
本文通過大量圖片來分析和描述分庫、分表以及資料庫分區是怎樣進行的。 1.sharding前的初始數據分佈 在本文中,我打算用高考考生相關信息作為實驗數據。請無視表的欄位是否符合現實,也請無視表的設計是否符合範式。 3張表: 考生表,存放全國所有高考考生信息,假設34個省、(直轄)市、(自治區、特別行 ...
本文通過大量圖片來分析和描述分庫、分表以及資料庫分區是怎樣進行的。
1.sharding前的初始數據分佈
在本文中,我打算用高考考生相關信息作為實驗數據。請無視表的欄位是否符合現實,也請無視表的設計是否符合範式。
3張表:
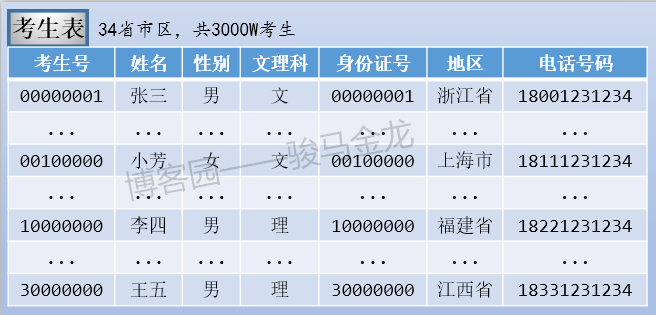
- 考生表,存放全國所有高考考生信息,假設34個省、(直轄)市、(自治區、特別行政)區共3000W考生
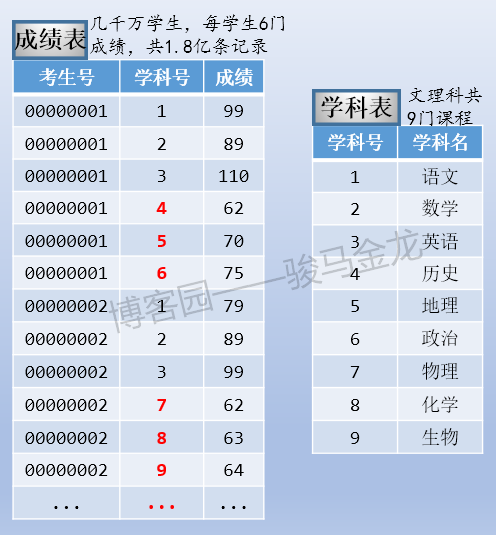
- 學科表,分文理科,共9門課程(語文、數學、英語、歷史、地理、政治、物理、化學、生物)
- 成績表,存過全國所有考生所有學科成績,每個學生6門成績,共1.8億條成績數據
三張表放在名為"gaokao_db"的庫中。所以,它們的結構如下:
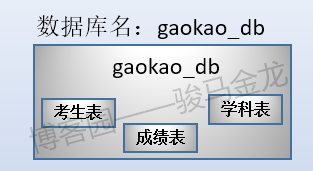
這三張表的大致存儲方式如下:
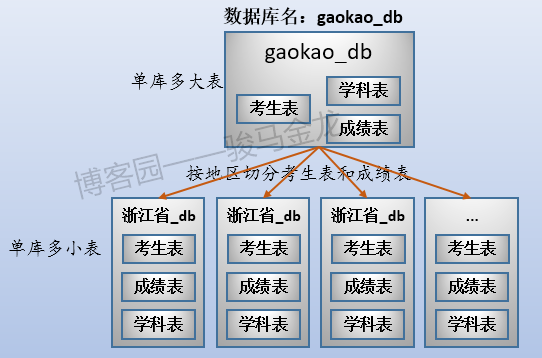
這個時候數據存儲方式是單庫多表。
2.業務分庫
