafka是以集群方式運行的
- 集群中可以只有一臺伺服器,也有可能有多台伺服器。也就是說,一臺伺服器也是一個集群,多台伺服器也可以組成一個集群
- 這些伺服器可以跨多個數據中心
Kafka集群按分類存儲流記錄,這個分類叫做主題
這句話表達了以下幾個信息:
- 流記錄是分類存儲的,也就說記錄是歸類的
- 我們稱這種分類為主題
- 簡單地來講,記錄是按主題劃分歸類存儲的
每個記錄由一個鍵、一個值和一個時間戳組成
1.4 Kafka有四個核心API:
- Producer API :允許應用發佈一條流記錄到一個或多個主題
- Consumer API :允許應用訂閱一個或多個主題,並處理流記錄
- Streams API :允許應用作為一個流處理器,從一個或多個主題那裡消費輸入流,並將輸出流輸出到一個或多個輸出主題,從而有效地講輸入流轉換為輸出流
- Connector API :允許將主題連接到已經存在的應用或者數據系統,以構建並允許可重用的生產者或消費者。例如,一個關係型資料庫的連接器可能捕獲到一張表的每一次變更
(畫外音:我理解這四個核心API其實就是:發佈、訂閱、轉換處理、從第三方採集數據。)
在Kafka中,客戶端和伺服器之間的通信是使用簡單的、高性能的、與語言無關的TCP協議完成的。
2. Topics and Logs(主題和日誌)
一個topic是一個分類,或者說是記錄被髮布的時候的一個名字(畫外音:可以理解為記錄要被髮到哪兒去)。
在Kafka中,topic總是有多個訂閱者,因此,一個topic可能有0個,1個或多個訂閱該數據的消費者。
對於每個主題,Kafka集群維護一個分區日誌,如下圖所示:
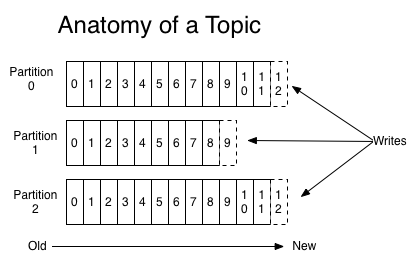
每個分區都是一個有序的、不可變的記錄序列,而且記錄會不斷的被追加,一條記錄就是一個結構化的提交日誌(a structured commit log)。
分區中的每條記錄都被分配了一個連續的id號,這個id號被叫做offset(偏移量),這個偏移量唯一的標識出分區中的每條記錄。(PS:如果把分區比作資料庫表的話,那麼偏移量就是主鍵)
Kafka集群持久化所有已發佈的記錄,無論它們有沒有被消費,記錄被保留的時間是可以配置的。例如,如果保留策略被設置為兩天,那麼在記錄發佈後的兩天內,可以使用它,之後將其丟棄以釋放空間。在對數據大小方面,Kafka的性能是高效的,恆定常量級的,因此長時間存儲數據不是問題。
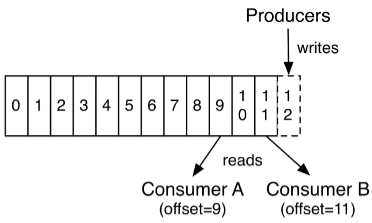
事實上,唯一維護在每個消費者上的元數據是消費者在日誌中的位置或者叫偏移量。偏移量是由消費者控制的:通常消費者在讀取記錄的時候會線性的增加它的偏移量,但是,事實上,由於位置(偏移量)是由消費者控制的,所有它可以按任意它喜歡的順序消費記錄。例如:一個消費者可以重置到一個較舊的偏移量來重新處理之前已經處理過的數據,或者跳轉到最近的記錄並從“現在”開始消費。
這種特性意味著消費者非常廉價————他們可以來來去去的消息而不會對集群或者其它消費者造成太大影響。
日誌中的分區有幾個用途。首先,它們允許日誌的規模超出單個伺服器的大小。每個獨立分區都必須與宿主的伺服器相匹配,但一個主題可能有多個分區,所以它可以處理任意數量的數據。第二,它們作為並行的單位——稍後再進一步。
(
畫外音:簡單地來說,日誌分區的作用有兩個:一、日誌的規模不再受限於單個伺服器;二、分區意味著可以並行。
什麼意思呢?主題建立在集群之上,每個主題維護了一個分區日誌,顧名思義,日誌是分區的;每個分區所在的伺服器的資源(比如:CPU、記憶體、帶寬、磁碟等)是有限的,如果不分區(可以理解為等同於只有一個)的話,必然受限於這個分區所在的伺服器,那麼多個分區的話就不一樣了,就突破了這種限制,伺服器可以隨便加,分區也可以隨便加。
)
3. Distribution(分佈)
日誌的分區分佈在集群中的伺服器上,每個伺服器處理數據,並且分區請求是共用的。每個分區被覆制到多個伺服器上以實現容錯,到底複製到多少個伺服器上是可以配置的。
Each partition is replicated across a configurable number of servers for fault tolerance.
