
Document(文檔)是Field(域)的承載體, 一個Document由多個Field組成. Field由名稱和值兩部分組成, 值是要索引的內容, 也是要搜索的內容. Lucene在記憶體中實現了分頁查詢, 這裡通過一個分頁查詢的demo演示分頁的過程. ...
目錄
1 Field的特性
Document(文檔)是Field(域)的承載體, 一個Document由多個Field組成. Field由名稱和值兩部分組成, Field的值是要索引的內容, 也是要搜索的內容.
是否分詞(tokenized)
是: 將Field的值進行分詞處理, 分詞的目的是為了索引. 如: 商品名稱, 商品描述. 這些內容用戶會通過輸入關鍵詞進行查詢, 由於內容多樣, 需要進行分詞處理建立索引.
否: 不做分詞處理. 如: 訂單編號, 身份證號, 是一個整體, 分詞以後就失去了意義, 故不需要分詞.
是否索引(indexed)
是: 將Field內容進行分詞處理後得到的詞(或整體Field內容)建立索引, 存儲到索引域. 索引的目的是為了搜索. 如: 商品名稱, 商品描述需要分詞建立索引. 訂單編號, 身份證號作為整體建立索引. 只要可能作為用戶查詢條件的詞, 都需要索引.
否: 不索引. 如: 商品圖片路徑, 不會作為查詢條件, 不需要建立索引.
是否存儲(stored)
是: 將Field值保存到Document中. 如: 商品名稱, 商品價格. 凡是將來在搜索結果頁面展現給用戶的內容, 都需要存儲.
否: 不存儲. 如: 商品描述. 內容多格式大, 不需要直接在搜索結果頁面展現, 不做存儲. 需要的時候可以從關係資料庫取.
2 常用的Field類型
以下是企業項目開發中常用的Field類型:
| Field類型 | 數據類型 | 是否分詞 | 是否索引 | 是否存儲 | 說明 |
|---|---|---|---|---|---|
| StringField(FieldName, FieldValue, Store.YES) | 字元串 | N | Y | Y/N | 字元串類型Field, 不分詞, 作為一個整體進行索引(如: 身份證號, 訂單編號), 是否需要存儲由Store.YES或Store.NO決定 |
| LongField(FieldName, FieldValue, Store.YES) | 數值型代表 | Y | Y | Y/N | Long數值型Field代表, 分詞並且索引(如: 價格), 是否需要存儲由Store.YES或Store.NO決定 |
| StoredField(FieldName, FieldValue) | 重載方法, 支持多種類型 | N | N | Y | 構建不同類型的Field, 不分詞, 不索引, 要存儲. (如: 商品圖片路徑) |
| TextField(FieldName, FieldValue, Store.NO) | 文本類型 | Y | Y | Y/N | 文本類型Field, 分詞並且索引, 是否需要存儲由Store.YES或Store.NO決定 |
3 常用的Field種類使用
3.1 準備環境
複製Lucene02-入門程式(Java API的簡單使用)中的lucene-first項目, 修改名稱為lucene-second;
修改pom.xml文件, 將所有的lucene-first修改為lucene-second.
3.2 需求分析
圖書id
是否分詞: 不需要分詞
是否索引: 需要索引(這裡可以索引, 也可以不索引)
是否存儲: 需要存儲
--> StringField
圖書名稱
是否分詞: 需要分詞
是否索引: 需要索引
是否存儲: 需要存儲
--> TextField
圖書價格
是否分詞: 需要分詞(Lucene對數值型的Field, 使用內部分詞)
是否索引: 需要索引
是否存儲: 需要存儲
--> FloatField
圖書圖片
是否分詞: 不需要分詞
是否索引: 不需要索引
是否存儲: 需要存儲
--> StoredField
圖書描述
是否分詞: 需要分詞
是否索引: 需要索引
是否存儲: 不需要存儲
--> TextField
3.3 修改代碼
public class IndexManager {
/**
* 創建索引功能的測試