業務分庫:按業務將不同表放進不同庫。每個庫可以放在不同資料庫伺服器上。
例如,在這裡將原始資料庫gaokao_db中的3個表分開放進兩個資料庫中,stu_db存放考生表,score_db存放成績表。
還有一張學科表放在哪呢?對於那些很小、無需進行切片的表,可以將多個這樣的表共同放在同一個庫中,也可以根據聯接特性將其分開放置在常與之進行聯接的庫中。在此處,學科表很小,沒必要單獨占用一個庫甚至資料庫伺服器,且由於學科表只會和成績表進行聯接,所以將其放在score_db庫中。
業務分庫如下圖:
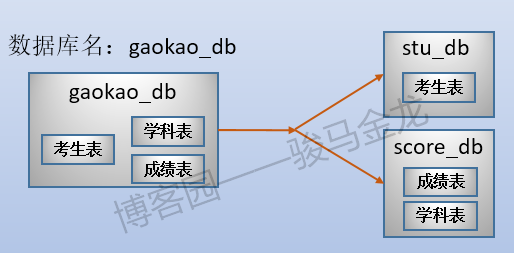
stu_db和score_db可以放在同一資料庫伺服器上,也可以放在不同資料庫伺服器上,從而在整體上減輕系統的壓力。但是,如果這兩個庫放在不同伺服器上,因為跨資料庫實例,將沒法對stu_db和score_db中的表進行join操作。
一般來說,對於可預見的、不斷增長的數據,業務分庫可能最先進行的sharding。
3.垂直切分
垂直切分:將一個表按照欄位分成多表,每個表存儲一部分欄位。表可以放在不同存儲設備上。
其實,在最初設計資料庫的時候,因為是關係型資料庫,或多或少都會去遵守一些設計範式。當設計的資料庫表滿足第一範式、第二範式、第三範式等等範式要求時,其實就已經進行了所謂的垂直切分。