每個分區都有一個伺服器充當“leader”角色,並且有0個或者多個伺服器作為“followers”。leader處理對這個分區的所有讀和寫請求,而followers被動的從leader那裡複製數據。如果leader失敗,followers中的其中一個會自動變成新的leader。每個伺服器充當一些分區的“leader”的同時也是其它分區的“follower”,因此在整個集群中負載是均衡的。
也就是說,每個伺服器既是“leader”也是“follower”。我們知道一個主題可能有多個分區,一個分區可能在一個伺服器上也可能跨多個伺服器,然而這並不以為著一臺伺服器上只有一個分區,是可能有多個分區的。每個分區中有一個伺服器充當“leader”,其餘是“follower”。leader負責處理這個它作為leader所負責的分區的所有讀寫請求,而該分區中的follow只是被動複製leader的數據。這個有點兒像HDFS中的副本機制。例如:分區-1有伺服器A和B組成,A是leader,B是follower,有請求要往分區-1中寫數據的時候就由A處理,然後A把剛纔寫的數據同步給B,這樣的話正常請求相當於A和B的數據是一樣的,都有分區-1的全部數據,如果A宕機了,B成為leader,接替A繼續處理對分區-1的讀寫請求。
需要註意的是,分區是一個虛擬的概念,是一個邏輯單元。
4. Producers(生產者)
生產者發佈數據到它們選擇的主題中。生產者負責選擇將記錄投遞到哪個主題的哪個分區中。要做這件事情,可以簡單地用迴圈方式以到達負載均衡,或者根據一些語義分區函數(比如:基於記錄中的某些key)
5. Consumers(消費者)
消費者用一個消費者組名來標識它們自己(PS:相當於給自己貼一個標簽,標簽的名字是組名,以表明自己屬於哪個組),並且每一條發佈到主題中的記錄只會投遞給每個訂閱的消費者組中的其中一個消費者實例。消費者實例可能是單獨的進程或者在單獨的機器上。
如果所有的消費者實例都使用相同的消費者組,那麼記錄將會在這些消費者之間有效的負載均衡。
如果所有的消費者實例都使用不同的消費者組,那麼每條記錄將會廣播給所有的消費者進程。
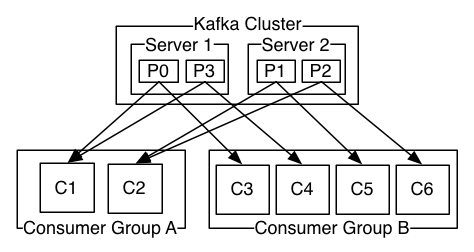
上圖中其實那個Kafka Cluster換成Topic會更準確一些
一個Kafka集群有2個伺服器,4個分區(P0-P3),有兩個消費者組。組A中有2個消費者實例,組B中有4個消費者實例。
通常我們會發現,主題不會有太多的消費者組,每個消費者組是一個“邏輯訂閱者”(以消費者組的名義訂閱主題,而非以消費者實例的名義去訂閱)。每個組由許多消費者實例組成,以實現可擴展性和容錯。這仍然是發佈/訂閱,只不過訂閱者是一個消費者群體,而非單個進程。
在Kafka中,這種消費方式是通過用日誌中的分區除以使用者實例來實現的,這樣可以保證在任意時刻每個消費者都是排它的消費,即“公平共用”。Kafka協議動態的處理維護組中的成員。如果有心的實例加入到組中,它們將從組中的其它成員那裡接管一些分區;如果組中有一個實例死了,那麼它的分區將會被分給其它實例。
(畫外音:什麼意思呢?舉個例子,在上面的圖中,4個分區,組A有2個消費者,組B有4個消費者,那麼對A來講組中的每個消費者負責4/2=2個分區,對組B來說組中的每個消費者負責4/4=1個分區,而且同一時間消息只能被組中的一個實例消費。如果組中的成員數量有變化,則重新分配。)
Kafka只提供分區下的記錄的總的順序,而不提供主題下不同分區的總的順序。每個分區結合按key劃分數據的能力排序對大多數應用來說是足夠的。然而,如果你需要主題下總的記錄順序,你可以只使用一個分區,這樣做的做的話就意味著每個消費者組中只能有一個消費者實例。
6. 保證
在一個高級別的Kafka給出下列保證:
- 被一個生產者發送到指定主題分區的消息將會按照它們被髮送的順序追加到分區中。也就是說,如果記錄M1和M2是被同一個生產者發送到同一個分區的,而且M1是先發送的,M2是後發送的,那麼在分區中M1的偏移量一定比M2小,並且M1出現在日誌中的位置更靠前。
- 一個消費者看到記錄的順序和它們在日誌中存儲的順序是一樣的。
- 對於一個副本因數是N的主題,我們可以容忍最多N-1個伺服器失敗,而不會丟失已經提交給日誌的任何記錄。
7. Spring Kafka
Spring提供了一個“模板”作為發送消息的高級抽象。它也通過使用@KafkaListener註釋和“監聽器容器”提供對消息驅動POJOs的支持。這些庫促進了依賴註入和聲明式的使用。
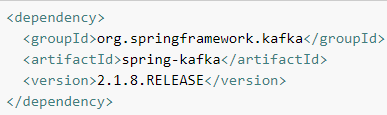
7.1 純Java方式
1 package com.cjs.example.quickstart; 2 3 import org.apache.kafka.clients.consumer.ConsumerConfig; 4 import org.apache.kafka.clients.consumer.ConsumerRecord; 5 import org.apache.kafka.clients.producer.ProducerConfig; 6 import org.apache.kafka.common.serialization.IntegerDeserializer; 7 import org.apache.kafka.common.serialization.IntegerSerializer; 8 import org.apache.kafka.common.serialization.StringDeserializer; 9 import org.apache.kafka.common.serialization.StringSerializer; 10 import org.springframework.kafka.core.*; 11 import org.springframework.kafka.listener.KafkaMessageListenerContainer; 12 import org.springframework.kafka.listener.MessageListener; 13 import org.springframework.kafka.listener.config.ContainerProperties; 14 15 import java.util.HashMap; 16 import java.util.Map; 17 18 public class PureJavaDemo { 19 20 /** 21 * 生產者配置 22 */ 23 private static Map<String, Object> senderProps() { 24 Map<String, Object> props = new HashMap<>(); 25 props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.101.5:9093"); 26 props.put(ProducerConfig.RETRIES_CONFIG, 0); 27 props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384); 28 props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class); 29 props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class); 