* @throws Exception
*/
@Test
public void createIndex() throws IOException{
// 1. 採集數據
BookDao bookDao = new BookDaoImpl();
List<Book> books = bookDao.listAll();
// 2. 創建文檔對象
List<Document> documents = new ArrayList<Document>();
for (Book book : books) {
Document document = new Document();
// 給文檔對象添加域
// add方法: 把域添加到文檔對象中, field參數: 要添加的域
// TextField: 文本域, 屬性name:域的名稱, value:域的值, store:指定是否將域值保存到文檔中
// 圖書Id --> StringField
document.add(new StringField("bookId", book.getId() + "", Store.YES));
// 圖書名稱 --> TextField
document.add(new TextField("bookName", book.getBookname(), Store.YES));
// 圖書價格 --> FloatField
document.add(new FloatField("bookPrice", book.getPrice(), Store.YES));
// 圖書圖片 --> StoredField
document.add(new StoredField("bookPic", book.getPic()));
// 圖書描述 --> TextField
document.add(new TextField("bookDesc", book.getBookdesc(), Store.NO));
// 將文檔對象添加到文檔對象集合中
documents.add(document);
}
// 3. 創建分析器對象(Analyzer), 用於分詞
Analyzer analyzer = new StandardAnalyzer();
// 4. 創建索引配置對象(IndexWriterConfig), 用於配置Lucene
// 參數一:當前使用的Lucene版本, 參數二:分析器
IndexWriterConfig indexConfig = new IndexWriterConfig(Version.LUCENE_4_10_2, analyzer);
// 5. 創建索引庫目錄位置對象(Directory), 指定索引庫的存儲位置
File path = new File("/Users/healchow/Documents/index");
Directory directory = FSDirectory.open(path);
// 6. 創建索引寫入對象(IndexWriter), 將文檔對象寫入索引
IndexWriter indexWriter = new IndexWriter(directory, indexConfig);
// 7. 使用IndexWriter對象創建索引
for (Document doc : documents) {
// addDocement(doc): 將文檔對象寫入索引庫
indexWriter.addDocument(doc);
}
// 8. 釋放資源
indexWriter.close();
}
}3.4 重新建立索引
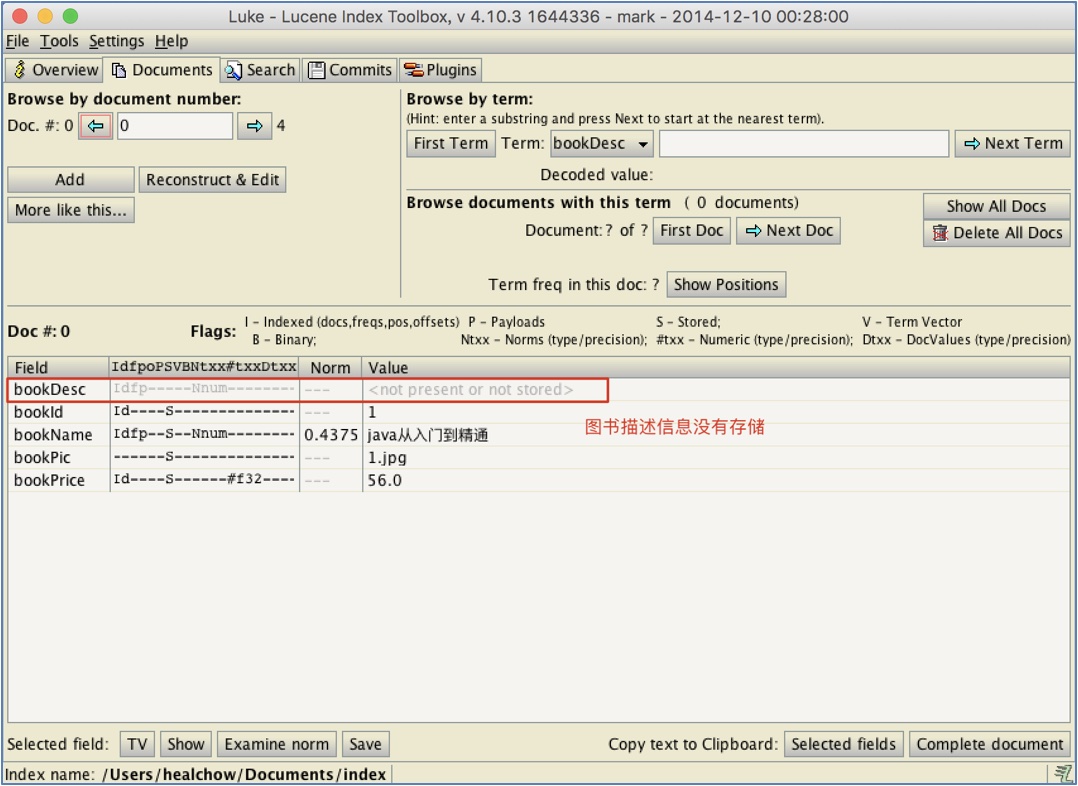
刪除之前建立的索引, 再次建立索引. 打開Luke工具查看索引信息, 可看到圖書圖片不分詞, 故沒有索引, 圖書價格使用了Lucene的內部分詞, 故按照UTF-8解碼後顯示亂碼, 如下圖示:

圖書的描述信息沒有存儲:
版權聲明
作者: ma_shoufeng(馬瘦風)
出處: 博客園 馬瘦風的博客
您的支持是對博主的極大鼓勵, 感謝您的閱讀.
本文版權歸博主所有, 歡迎轉載, 但未經博主同意必須保留此段聲明, 且在文章頁面明顯位置給出原文鏈接, 否則博主保留追究法律責任的權利.