即使按照範式設計了資料庫表,但有些表是寬表,有很多可能很少使用的欄位,這些欄位可能是按照稀疏列進行管理的,也可能是大BLOB後大text欄位。此外,表中的欄位還可以劃分為"熱門欄位和冷門欄位",例如本文示例中,相比考生號、姓名、所屬地區使用頻繁程度,考生電話號碼可能很少使用、身份證號也很少使用,所以這兩個欄位是冷門欄位。
所以,當表數據量很大時,即使滿足了範式要求,還是可以強行將表按欄位切開,將熱門欄位、冷門欄位分開放置在不同庫中,這些庫可以放在不同的存儲設備上,避免IO爭搶。
如下圖:
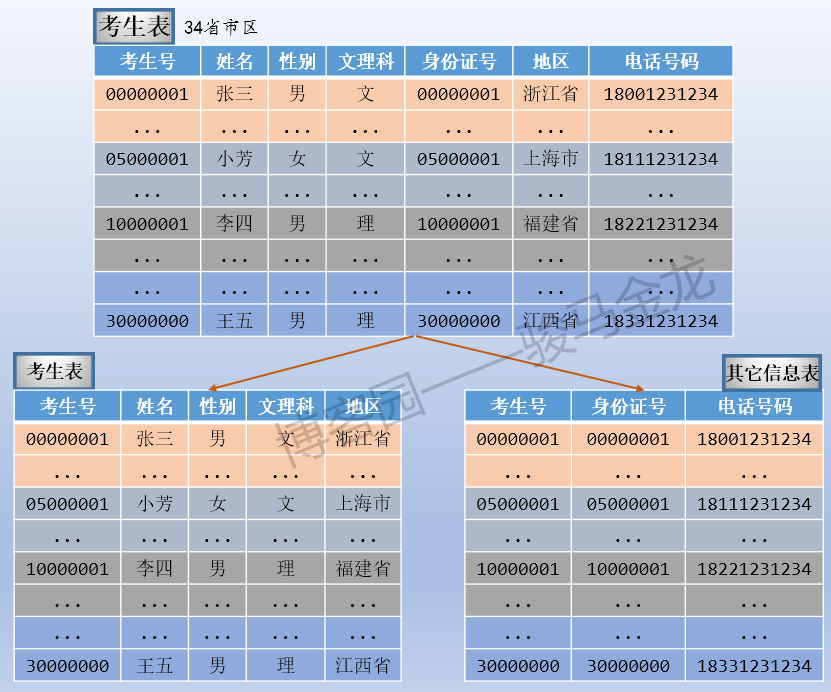
註意,垂直切分後的表,要能進行關聯,所以在此處的其它信息表中加上了考生號欄位。
垂直切分其實是更深一步的範式設計,或者反範式設計。垂直切分帶來的性能提升,主要集中在熱門數據的操作效率上,而且磁碟爭用情況減少。但如果想要將兩個表中的數據再次聯合起來,性能將比垂直切分前差的多。
另外,有很多人將業務分庫當作垂直切分,其實這都不重要,重要的是知道各種手段是幹嘛的。不過在本文以及我後面的文章,將認為業務分庫和垂直切分是不同sharding的分類。
4.水平切分
水平切分:將大表按條件切分到不同表中。每個表存儲一部分滿足條件的行。
水平切分通常有幾種常用的切分方式:
- 直接按欄位條件切分
- 取模後切分
- 按月份、季度、年份切分,或者稱之為按範圍切分
水平切分對性能提升非常大,不僅可以避開伺服器資源爭用,還減小了索引大小以及每個庫維護的表數據量。
4.1 按欄位條件進行切分
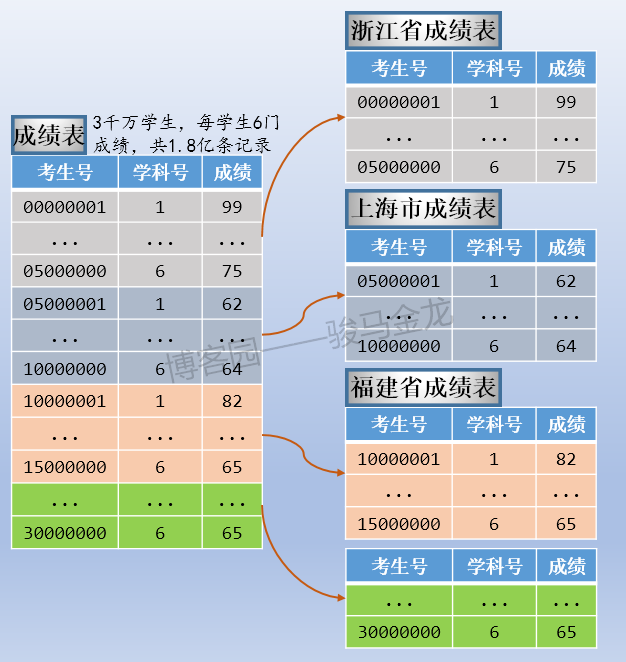