30 return props; 31 } 32 33 /** 34 * 消費者配置 35 */ 36 private static Map<String, Object> consumerProps() { 37 Map<String, Object> props = new HashMap<>(); 38 props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.101.5:9093"); 39 props.put(ConsumerConfig.GROUP_ID_CONFIG, "hello"); 40 props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false); 41 props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "100"); 42 props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "15000"); 43 props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, IntegerDeserializer.class); 44 props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); 45 return props; 46 } 47 48 /** 49 * 發送模板配置 50 */ 51 private static KafkaTemplate<Integer, String> createTemplate() { 52 Map<String, Object> senderProps = senderProps(); 53 ProducerFactory<Integer, String> producerFactory = new DefaultKafkaProducerFactory<>(senderProps); 54 KafkaTemplate<Integer, String> kafkaTemplate = new KafkaTemplate<>(producerFactory); 55 return kafkaTemplate; 56 } 57 58 /** 59 * 消息監聽器容器配置 60 */ 61 private static KafkaMessageListenerContainer<Integer, String> createContainer() { 62 Map<String, Object> consumerProps = consumerProps(); 63 ConsumerFactory<Integer, String> consumerFactory = new DefaultKafkaConsumerFactory<>(consumerProps); 64 ContainerProperties containerProperties = new ContainerProperties("test"); 65 KafkaMessageListenerContainer<Integer, String> container = new KafkaMessageListenerContainer<>(consumerFactory, containerProperties); 66 return container; 67 } 68 69 70 public static void main(String[] args) throws InterruptedException { 71 String topic1 = "test"; // 主題 72 73 KafkaMessageListenerContainer container = createContainer(); 74 ContainerProperties containerProperties = container.getContainerProperties(); 75 containerProperties.setMessageListener(new MessageListener<Integer, String>() { 76 @Override 77 public void onMessage(ConsumerRecord<Integer, String> record) { 78 System.out.println("Received: " + record); 79 } 80 }); 81 container.setBeanName("testAuto"); 82 83 container.start(); 84 85 KafkaTemplate<Integer, String> kafkaTemplate = createTemplate(); 86 kafkaTemplate.setDefaultTopic(topic1); 87 88 kafkaTemplate.sendDefault(0, "foo"); 89 kafkaTemplate.sendDefault(2, "bar"); 90 kafkaTemplate.sendDefault(0, "baz"); 91 kafkaTemplate.sendDefault(2, "qux"); 92 93 kafkaTemplate.flush(); 94 container.stop(); 95 96 System.out.println("結束"); 97 } 98 99 }
運行結果:
Received: ConsumerRecord(topic = test, partition = 0, offset = 67, CreateTime = 1533300970788, serialized key size = 4, serialized value size = 3, headers = RecordHeaders(headers = [], isReadOnly = false), key = 0, value = foo) Received: ConsumerRecord(topic = test, partition = 0, offset = 68, CreateTime = 1533300970793, serialized key size = 4, serialized value size = 3, headers = RecordHeaders(headers = [], isReadOnly = false), key = 2, value = bar) Received: ConsumerRecord(topic = test, partition = 0, offset = 69, CreateTime = 1533300970793, serialized key size = 4, serialized value size = 3, headers = RecordHeaders(headers = [], isReadOnly = false), key = 0, value = baz) Received: ConsumerRecord(topic = test, partition = 0, offset = 70, CreateTime = 1533300970793, serialized key size = 4, serialized value size = 3, headers = RecordHeaders(headers = [], isReadOnly = false), key = 2, value = qux)