例如本文的示例中,按照考生所屬地區對考生表進行水平切分,這是按照欄位條件進行切分。
如下圖,因為有34個省、市、區,所以分成34個考生表,每個考生表都放在地區命名的庫中。各庫可放在同一資料庫伺服器,也可以放在不同資料庫伺服器。例如,某些省市區的考生數量少,可以將多個這樣的庫放在同一個資料庫伺服器上,而山東、江西等高考大省,因為考生數量多,可以單獨放在同一個資料庫伺服器上。
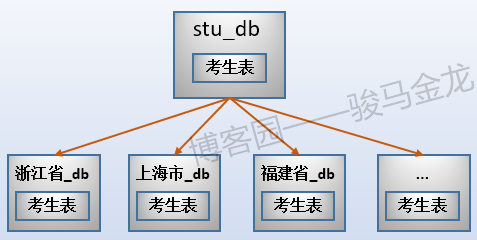
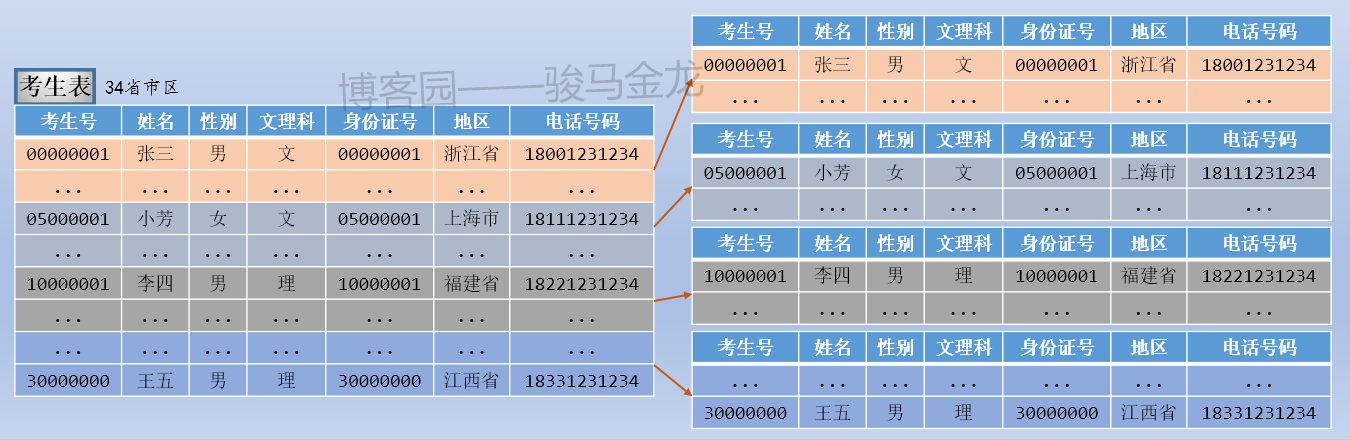
註意上述按欄位條件進行水平切分時,表名不變,創建新的按地區命名的庫,將各地區的表放置在對應的庫中。
通常,按照欄位條件進行水平卻分時,其它表也很有可能也按這個條件進行切分,使得滿足條件的表都放在同一個庫中,這樣能保證正常的join操作。
例如,上面切分了考生表,還可以切分成績表,讓同一個地區的考生表、成績表放在同一個庫中(所以,不能將考生表、成績表進行業務分庫)。
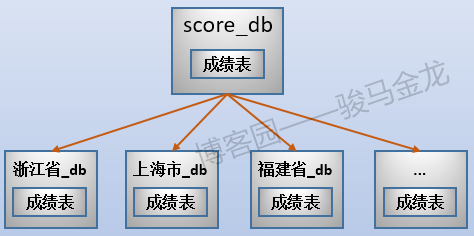
這樣切分後,整個數據的分佈情況如下:
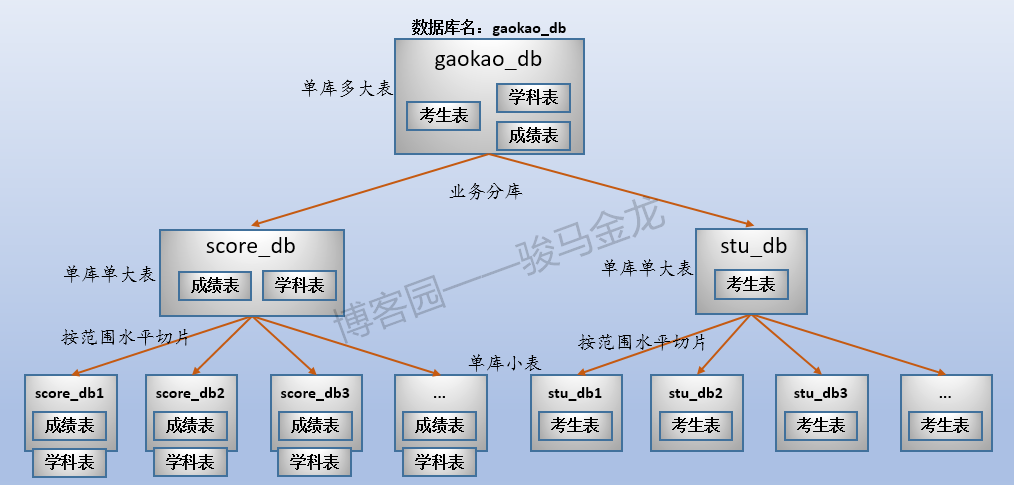
4.2 按範圍進行切分
對於上面的成績表,如果在此之前已經進行了業務分庫,就無法讓成績表、考生表同時按照地區進行水平切分。這時可以進行範圍切分,最常見的範圍切分是按月份、季度、年份進行切分。
例如,本文示例的成績表,可以按考生號範圍切片,可按考生號取模後切片,也可按學科類別切片。例如,按考生號範圍切片,每張表500W考生共3000W條成績數據,共切成6片。
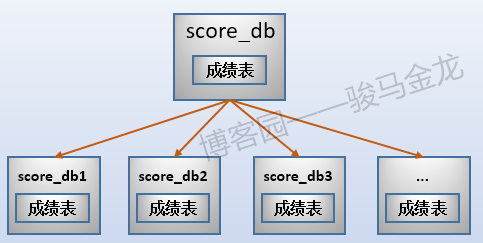
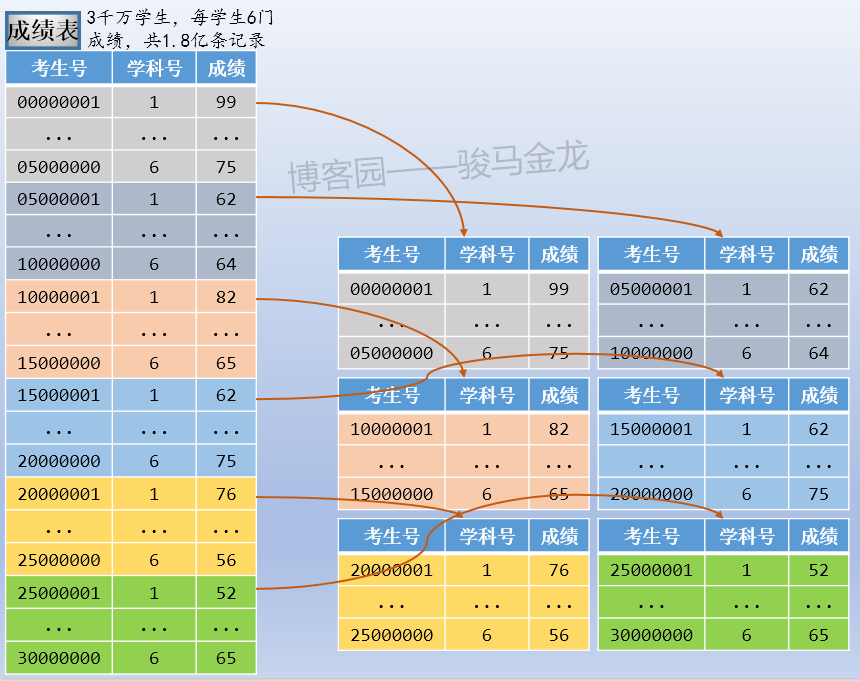
註意按照範圍(或者取模、年份、月份、季度等)切片後,資料庫的命名。這些庫可以放在同一個資料庫伺服器上,也可以放在不同資料庫伺服器上。
如果對成績表按照範圍(或者取模、年份、月份、季度等)切片後,最好對考生表也按照同樣的切分方式進行切片。舉個反例很容易理解,這裡的成績表按照範圍切分了,但是考生表按照地區切分,這兩類庫的名稱之間將失去對應關係,對於數據維護來說可能會增加很大的難度。
按照這種模式的水平切分後,整個數據的分佈情況如下(假設考生表也按範圍切片):
4.3 取模切分
取模是對數值或能轉換為數值的欄位進行取模,要切分成幾片,就除幾。
例如,按照取模切分的方式,將本文的考生表切分成6片。於是:
00000001 % 6 = 1 --> 放進stu_1庫
00000002 % 6 = 2 --> 放進stu_2庫
00000003 % 6 = 3 --> 放進stu_3庫
00000004 % 6 = 4 --> 放進stu_4庫
00000005 % 6 = 5 --> 放進stu_5庫
00000006 % 6 = 0 --> 放進stu_0庫
...