7.2 更簡單一點兒,用SpringBoot
1 package com.cjs.example.quickstart; 2 3 import org.apache.kafka.clients.consumer.ConsumerRecord; 4 import org.springframework.beans.factory.annotation.Autowired; 5 import org.springframework.boot.CommandLineRunner; 6 import org.springframework.context.annotation.Bean; 7 import org.springframework.context.annotation.Configuration; 8 import org.springframework.kafka.annotation.KafkaListener; 9 import org.springframework.kafka.core.KafkaTemplate; 10 11 @Configuration 12 public class JavaConfigurationDemo { 13 14 @KafkaListener(topics = "test") 15 public void listen(ConsumerRecord<String, String> record) { 16 System.out.println("收到消息: " + record); 17 } 18 19 @Bean 20 public CommandLineRunner commandLineRunner() { 21 return new MyRunner(); 22 } 23 24 class MyRunner implements CommandLineRunner { 25 26 @Autowired 27 private KafkaTemplate<String, String> kafkaTemplate; 28 29 @Override 30 public void run(String... args) throws Exception { 31 kafkaTemplate.send("test", "foo1"); 32 kafkaTemplate.send("test", "foo2"); 33 kafkaTemplate.send("test", "foo3"); 34 kafkaTemplate.send("test", "foo4"); 35 } 36 } 37 }
application.properties配置
spring.kafka.bootstrap-servers=192.168.101.5:9092 spring.kafka.consumer.group-id=world
8. 生產者
1 package com.cjs.example.send; 2 3 import org.apache.kafka.clients.producer.ProducerConfig; 4 import org.apache.kafka.common.serialization.IntegerSerializer; 5 import org.apache.kafka.common.serialization.StringSerializer; 6 import org.springframework.context.annotation.Bean; 7 import org.springframework.context.annotation.Configuration; 8 import org.springframework.kafka.core.DefaultKafkaProducerFactory; 9 import org.springframework.kafka.core.KafkaTemplate; 10 import org.springframework.kafka.core.ProducerFactory; 11 12 import java.util.HashMap; 13 import java.util.Map; 14 15 @Configuration 16 public class Config { 17 18 public Map<String, Object> producerConfigs() { 19 Map<String, Object> props = new HashMap<>(); 20 props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.101.5:9092"); 21 props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class); 22 props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class); 23 return props; 24 } 25 26 public ProducerFactory<Integer, String> producerFactory() { 27 return new DefaultKafkaProducerFactory<>(producerConfigs()); 28 } 29 30 @Bean 31 public KafkaTemplate<Integer, String> kafkaTemplate() { 32 return new KafkaTemplate<Integer, String>(producerFactory()); 33 } 34 35 }
1 package com.cjs.example.send; 2 3 import org.springframework.beans.factory.annotation.Autowired; 4 import org.springframework.boot.CommandLineRunner; 5 import org.springframework.kafka.core.KafkaTemplate; 6 import org.springframework.kafka.support.SendResult; 7 import org.springframework.stereotype.Component; 8 import org.springframework.util.concurrent.ListenableFuture; 9 import org.springframework.util.concurrent.ListenableFutureCallback; 10 11 @Component 12 public class MyCommandLineRunner implements CommandLineRunner { 13 14 @Autowired 15 private KafkaTemplate<Integer, String> kafkaTemplate; 16 17 public void sendTo(Integer key, String value) { 18 ListenableFuture<SendResult<Integer, String>> listenableFuture = kafkaTemplate.send("test", key, value); 19 listenableFuture.addCallback(new ListenableFutureCallback<SendResult<Integer, String>>() { 20 @Override 21 public void onFailure(Throwable throwable) { 22 System.out.println("發送失敗啦"); 23 throwable.printStackTrace(); 24 } 25 26 @Override 27 public void onSuccess(SendResult<Integer, String> sendResult) { 28 System.out.println("發送成功," + sendResult); 29 } 30 }); 31 } 32 33 @Override 34 public void run(String... args) throws Exception { 35 sendTo(1, "aaa"); 36 sendTo(2, "bbb"); 37 sendTo(3, "ccc"); 38 } 39 40 41 }
運行結果:
發送成功,SendResult [producerRecord=ProducerRecord(topic=test, partition=null, headers=RecordHeaders(headers = [], isReadOnly = true), key=1, value=aaa, timestamp=null), recordMetadata=test-0@37] 發送成功,SendResult [producerRecord=ProducerRecord(topic=test, partition=null, headers=RecordHeaders(headers = [], isReadOnly = true), key=2, value=bbb, timestamp=null), recordMetadata=test-0@38] 發送成功,SendResult [producerRecord=ProducerRecord(topic=test, partition=null, headers=RecordHeaders(headers = [], isReadOnly = true), key=3, value=ccc, timestamp=null), recordMetadata=test-0@39]
9. 消費者@KafkaListener
1 package com.cjs.example.receive; 2 3 import org.apache.kafka.clients.consumer.ConsumerConfig; 4 import org.apache.kafka.clients.consumer.ConsumerRecord; 5 import org.apache.kafka.common.serialization.IntegerDeserializer; 6 import org.apache.kafka.common.serialization.StringDeserializer; 7 import org.springframework.context.annotation.Bean; 8 import org.springframework.context.annotation.Configuration; 9 import org.springframework.kafka.annotation.KafkaListener; 10 import org.springframework.kafka.annotation.TopicPartition; 11 import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory; 12 import org.springframework.kafka.config.KafkaListenerContainerFactory; 13 import org.springframework.kafka.core.ConsumerFactory; 14 import org.springframework.kafka.core.DefaultKafkaConsumerFactory; 15 import org.springframework.kafka.listener.AbstractMessageListenerContainer; 16 import org.springframework.kafka.listener.ConcurrentMessageListenerContainer; 17 import org.springframework.kafka.listener.config.ContainerProperties; 18 import org.springframework.kafka.support.Acknowledgment; 19 import org.springframework.kafka.support.KafkaHeaders; 20 import org.springframework.messaging.handler.annotation.Header; 21 import org.springframework.messaging.handler.annotation.Payload; 22 23 import java.util.HashMap; 24 import java.util.List; 25 import java.util.Map; 26 27 @Configuration 28 public class Config2 { 29 30 @Bean 31 public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<Integer, String>> kafkaListenerContainerFactory() { 32 ConcurrentKafkaListenerContainerFactory<Integer, String> factory = new ConcurrentKafkaListenerContainerFactory<>(); 33 factory.setConsumerFactory(consumerFactory()); 34 factory.setConcurrency(3); 35 ContainerProperties containerProperties = factory.getContainerProperties(); 36 containerProperties.setPollTimeout(2000); 37 // containerProperties.setAckMode(AbstractMessageListenerContainer.AckMode.MANUAL_IMMEDIATE); 38 return