00000101 % 6 = 5 --> 放進stu_5庫
00000102 % 6 = 0 --> 放進stu_0庫
00000103 % 6 = 1 --> 放進stu_1庫
00000104 % 6 = 2 --> 放進stu_2庫
00000105 % 6 = 3 --> 放進stu_3庫
00000106 % 6 = 4 --> 放進stu_4庫
...註意,取模切片後的表名仍然為考生表,這些考生表放在對應的庫里,這些庫可以單獨放在一個資料庫伺服器上,也可以多個庫一起放在同一個資料庫伺服器上。
5.資料庫分區
資料庫分區:將大表進行分區,不同分區可以放置在不同存儲設備上,這些分區在邏輯上組成一個大表,對客戶端透明
- 分區方式和水平切片是類似的,分區方式也和水平切片方式類似,如範圍切片,取模切片等
- 資料庫分區是資料庫自身的特性,切片則是外部強制手段控制完成的
- 資料庫分區無法將分區跨庫,更不能跨資料庫伺服器,但能保存在不同數據文件從而放置在不同存儲設備上
- 資料庫分區是資料庫的特性,數據完整性、一致性等實現起來很方便,這一切都是資料庫自身保證的
例如,對考生表按照地區進行分區。
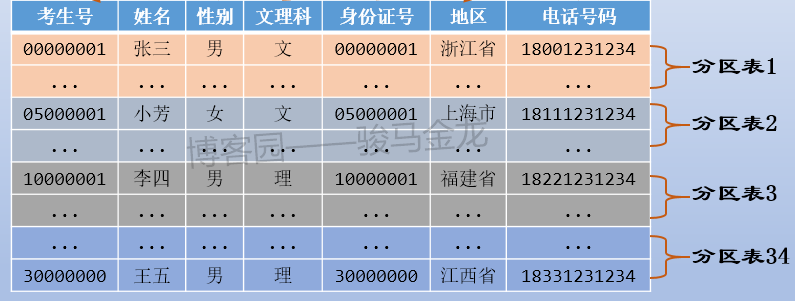
在資料庫切片流行之前,對大表的處理方式就是劃分分區表。資料庫分區相比於切片,最大的缺點在於無法跨庫、跨伺服器,所以在某些方面的壓力得到不緩解。
6.分庫、分錶帶來的問題
因為分庫、分表可以將大表切分成多個片段,每次檢索時可以只檢索一小個片段,且因為這些片段可以分開存放在不同存儲設備、不同資料庫伺服器上,它的整體性能得到了很大的提高。但是,隨之而來不少問題。最主要集中在以下幾個方面。
1.分庫分表本身的複雜性
分庫分表的方式可以在開髮端通過代碼來實現,也可以在app和資料庫中間使用中間件來實現(如mycat),還可以直接使用分散式資料庫(如TiDB、OceanBase)替代傳統關係型資料庫。無論是哪一種方案,學習成本、維護成本都有一段陣痛時期。
2.分庫分表讓資料庫系統架構變得複雜
特別是添加中間件的方式,畢竟在app和資料庫中間多了一層,這一層不能出現單點故障。
3.跨節點join問題
當進行了業務分庫,或者其它切片方式將庫放置在不同資料庫實例上時,因為跨了實例,將無法進行join操作。
4.擴容和數據遷移艱難
對於那些以範圍、取模方式做水平切分的大表,擴容以及擴容時的數據遷移很艱難。需要解決幾個問題:
- 擴容到多少節點比較滿足自己的期望。
- 擴容時,哪些數據需要從舊節點清洗掉,哪些數據需要從舊節點遷移到新節點。
- 如何實現線上遷移。
例如原本按照4個節點取模分片,現在出現了瓶頸,想要擴容成6個節點。
第一個問題,從4個節點擴容為6個節點,在整體上大致能提升50%的性能。
第二個問題和第三個問題。看如下數據分佈情況
擴容前 擴容後
0 % 4 = 0 0 % 6 = 0
1 % 4 = 1 1 % 6 = 1
2 % 4 = 2 2 % 6 = 2
3 % 4 = 3 3 % 6 = 3
4 % 4 = 0 4 % 6 = 4 -> 從0節點遷移到4節點