factory; 39 } 40 41 private ConsumerFactory<Integer,String> consumerFactory() { 42 return new DefaultKafkaConsumerFactory<>(consumerProps()); 43 } 44 45 private Map<String, Object> consumerProps() { 46 Map<String, Object> props = new HashMap<>(); 47 props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.101.5:9092"); 48 props.put(ConsumerConfig.GROUP_ID_CONFIG, "hahaha"); 49 // props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false); 50 props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, IntegerDeserializer.class); 51 props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); 52 return props; 53 } 54 55 56 @KafkaListener(topics = "test") 57 public void listen(String data) { 58 System.out.println("listen 收到: " + data); 59 } 60 61 62 @KafkaListener(topics = "test", containerFactory = "kafkaListenerContainerFactory") 63 public void listen2(String data, Acknowledgment ack) { 64 System.out.println("listen2 收到: " + data); 65 ack.acknowledge(); 66 } 67 68 @KafkaListener(topicPartitions = {@TopicPartition(topic = "test", partitions = "0")}) 69 public void listen3(ConsumerRecord<?, ?> record) { 70 System.out.println("listen3 收到: " + record.value()); 71 } 72 73 74 @KafkaListener(id = "xyz", topics = "test") 75 public void listen4(@Payload String foo, 76 @Header(KafkaHeaders.RECEIVED_MESSAGE_KEY) Integer key, 77 @Header(KafkaHeaders.RECEIVED_PARTITION_ID) int partition, 78 @Header(KafkaHeaders.RECEIVED_TOPIC) String topic, 79 @Header(KafkaHeaders.OFFSET) List<Long> offsets) { 80 System.out.println("listen4 收到: "); 81 System.out.println(foo); 82 System.out.println(key); 83 System.out.println(partition); 84 System.out.println(topic); 85 System.out.println(offsets); 86 } 87 88 }
9.1 Committing Offsets
如果enable.auto.commit設置為true,那麼kafka將自動提交offset。如果設置為false,則支持下列AckMode(確認模式)。
消費者poll()方法將返回一個或多個ConsumerRecords
- RECORD :處理完記錄以後,當監聽器返回時,提交offset
- BATCH :當對poll()返回的所有記錄進行處理完以後,提交偏offset
- TIME :當對poll()返回的所有記錄進行處理完以後,只要距離上一次提交已經過了ackTime時間後就提交
- COUNT :當poll()返回的所有記錄都被處理時,只要從上次提交以來收到了ackCount條記錄,就可以提交
- COUNT_TIME :和TIME以及COUNT類似,只要這兩個中有一個為true,則提交
- MANUAL :消息監聽器負責調用Acknowledgment.acknowledge()方法,此後和BATCH是一樣的
- MANUAL_IMMEDIATE :當監聽器調用Acknowledgment.acknowledge()方法後立即提交
10. Spring Boot Kafka
10.1 application.properties
spring.kafka.bootstrap-servers=192.168.101.5:9092
10.2 發送消息
1 package com.cjs.example; 2 3 import org.springframework.beans.factory.annotation.Autowired; 4 import org.springframework.kafka.core.KafkaTemplate; 5 import org.springframework.web.bind.annotation.RequestMapping; 6 import org.springframework.web.bind.annotation.RestController; 7 8 import javax.annotation.Resource; 9 10 @RestController 11 @RequestMapping("/msg") 12 public class MessageController { 13 14 @Resource 15 private KafkaTemplate<String, String> kafkaTemplate; 16 17 @RequestMapping("/send") 18 public String send(String topic, String key, String value) { 19 kafkaTemplate.send(topic, key, value); 20 return "ok"; 21 } 22 23 }
10.3 接收消息
1 package com.cjs.example; 2 3 import org.apache.kafka.clients.consumer.ConsumerRecord; 4 import org.springframework.kafka.annotation.KafkaListener; 5 import org.springframework.kafka.annotation.KafkaListeners; 6 import org.springframework.stereotype.Component; 7 8 @Component