5 % 4 = 1 5 % 6 = 5 -> 從1節點遷移到5節點
6 % 4 = 2 6 % 6 = 0 -> 從2節點遷移到0節點
7 % 4 = 3 7 % 6 = 1 -> 從3節點遷移到1節點
8 % 4 = 0 8 % 6 = 2 -> 從0節點遷移到2節點
9 % 4 = 1 9 % 6 = 3 -> 從1節點遷移到3節點
10 % 4 = 2 10 % 6 = 4 -> 從2節點遷移到4節點
11 % 4 = 3 11 % 6 = 5 -> 從3節點遷移到5節點
12 % 4 = 0 12 % 6 = 0
13 % 4 = 1 13 % 6 = 1
14 % 4 = 2 14 % 6 = 2
15 % 4 = 3 15 % 6 = 3
16 % 4 = 0 16 % 6 = 4 -> 從0節點遷移到4節點可見,每12條數據就要從舊節點遷移8條數據,而且這8掉數據還是在各個節點之間交叉遷移。這使得數據遷移非常複雜,不是想加幾個節點就加幾個節點,讓擴容變得不再隨心所欲。一種比較好的解決方案是雙倍擴容,例如從4節點擴容為8節點。
擴容前 擴容後
0 % 4 = 0 0 % 8 = 0
1 % 4 = 1 1 % 8 = 1
2 % 4 = 2 2 % 8 = 2
3 % 4 = 3 3 % 8 = 3
4 % 4 = 0 4 % 8 = 4 -> 從0節點遷移到4節點
5 % 4 = 1 5 % 8 = 5 -> 從1節點遷移到5節點
6 % 4 = 2 6 % 8 = 6 -> 從2節點遷移到6節點
7 % 4 = 3 7 % 8 = 7 -> 從3節點遷移到7節點
8 % 4 = 0 8 % 8 = 0
9 % 4 = 1 9 % 8 = 1
10 % 4 = 2 10 % 8 = 2
11 % 4 = 3 11 % 8 = 3
12 % 4 = 0 12 % 8 = 4 -> 從0節點遷移到4節點
13 % 4 = 1 13 % 8 = 5 -> 從1節點遷移到5節點
14 % 4 = 2 14 % 8 = 6 -> 從2節點遷移到6節點
15 % 4 = 3 15 % 8 = 7 -> 從3節點遷移到7節點
16 % 4 = 0 16 % 8 = 0這樣每8條數據遷移4條,且需要遷移的數據不會在各節點之間交叉。這樣遷移要方便的的,而且性能提升100%。但是因為要遷移的數據量較大,遷移速度較慢,而且每次擴容都採取雙倍擴容,必須要考慮伺服器成本。
還有一種比較流行的"業務雙寫"遷移法。相比於雙倍擴容法,它仍然很複雜。它的遷移過程大概是這樣的:
- 加入新節點。
- 將業務寫入過程按照舊規則和新規則同時寫到新舊節點(業務雙寫)。例如4節點擴容到6節點時,id=2000的數據(假設之前沒有該數據)將同時寫入到0節點和2節點,id=2003將同時寫入3節點和5節點。
- 遷移舊數據。
- 應用新規則,將新節點向外提供服務。
- 清洗舊數據。
雙寫能保證遷移數據的過程仍然持續線上提供服務。但是,那些已存在的舊數據遷移仍然較為複雜,需要仔細琢磨要遷移哪些數據,以及遷移到哪個節點,這點必須把控好。


